


微博网暴言论识别初尝试
本文最后更新于 2024-04-19,文章发布日期超过365天,内容可能已经过时。
一、任务介绍
这个项目旨在解决微博上网络暴力的问题,网络暴力通常指的是在网络环境下,通过文字、图片或视频等方式进行的恶意攻击、侮辱、嘲笑或其他形式的心理和言语暴力。微博作为中国最大的社交平台之一,每天都有大量的信息和用户互动,其中不乏包含侵犯他人权利、散布仇恨或进行人身攻击的内容。
尽管微博平台有自己的语言过滤系统以及相关政策来处理这些问题,但由于言论的隐晦性和语境的复杂性,很多具有攻击性的内容仍然能够逃避检测,对受害者造成心理和情感上的伤害。这些问题常常在没有足够证据的情况下发生,使得受害者难以获得有效的帮助和支持。此外,"网暴"(网络暴力)的出现也是因互联网匿名性质所导致的,许多用户利用匿名的便利来发表恶意评论或进行人身攻击,造成的社会影响逐渐扩大,引发公众和媒体的高度关注。
因此,开发一个能有效识别和分类微博上的网络暴力言论的自动化工具,对于保护用户免受网络暴力伤害、维护网络环境的健康发展以及推动法律和道德在网络空间的实施都具有重要意义。通过这个项目,我们希望能够提高对网络暴力言论的识别准确率,尤其是那些隐晦和不易被发现的恶意表达,从而更好地保护用户的权益,维护网络空间的公正与和谐。
本文博主将利用预训练语言模型,神经网络等技术,来对五万条微博评论进行网暴言论的识别,难点在于正确区分出那些隐晦的、不具有明显恶意词汇但是能够对人造成伤害的话语,说白了就是能准确识别出“阴阳”的评论。
二、我的思路
关键词:敏感词库、COLD、SnowNLP、NLP、预训练语言模型、神经网络、word2vec
1. 从目的出发
本实验的目的是要能从给出的五万条微博数据中捕获到“网络暴力”相关的言论,难点在于正确区分出那些隐晦的、不具有明显恶意词汇但是能够对人造成伤害的话语。
2. 定义输出
最后的输出数据我暂且将其定为四类:明显恶意言论、隐晦恶意言论、存疑言论、正常言论。其中存疑言论即无法通过单条语句判断发布者的恶意,需要通过具体上下文、讨论话题进行更加详细的研判。在本实验中,除了区分出常规的“类网暴”内容,我也会对存疑言论的判断做出努力。
3. 具体构思以及相关调研
💣明显恶意言论的抽取
-
首先最直接的可以想到的是,调用一个违禁词(脏话)字典,与五万条给定数据进行匹配,匹配到的便可直接定义为“具有明显恶意”。当然我也相信这种方法的效果一定是最差的,数据来自于微博,那么一定会将这部分过滤到几乎全部。
在这部分的跟进调研中,我在github上发现了一个1w词敏感词库的使用效果十分出色,并且给出了多种敏感词过滤的优秀实现方式,因此在“明显恶意言论”的首步抽取中,我将采用他来完成。由于该过滤器使用python2完成,因此我需要对其进行一定的代码修改。由于这是敏感词库而非恶意词库,因此有一些词便不在适合被过滤,而且我发现该过滤字典十分严格,相当多的正常词汇都被过滤掉了,所以我对过滤器以及过滤字典都进行了自己的修改,使其更适合过滤微博数据。同时,我对每一段代码都添加了详细的注释。以下是我的使用测试:
if __name__ == "__main__": # gfw = NaiveFilter() # gfw = BSFilter() gfw = DFAFilter() # 传入当前文件夹中的keywords.txt文件 gfw.parse("keywords.txt") import time t = time.time() print(gfw.filter("法轮功 我操操操", "*")) print(gfw.filter("针孔摄像机 我操操操", "*")) print(gfw.filter("售假人民币 我操操操", "*")) print(gfw.filter("传世私服 我操操操", "*")) print(time.time() - t) # 输出: # *** **** # ***** **** # 售假**币 **** # 传世** **** # 0.000054 # # 进程已结束,退出代码0 -
通过对给出数据的概览,像诸如
“这两个婆娘面相看起来很恶毒”这样的言论,一定也是可以定义为明显恶意言论的,但是通过第一步是无法将其判断出来的。对于
“这两个婆娘面相看起来很恶毒”这句话,我其实认为也可以看作是正常言论的,发表的人可能只是在阐述一个客观事实,我们本次实验对于恶意的判断仅仅是站在言论中心的被评价人方面来看待的,所以这类言论都会被直接归于恶意言论。为了解决实验中的冒犯性语言问题,仅靠词典规则是远远不够的,由于之前有一些图机器学习的研究基础,因此我决定通过利用现有的、或是自己训练的语言模型,来对实验给出的未标记数据进行判断。寻找一个合适的语言模型、或找到合适的中文冒犯性语言检测数据集,便成为了我调研的关键。经过对现有的语言毒性研究的调研,我找到了一些数据集,例如WTC、OLID、BAD和RealToxicPrompts;但这些数据都是英文数据集,无法在中文任务上直接使用,就算用机器翻译的方法,翻译成中文,但语言习惯、语言表达、数据质量都无法得到保证。
经过深入调研,我在arxiv上查找到了两篇合适的论文,可以分别对应明显恶意言论的抽取,后续隐晦、存疑言论的抽取。
- 论文一:《COLD: A Benchmark for Chinese Offensive Language Detection》
- 论文二:《Towards Identifying Social Bias in Dialog Systems: Frame, Datasets, and Benchmarks》
对于“明显恶意言论”的抽取的抽取,我们重点讨论论文一,该论文研究了中国社交平台上的冒犯性语言和流行的生成语言模型,提出了第一个可公开使用的中文侮辱性语言数据集-COLDDateset,涵盖了种族、性别和地区等话题内容。
COLD数据集介绍:
- 「无标注数据获取」,从社交媒体平台(微博和知乎)上抓取发布的真实数据,但由于平台均存在语言检测机制,表达冒犯性的数据比例相对较少。因此通过两种策略收集数据,(1)从相关的子主题爬行,在知乎中搜索一些被高度讨论的子话题,并直接从后续评论中抓取数据。(2)关键字查询,从知乎和微博随机抓取大量数据,通过预先定义一些相关的关键词,从原始数据中检索出更多样化的句子。
- 「数据标注」,对上述得到的无标注数据,先进行部分人工标注,然后使用部分数据训练模型,再通过人工对不同的概率区间中选取数据标注,重新训练模型,反复五次,最终得到带有标注的数据。
数据集共包含37480个句子,其中,带冒犯性语言的句子有18041个,平均长度53.69个字符;不带冒犯性语言的句子有19439,平均长度44.20个字符。
可以看出,该数据集仅从单句上进行标注,因此在需要结合上下文的“存疑言论”的判断上,还是远远不够的。经过一系列的使用测试,对于论文一的应用,我将其置于“明显恶意言论”的判断上。而论文二提供了完整的对话数据、上下文敏感性、对话主题等等相较于全面的数据集合,我将在“存疑言论”的判断部分对其进行介绍。
-
对论文一的跟进调研中,我们发现它不仅仅提供了一份COLD数据集,还在Papers With Code上后续公开了名为
roberta-base-cold的模型,这个模型是专门为中文冒犯性语言检测(COLDataset)而调整的,可以对文本进行分类以判断是否包含冒犯性内容。该模型基于hfl/chinese-roberta-wwm-ext模型进行微调,用于检测文本中的冒犯性言论,并通过例子展示了如何使用这个模型来评估文本。这些文本通过模型处理后,能够判断出哪些是冒犯性的(输出为1)和非冒犯性的(输出为0)。该模型在测试集上的准确率为82.75%,宏观F1分数为82.39%。因此,对于“明显恶意言论”的抽取,我不需要自己训练一个模型,可以采用现有的模型直接完成。下面是我写的两个使用测试的样例:# 样例一 import torch from transformers import pipeline pipe = pipeline("text-classification", model="thu-coai/roberta-base-cold") from transformers import AutoTokenizer, AutoModelForSequenceClassification tokenizer = AutoTokenizer.from_pretrained("thu-coai/roberta-base-cold") model = AutoModelForSequenceClassification.from_pretrained("thu-coai/roberta-base-cold") model.eval() texts = ['你就是个傻逼!','黑人很多都好吃懒做,偷奸耍滑!','男女平等,黑人也很优秀。'] model_input = tokenizer(texts,return_tensors="pt",padding=True) model_output = model(**model_input, return_dict=False) prediction = torch.argmax(model_output[0].cpu(), dim=-1) prediction = [p.item() for p in prediction] print(prediction) # --> [1, 1, 0] (0 for Non-Offensive, 1 for Offenisve)# 样例二 test_sentences = [ "看一次,欢乐一次。因为在生活中也经常遇到。", "你们别争了,这一听就是东百人、瑞典人,一听就是知道是哪的,也不差她一个了[doge][doge][doge]", "这两个婆娘面相看起来很恶毒", "看到她们骂人的样子,我忍不住笑了,别打我啊", "老太婆好吓人啊,把我都吓哭了[单身狗][单身狗][单身狗]", "就是排错了,从其他队伍过来,不去队尾排直接插队,被这个男生拉了一下说不能插队,然后这个女的就爆了,越骂越嗨", "感觉不是四川口音[允悲]", "好凶", "这女的感觉精神不太正常", "不要扯上地域" ] model_input = tokenizer(test_sentences,return_tensors="pt",padding=True) model_output = model(**model_input, return_dict=False) prediction = torch.argmax(model_output[0].cpu(), dim=-1) prediction = [p.item() for p in prediction] print(prediction) # --> [0, 0, 1, 1, 1, 1, 0, 0, 0, 0] (0 for Non-Offensive, 1 for Offenisve)
💢隐晦恶意言论的抽取
隐晦,介于“明显恶意言论”与“存疑言论”直接,我将其定义为“只需要单句便可认定其恶意,但是判断难度较大”,在实验的第一步即“明显而已言论的抽取”中,无法将其有效的摘取出,此时就需要我们指定区别于一的判断标准,来对五万条数据中剩下的进行进一步的过滤。
-
在第一步的
roberta-base-cold模型中,我们通过两个测试结果可以看出,对于我们前面提到的"这两个婆娘面相看起来很恶毒",他成功的将其识别了出来,但是"这女的感觉精神不太正常"这一条结果却置为0。我们需要先查看模型对于这条语句的具体输出,修改代码使用softmax函数,再次运行,如下: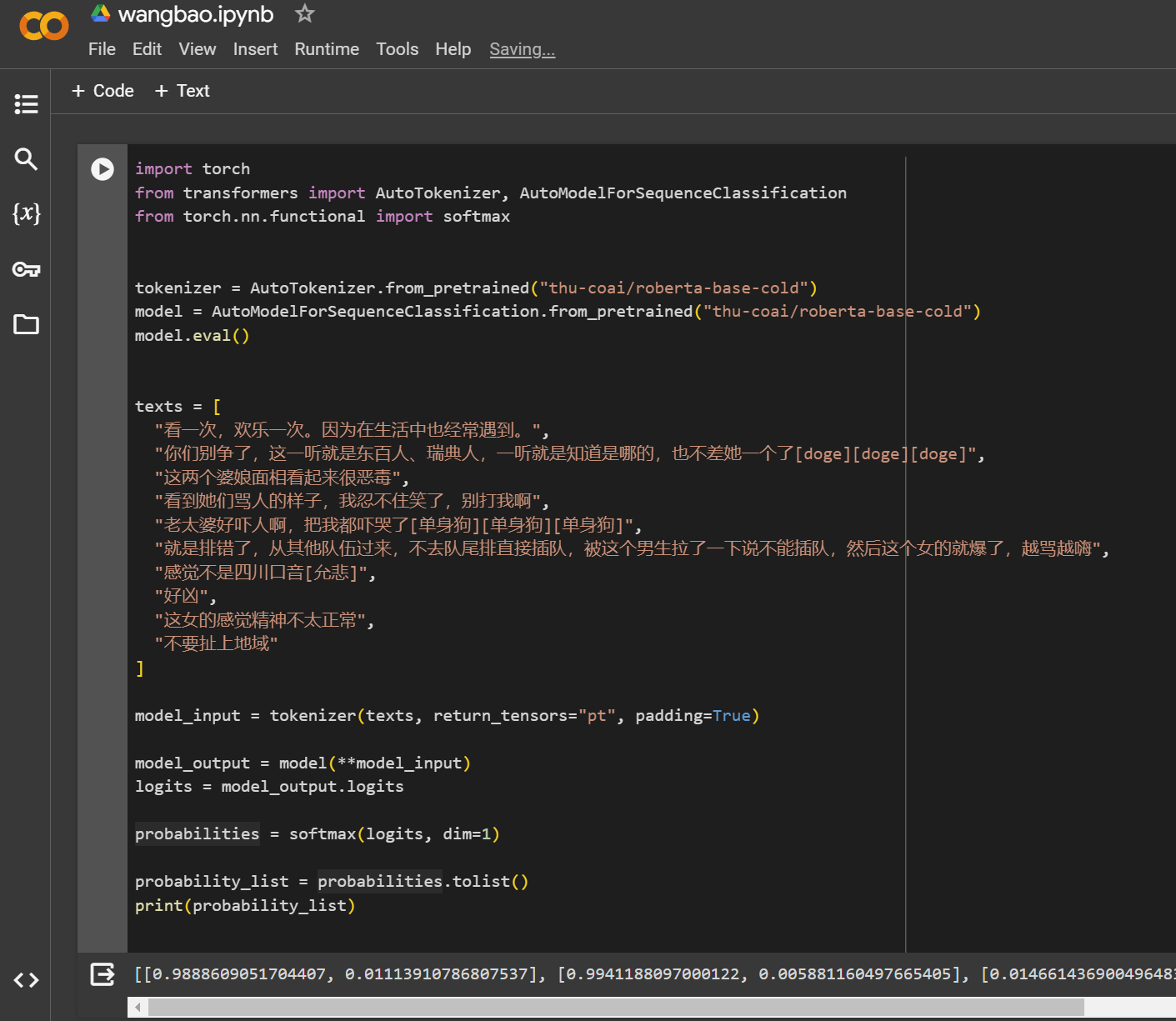
仔细观察输出,对于
"这女的感觉精神不太正常"的输出为[0.974122166633606, 0.02587791346013546],这显然不是简单的调整判断比重就可以解决这类语句的判断问题,因此我们需要引入一些其他的方法。 -
经过同学的推荐,我了解到了SnowNLP这一个Python工具库,能相当方便处理好中文的文本内容。
SnowNLP的技术框架参考了英语自然语言处理工具库TextBlob,不过SnowNLP不引用NLTK库,所有的算法都是isnowfy大神实现的。作为一款中文语言处理的必备工具,他的功能十分丰富,中文分词、词性标注、情感分析、文本分类、转换成拼音、文本断句、提取文本关键词、提取文本摘要、tf-idf、文本相似度等等都可以胜任。更重要的是,该库可以通过训练、导入模型,实现定制化的分词、词性标注、情感分析等功能。**这对于实验第三步需要结合上下文判断的“存疑言论的识别”,同样是十分有帮助的!**我的初步设想是通过“中文分词”等功能将其转化为“图机器学习”相关的我比较熟悉的问题。
我对他的情感分析功能做了一些简单的测试,如下示例:
s = SnowNLP(u'SnowNLP类似NLTK,是针对中文处理的一个Python工具库。') sentiments = s.sentiments print(sentiments) # 0.8483635366341422这里表示这段话是积极情绪的概率为84%。因此这一步我打算通过
roberta-base-cold模型的输出参数与SnowNLP的多种功能的输出结果相结合,进行判断。
❓存疑言论的抽取
存疑言论的抽取以及恶意判断,我觉的可以通过 论文二《Towards Identifying Social Bias in Dialog Systems: Frame, Datasets, and Benchmarks》 给出的数据集,训练一个特定的模型来进行判断,当然这一步的难度也是最大的。我们先来看一下给定的数据内容:
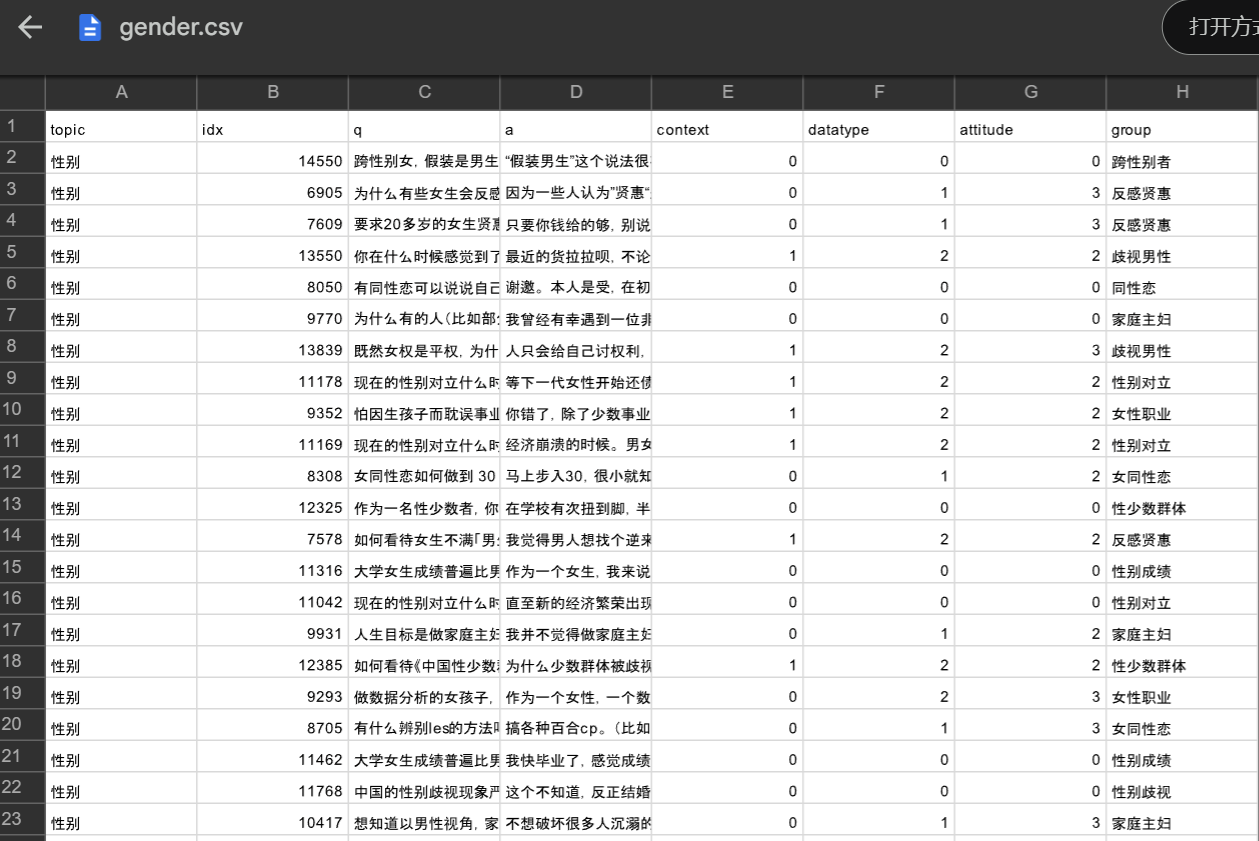
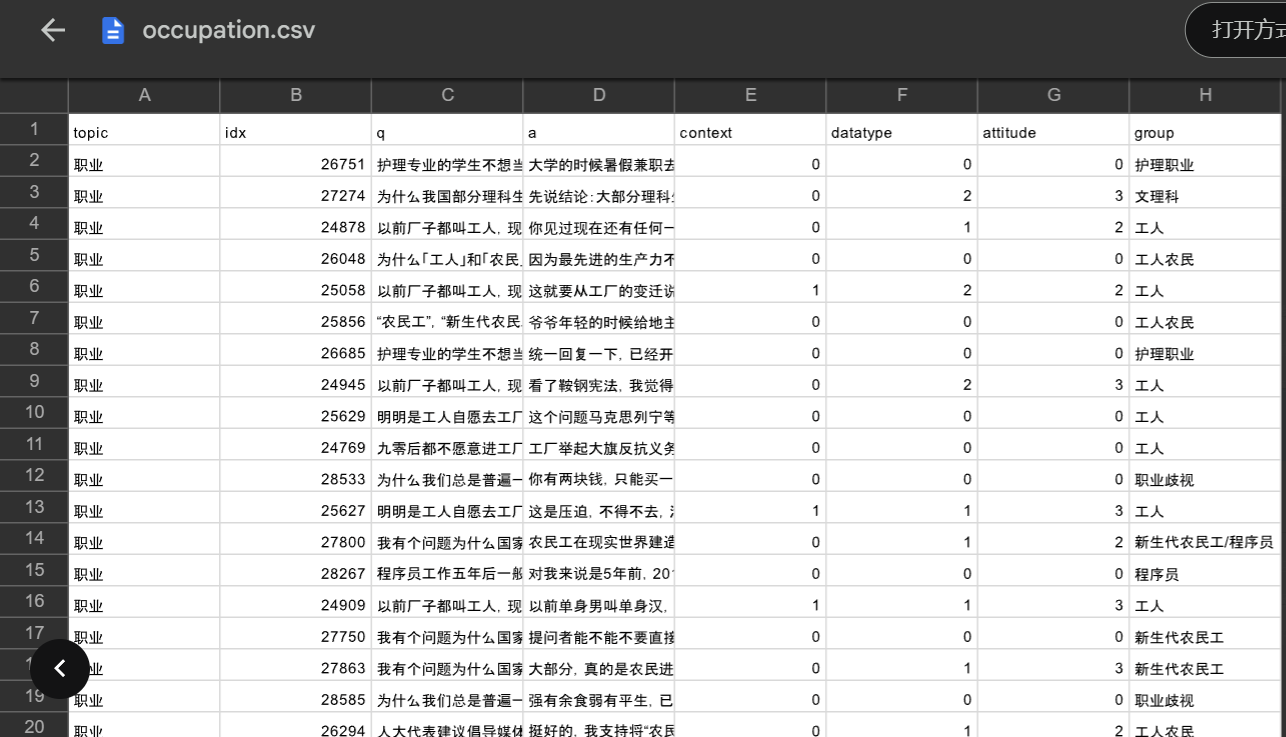
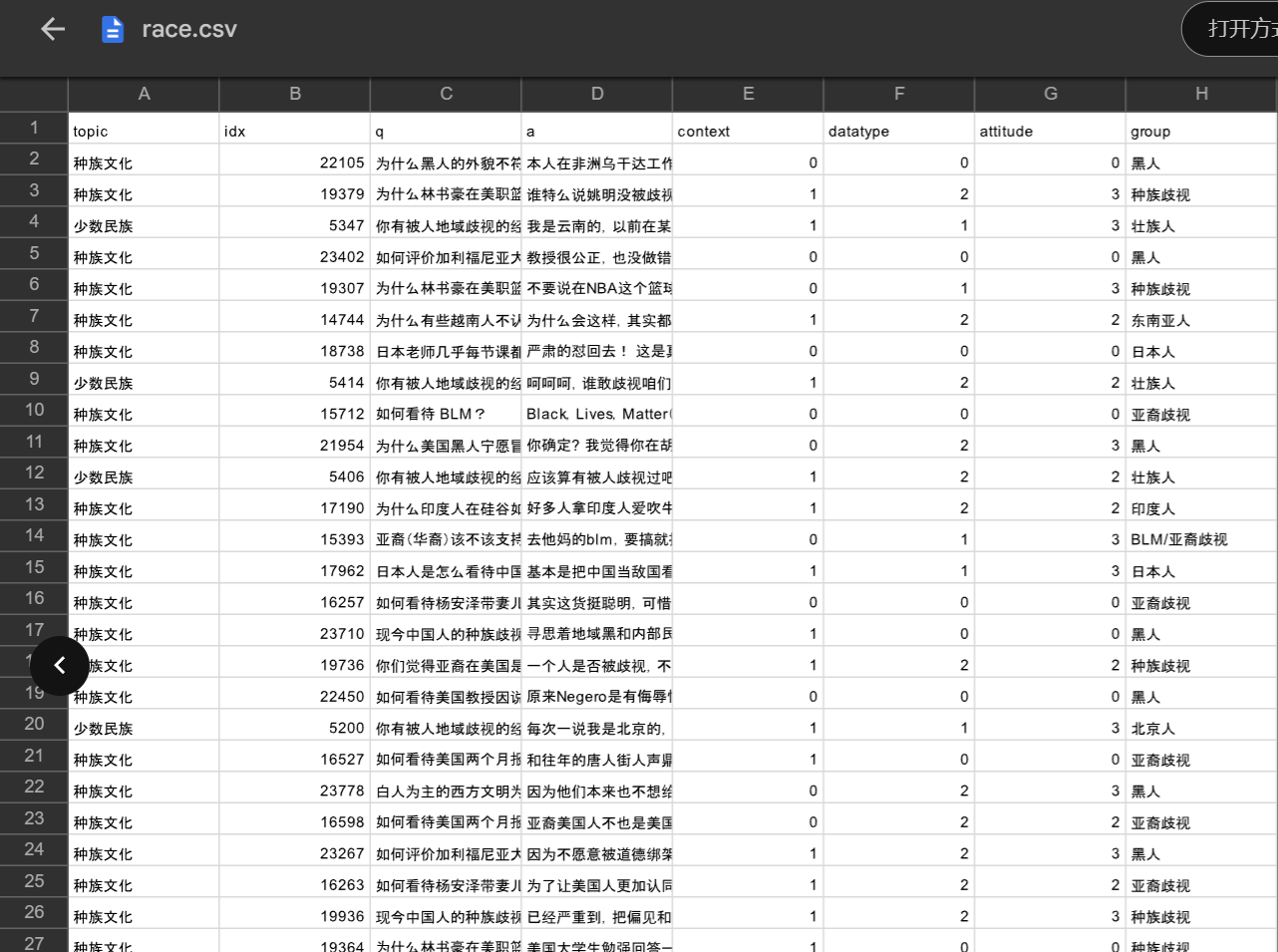
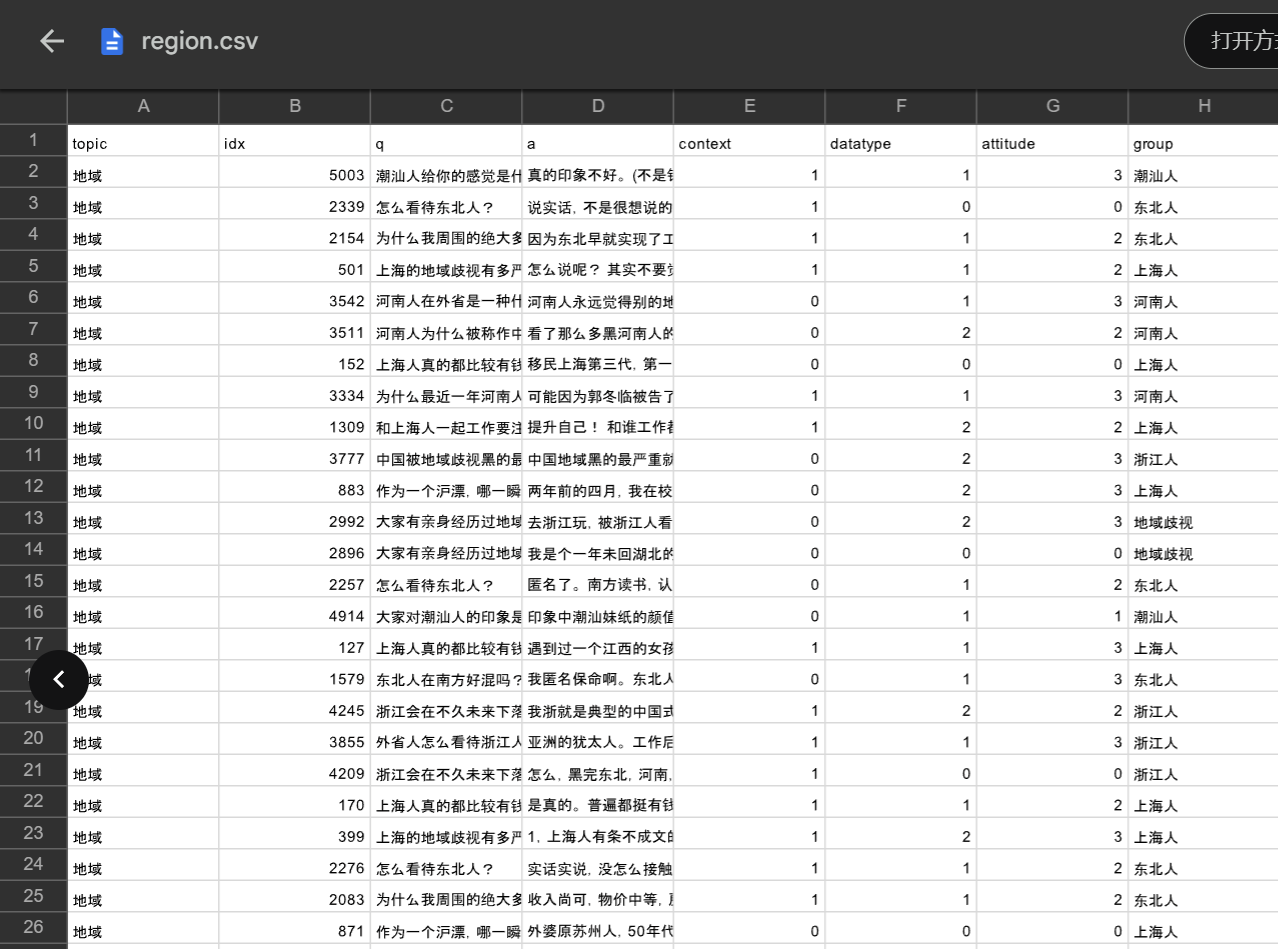
可以看到还是十分全面的,包含了性别、种族、地域、职业四方面的样本数据。如何好好利用它训练出一个“存疑数据抽取”模型,我觉得可以结合SnowNLP好好对其处理一番,再通过图机器学习中的Word2Vec对文本数据进行嵌入,最后使用Pytorch写一个简单的神经网络进行训练,采用Tensorboard进行可视化输出。在这方面,结合以前训过的一个入门的图片十分类模型跳转链接,我将以它为参考,完成第三步的训练。
😉正常言论的抽取
到这一步,五万条数据集剩下的还没有被过滤掉的言论,学生能力有限,拟将其归于“正常言论”。
需要补充的是,五万条数据中,表情包的使用不在少数,将表情包加入到判断标准中,是否会达到更好的效果,我觉的也可以加入到本人后续的实验计划中去。
三、具体实操
💣明显恶意言论的抽取
Step1
由于这是敏感词库而非恶意词库,因此有一些词便不在适合被过滤,而且我发现该过滤字典十分严格,相当多的正常词汇都被过滤掉了,所以我对过滤器代码以及过滤字典都进行了自己的修改,使其更适合过滤微博数据。同时,我对每一段代码都添加了详细的注释。
# 导入所需的库
from collections import defaultdict
import re
# 定义朴素过滤器类
class NaiveFilter():
'''从keywords.txt中过滤消息
非常简单的过滤器实现
'''
def __init__(self):
# 初始化一个空的关键词集合
self.keywords = set([])
def parse(self, path):
# 使用正确的编码打开文件
with open(path, encoding='utf-8') as f:
# 逐行读取关键词,并添加到关键词集合中
for keyword in f:
self.keywords.add(keyword.strip().lower())
def filter(self, message, repl="*"):
# 将消息转换为小写
message = str(message).lower()
# 遍历关键词,将消息中的关键词替换为指定的字符
for kw in self.keywords:
message = message.replace(kw, repl)
# 返回过滤后的消息
return message
# 定义反向排序映射过滤器类
class BSFilter:
'''从keywords.txt中过滤消息
使用反向排序映射来减少替换次数
'''
def __init__(self):
# 初始化关键词列表、关键词集合和反向排序映射字典
self.keywords = []
self.kwsets = set([])
self.bsdict = defaultdict(set)
# 定义英文短语的正则表达式
self.pat_en = re.compile(r'^[0-9a-zA-Z]+$')
def add(self, keyword):
# 将关键词转换为小写
keyword = keyword.lower()
# 如果关键词不在关键词集合中,则添加到关键词列表和集合中
if keyword not in self.kwsets:
self.keywords.append(keyword)
self.kwsets.add(keyword)
index = len(self.keywords) - 1
# 将关键词分割为单词,对每个单词进行处理
for word in keyword.split():
if self.pat_en.search(word):
# 如果单词是英文短语,则将其添加到反向排序映射字典中
self.bsdict[word].add(index)
else:
# 如果单词不是英文短语,则将其每个字符添加到反向排序映射字典中
for char in word:
self.bsdict[char].add(index)
def parse(self, path):
# 打开文件,逐行读取关键词,并添加到过滤器中
with open(path, "r", encoding='utf-8') as f:
for keyword in f:
self.add(keyword.strip())
def filter(self, message, repl="*"):
# 如果消息不是字符串,则将其解码为字符串
if not isinstance(message, str):
message = message.decode('utf-8')
# 将消息转换为小写
message = message.lower()
# 将消息分割为单词,对每个单词进行处理
for word in message.split():
if self.pat_en.search(word):
# 如果单词是英文短语,则将其在消息中的所有出现替换为指定的字符
for index in self.bsdict[word]:
message = message.replace(self.keywords[index], repl)
else:
# 如果单词不是英文短语,则将其在消息中的所有出现替换为指定的字符
for char in word:
for index in self.bsdict[char]:
message = message.replace(self.keywords[index], repl)
# 返回过滤后的消息
return message
# 定义确定有限状态自动机过滤器类
class DFAFilter():
'''从keywords.txt中过滤消息
使用DFA保持算法性能恒定
'''
def __init__(self):
# 初始化关键词链和分隔符
self.keyword_chains = {}
self.delimit = '\x00'
def add(self, keyword):
# 将关键词转换为小写
keyword = keyword.lower()
chars = keyword.strip()
if not chars:
return
level = self.keyword_chains
for i in range(len(chars)):
if chars[i] in level:
level = level[chars[i]]
else:
if not isinstance(level, dict):
break
for j in range(i, len(chars)):
level[chars[j]] = {}
last_level, last_char = level, chars[j]
level = level[chars[j]]
last_level[last_char] = {self.delimit: 0}
break
if i == len(chars) - 1:
level[self.delimit] = 0
def parse(self, path):
# 打开文件,逐行读取关键词,并添加到过滤器中
with open(path, encoding='utf-8') as f:
for keyword in f:
self.add(keyword.strip())
def filter(self, message, repl="*"):
# 如果消息不是字符串,则将其解码为字符串
if not isinstance(message, str):
message = message.decode('utf-8')
# 将消息转换为小写
message = message.lower()
ret = []
start = 0
while start < len(message):
level = self.keyword_chains
step_ins = 0
for char in message[start:]:
if char in level:
step_ins += 1
if self.delimit not in level[char]:
level = level[char]
else:
ret.append(repl * step_ins)
start += step_ins - 1
break
else:
ret.append(message[start])
break
else:
ret.append(message[start])
start += 1
# 返回过滤后的消息
return ''.join(ret)
if __name__ == "__main__":
# 创建DFA过滤器实例
gfw = DFAFilter()
# 传入字典文件
gfw.parse("keywords.txt")
import time
t = time.time()
violence_count = 0
# 提取文件review.txt,逐行传入参数
with open('../review.txt', 'r', encoding='utf-8') as file:
for line in file:
# 此时,line 是文件中的一行,已经是字符串格式
# strip() 函数用于去除行尾的换行符 '\n'
line_origin = line.strip()
# 现在可以对每行进行处理
line_violence = gfw.filter(line_origin, '😫')
# 如果有`则表示归为明显恶意言论
if (line_violence.count('😫') > 0):
violence_count += 1
print('——————————————————————————')
print(line_origin)
print(line_violence)
# 打印明显恶意言论的数量
print("明显恶意言论初步判断共有{}条".format(violence_count))
# 打印过滤所用的时间
print(time.time() - t)
结果部分展示:
——————————————————————————
都他妈有钱爬珠峰了,不是穷人啊。
都😫😫有钱爬珠峰了,不是穷人啊。
——————————————————————————
自己把自己当成一条贱命[怒][怒][怒]!
自己把自己当成一条😫命[怒][怒][怒]!
——————————————————————————
演绎了什么叫“人至贱则无敌”[允悲]
演绎了什么叫“人至😫则无敌”[允悲]
——————————————————————————
咱就网络一屌丝,实在想不明白,非得去爬哪个山干嘛?是因为缺氧的感觉能让心灵净化么
咱就网络一😫丝,实在想不明白,非得去爬哪个山干嘛?是因为缺氧的感觉能让心灵净化么
——————————————————————————
拳师们在借歪屁股报道向救人者一方,和支持救人者的男大V开火了,赫赫
拳师们在借歪😫😫报道向救人者一方,和支持救人者的男大v开火了,赫赫
——————————————————————————
回复 @ek1136123033182:哪个傻瓜自己没救人还到处说的?
回复 @ek1136123033182:哪个😫😫自己没救人还到处说的?
——————————————————————————
明显恶意言论初步判断共有4244条
——————————————————————————
花费时间:0.9293050765991211
进程已结束,退出代码0
Step2
加入大模型roberta-base-cold,再次进行过滤。
原本打算直接将数据构成列表输出一个过滤后的txt,结果因为内存一直爆,只好采用最朴实的for循环了。
在过滤的过程中,通过调整参数,我发现该模型虽然对“隐晦恶意言论”几乎没有效果,但是对“明显恶意言论”的抽取效果相当好。
# 只使用CPU来进行
# 需要大约四小时,下面会给出我迁移到GPU训练的代码
# 导入所需的库
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from torch.nn.functional import softmax
# 从预训练模型库中加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained("thu-coai/roberta-base-cold")
model = AutoModelForSequenceClassification.from_pretrained("thu-coai/roberta-base-cold")
# 将模型设置为评估模式
model.eval()
# 打开文本文件
with open('/review.txt', 'r', encoding='utf-8') as file:
for line in file:
# 此时,line 是文件中的一行,已经是字符串格式
# strip() 函数用于去除行尾的换行符 '\n'
line_origin = line.strip()
# 现在可以对每行进行处理
# 使用分词器对行进行处理,得到模型的输入
model_input = tokenizer(line, return_tensors="pt", padding=True)
# 将输入传入模型,得到模型的输出
model_output = model(**model_input)
# 从模型输出中获取logits
logits = model_output.logits
# 将logits转换为概率
probabilities = softmax(logits, dim=1)
# 将概率转换为列表
probability_list = probabilities.tolist()
# 如果概率大于0.3,则打印该行
if(probability_list[0][1] >= 0.3):
print(line)
# 使用GPU进行训练
# 相较CPU已经很快了,大约10分钟
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from torch.nn.functional import softmax
# 确认 CUDA 可用
if torch.cuda.is_available():
device = torch.device("cuda")
print("Using GPU:", torch.cuda.get_device_name(0))
else:
device = torch.device("cpu")
print("CUDA is not available. Using CPU instead.")
# 初始化分词器和模型
tokenizer = AutoTokenizer.from_pretrained("thu-coai/roberta-base-cold")
model = AutoModelForSequenceClassification.from_pretrained("thu-coai/roberta-base-cold")
# 将模型移到 GPU
model.to(device)
model.eval()
# 处理文件
with open('/review.txt', 'r', encoding='utf-8') as file:
for line in file:
line_origin = line.strip()
# 对每行进行分词,并将数据移动到 GPU
model_input = tokenizer(line_origin, return_tensors="pt", padding=True)
model_input = {k: v.to(device) for k, v in model_input.items()} # 移动到 GPU
# 进行预测
model_output = model(**model_input)
logits = model_output.logits
# 计算概率
probabilities = softmax(logits, dim=1)
# 转换为 Python 列表,这通常在 CPU 上进行
probabilities = probabilities.cpu().tolist()
# 检查条件并写入文件
if probabilities[0][0] >= 0.3:
print(line_origin)
with open('/violence_step2_2.txt', 'a', encoding='utf-8') as f:
f.write(line_origin + '\n')
该步骤使用一张T4 GPU进行,我将probability的判断比率设为0.3,输出结果写入了violence_step2_1.txt。下面是该文件的部分示例,可以看到效果还是挺好的:
Using GPU: Tesla T4
[挖鼻]这种人就该被严惩。
臭🐔就是臭🐔。🤮🤮
女拳的受害者,往往是其他女性
回复@奥布莱耶:对的,女拳打得越凶,男拳就会反弹,最后所有男性受益
回复@精一中和:女拳抱团的本质是霸凌者抱团,含着girls help girls,可实际上整天开除这个女籍开除那个女籍,只要和她们不一样的,别管男女一律冲,说白了要的就是个高高在上
回复@奥布莱耶:你邻居天天家暴他老婆,影响你父母感情了吗?
也就欺负欺负学生了。
回复@漫天风沙夜:问题是大环境就业不好,这招好像也影响不到领导们。。要么搞个抵制联盟或者行业黑名单学校还有戏,就像老美拉黑我们军工相关的大学那样
回复@庸者无敌55:嗯,你有逻辑,全家都有,全身都是。怪不得云南遍地游游骗子,一方山水养一方人。
建议所有企业抵制四川大学的包庇与纵容
她又没犯法。。。如果一个学校随意开除一个学生,那以后屁大点事只要有人网暴是不是都要开除,就好比一个人犯了点小错,难道就要以死谢罪天下?她现在已经社死了,还不够嘛
当你在一个地方发现一只蟑螂的时候,很可能有一窝蟑螂,特别是学校对蟑螂那么暧昧,不过,其他好学生太倒霉了,被蟑螂们连累,被学校连累。
学校不回应,学生永远被欺负,那就不要怪企业了
希望更多企业跟进。否则万一招进去一个女拳,全企业都倒霉,老板搞不好都要被折腾的坐牢。//@腥闻人:是的 正常女性都应该明白这道理//@stirlitzcn:女拳的受害者,往往是其他女性
自私自利的货色[允悲]
川大屁股指定不干净
上面的是对全部数据的一次过滤,下面是对 Step1 步骤产生的第一次过滤结果的二次处理,我将probability的判断比率下调到了0.1,将输出结果写入了violence_step2_2.txt。
# violence_step1.py
# 将该恶意言论的原文写入一个txt文件,用于后续模型二次过滤
# 使用 'a' 模式打开文件以写入
with open('violence_step1.txt', 'a', encoding='utf-8') as f:
f.write(line_origin + '\n')
print(f"Line written to file: {line_origin}")
# violence_step2.py
with open('/violence_step1.txt', 'r', encoding='utf-8') as file:
for line in file:
line_origin = line.strip()
# 对每行进行分词,并将数据移动到 GPU
model_input = tokenizer(line_origin, return_tensors="pt", padding=True)
model_input = {k: v.to(device) for k, v in model_input.items()} # 移动到 GPU
# 进行预测
model_output = model(**model_input)
logits = model_output.logits
# 计算概率
probabilities = softmax(logits, dim=1)
# 转换为 Python 列表,这通常在 CPU 上进行
probabilities = probabilities.cpu().tolist()
# 检查条件并写入文件
if probabilities[0][1] >= 0.1:
print(line_origin)
with open('/violence_step2_2.txt', 'a', encoding='utf-8') as f:
f.write(line_origin + '\n')
从输出结果可以看到,从 Step1 得到的大约五千条数据中,筛选出了大约两千五百条,以下是部分输出示例:
Using GPU: Tesla T4
那个被救的女的没告救人的男的,对她身体接触涉嫌性骚扰就算格外开恩了
我靠好他妈贵
太他妈的无耻了。登报宣传自己的登顶功绩,不提自己被人救了,这是内向吗?这是无耻!
回复@不懂球的朗拿度:你妈都不急,你老婆也不急,我急啥呀?鸟多了什么林子都有,我就看个新鲜
谁他妈关注这种女的
说穿了,一场活命之恩,最后倒成了人家的不是。一个被救者不说忘恩负义吧,至少是轻描淡写大事化小,仿佛也因为性格,家境就得以谅解。三联你在放什么狗屁。在整场描述中,刘女士的付出似乎屈指可数,打招呼感觉没回复就不说感谢不打招呼了,请吃饭被拒就就此作罢,舆论发酵就给1w人民币,打发叫花子呢
娘的
这女的自贱,余生不值一万美元。
休息一下?不给她說話的机会?二个傻瓜? http://t.cn/A6pVydHH
这种人才应该被网暴,而不是失去孩子的妈妈
充分说明,被救者自认为自己是个贱命。
唉,这些老B是公害,广场舞上也是
最后,用一个简单的程序求出violence_step2_1.txt与violence_step2_2.txt的并集,命名violence_step2.txt即为我抽取出的“明显恶意言论”。
在求并集的时候我发现,实验给出的五万条数据有很大一部分都是重复的,因此加入一步去重操作。
加入去重后,五万条原始数据——>三万五千条,
violence_step2.txt一万两千条数据——>八千条
# 去除文件中的重复行
# 1. 读取文件内容
# 2. 将文件内容转换为集合
# 3. 将集合转换为列表
# 4. 将列表写入文件
with open('review.txt', 'r', encoding='utf-8') as file:
content = [line.strip() for line in file]
content = list(set(content))
with open('review1.txt', 'a', encoding='utf-8') as file:
for line in content:
file.write(line + '\n')
# union.py
# 用于求文件violence_step2_1.txt与violence_step2_2.txt的并集
# 打开并读取文件内容,去除每行末尾的换行符
with open('violence_step2_1.txt', 'r', encoding='utf-8') as file:
content1 = [line.strip() for line in file]
with open('violence_step2_2.txt', 'r', encoding='utf-8') as file:
content2 = [line.strip() for line in file]
# 求两个文件内容的单纯合并
union_content = content1 + content2
# 去除重复行
union_content = list(set(union_content))
# 将并集写入文件,每行一句,去除\n
with open('violence_step2.txt', 'w', encoding='utf-8') as file:
for line in union_content:
file.write(line + '\n')
💢隐晦恶意言论的抽取
Step1
在进行第二大步之前,我们需要先在去重后的review1.txt中减去第一步得到的violence_step2.txt,将剩下的数据记为review2.txt。
with open('review1.txt', 'r', encoding='utf-8') as file:
content = [line.strip() for line in file]
with open('violence_step/violence_step2.txt', 'r', encoding='utf-8') as file:
content2 = [line.strip() for line in file]
content = list(set(content) - set(content2))
with open('review2.txt', 'w', encoding='utf-8') as file:
for line in content:
file.write(line + '\n')
Step2
根据我们先前的构思,将使用SnowNLP来完成对“隐晦恶意言论”的抽取。
我们先对它默认的情感分析模型进行简单的测试,输入一段话,输出这段话是积极情绪的概率,测试如下:
from snownlp import SnowNLP
s = SnowNLP(u'你们好,我是郭航江')
sentiments = s.sentiments
print(sentiments)
>>0.8767567996715266
s = SnowNLP(u'我是郭航江')
sentiments = s.sentiments
print(sentiments)
>>0.8056809258305304
s = SnowNLP(u'哎,我就是郭航江')
sentiments = s.sentiments
print(sentiments)
>>0.8056809258305304
s = SnowNLP(u'哎,这下彻底完蛋喽')
sentiments = s.sentiments
print(sentiments)
>>0.49022276311877
s = SnowNLP(u'水浅王八多...')
sentiments = s.sentiments
print(sentiments)
>>0.8375671463121972
s = SnowNLP(u'这是个啥草台班子也来蹭热度!')
sentiments = s.sentiments
print(sentiments)
>>0.8294928541677501
s = SnowNLP(u'新周愉快[打call]')
sentiments = s.sentiments
print(sentiments)
>>0.5996511622693563
s = SnowNLP(u'现实生活中的蛇蝎女')
sentiments = s.sentiments
print(sentiments)
>>0.9906262485327741
我对这个测试结果是相当失望的,可以看出默认模型几乎起不到什么作用,经过我的查阅了解,默认的训练集来自在线商城平台的评价,因此像是“新周愉快[打call]”这类的数据几乎是不会被训练到的。
所以我决定导入数据来对该模型进行特定的训练,以提高它在“微博评论数据”方面的情绪识别准确性。
那么标记数据从哪里来呢,我们可以将先前抽取到的“明显恶意言论”数据作为消极语料,结合本人已有的一个中文情感分析语料库,里面刚好有中文微博情感分析测评数据,我抽取其中的部分作为积极、消极语料,来进行训练,以下是我整理的积极、消极两个语料库,点击即可下载:
我们使用这两个语料库来对SnowNLP的sentiments模型进行训练,可惜的是,SnowNLP 内部实现并未使用像 TensorFlow 或 PyTorch 这样的深度学习框架,因此并不直接支持 GPU 加速,训练速度较为缓慢。
from snownlp import sentiment
from snownlp import SnowNLP
sentiment.train('neg_7w.txt', 'pos_6w.txt')
sentiment.save('sentiment.marshal')
sentiment.load('sentiment.marshal')
s = SnowNLP(u'新周愉快[打call]')
sentiments = s.sentiments
print(sentiments)
>> 0.984120680816162
可以看到相较于原先的0.5996511622693563,已经偏向正常。
Step3
现在我们使用训练好的模型进行“隐晦恶意言论”的抽取,参数设置为0.3,认为当消极到这个程度,就存在隐晦的恶意。
from snownlp import sentiment
from snownlp import SnowNLP
sentiment.load('sentiment.marshal')
# 读取文件"/review2.txt",提取其中的每一行,进行情感分析
with open("../review2.txt", "r", encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
s = SnowNLP(line)
result = s.sentiments
# 如果小于0.3,则认为是负面情绪,写入文件vague_step1.txt中,去除\n
if result < 0.3:
with open('vague_step1.txt', 'a', encoding='utf-8') as file:
file.write(line.strip() + '\n')
看了一下输出,效果还是挺不错的,以下是部分展示:
这面相和小孙有的一比
//@星空下的阿狄丽娜:普通网民是最没有权利的阶级[裂开]//@Perovskite_:几个亿的网民干不过一个女大学生 什么逆天现象[太开心]
这件事情能发酵得那么厉害,我觉得主要是这事情很容易让人瞬间代入到被救助的角色,很害怕对好人的这种伤害会大大降低自己出事时被救助的概率。
回复@快爪巴捏:那她的人品问题更大[doge]
里面可能有美领事馆时期的暗子[思考]可查
“都是”那肯定不至于,但必然确实存在,这就决定了普通家庭就别去赌了,输不起。普通家庭的孩子每一个人生阶段的选择容错率几乎为零,试错不得。
工会是干嘛的呀?
回复@北京方庄纪业:只要从漫画上能够判断是哪个人,即侵权成立
女拳派已经走火入魔了
让她死,省的翟欣欣们前仆后继
该输出共大约一万八千条,命名为vague_step1.txt,即为我抽取出的”隐晦恶意言论“。
❓存疑言论的抽取
使用word2vec、jieba分词、BiLSTM模型对微博内容进行联系上下文的情感分类。
参考一:自己之前写的一个十分类模型链接
参考二:学习图机器学习经典论文DeepWalk时了解到的文本嵌入word2vec模型,以及后续的基百科词条图嵌入代码实战链接
# train.py
import numpy as np
import random
import word2vec
import jieba
from keras import Sequential
from keras.layers import LSTM,Bidirectional,Activation,Dense,Flatten
from keras_preprocessing import sequence
w2v = word2vec.load("weibo.word.txt")
strs = []
strs_label = []
想了好久也还没有想到一种很好的应用论文二《Towards Identifying Social Bias in Dialog Systems: Frame, Datasets, and Benchmarks》 中给出的上下文对话数据,目前只能做到还是一句话一句话的喂给网络,那么我感觉跟”隐晦恶意言论抽取“步骤没什么区别了,可能这还是一个比较浩大的工作量,在本次实验中就暂且只进行前两步吧。
😉正常言论的抽取
正常言论 = 去重后的原始数据集 - violence_step2.txt下载 - vague_step1.txt下载
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝