


一段手写数字的识别
本文最后更新于 2024-07-01,文章发布日期超过365天,内容可能已经过时。
关键词:深度学习、神经网络、Pytorch、OpenCV
一、单个手写数字的识别
步骤一:模型设计
1. 初始模型设计
因为数字有0、1、2、3、4、5、6、7、8、9,所以我们可以把他当作是一个图片十分类任务来处理,因此我结合之前已有的学习基础,设计了一个如下的模型来完成这个任务:
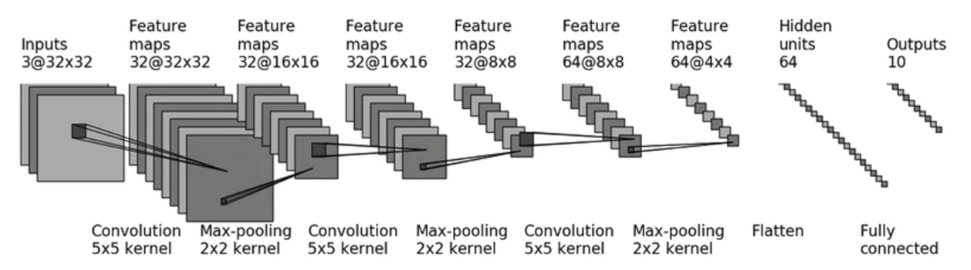
这个模型是一个典型的卷积神经网络(CNN),原本是被用来处理CIFAR-10数据集。该模型包含多层卷积层、池化层、展平层和全连接层。至于具体参数例如输入尺寸、卷积核大小、维度等参数,可以根据手写数字的数据集来做具体调整,使其更加符合本次实验的要求。
下面我将对这个模型的每一层做一个简单的介绍:
- 输入层:
- 输入的图像尺寸为 3x32x32(3 表示 RGB 三个通道,32x32 表示图像尺寸)。
- 当然在本次任务中,这个尺寸可能会变化,我将在后续进行说明。
- 第一层卷积层:
- 32 个 5x5 卷积核,步幅为 1,填充为 2。
- 输出特征图尺寸:32x32x32。
- 第一层池化层:
- 2x2 最大池化层,步幅为 2。
- 输出特征图尺寸:32x16x16。
- 第二层卷积层:
- 32 个 5x5 卷积核,步幅为 1,填充为 2。
- 输出特征图尺寸:32x16x16。
- 第二层池化层:
- 2x2 最大池化层,步幅为 2。
- 输出特征图尺寸:32x8x8。
- 第三层卷积层:
- 64 个 5x5 卷积核,步幅为 1,填充为 2。
- 输出特征图尺寸:64x8x8。
- 第三层池化层:
- 2x2 最大池化层,步幅为 2。
- 输出特征图尺寸:64x4x4。
- 展平层:
- 将多维的特征图展平成一维向量。
- 输出向量长度:1024。
- 全连接层1:
- 线性层,输入维度 1024,输出维度 64。
- 全连接层2:
- 线性层,输入维度 64,输出维度 10。
- 最后的张量对应十个数字,做一个归一化,每个维度的值反应了他识别为这个数字的概率。
下面是使用pytorch实现这个模型,我定义了一个类,他继承了nn.model,并提供了常见的两种写法,最后进行了正确性的测试以及可视化输出:
# 用于构建CIFAR10的模型,如上图所示
# 顺便介绍sequential的用法
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class GuoHangJiang(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 不引入sequential的写法
# 第一层卷积部分
# 每一步卷积的padding与stride都需要靠计算得出
self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2)
# 第二层池化部分
self.maxpool1 = MaxPool2d(kernel_size=2)
# 第三层卷积部分
self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2)
# 第四层池化部分
self.maxpool2 = MaxPool2d(kernel_size=2)
# 第五层卷积部分
self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2)
# 第六层池化部分
self.maxpool3 = MaxPool2d(kernel_size=2)
# 第七层展平部分
self.flatten = Flatten()
# 第八层线性层
# 图片中少了一层介绍,仔细观察
self.linear1 = Linear(in_features=1024, out_features=64)
# 第九层线性层
self.linear2 = Linear(in_features=64, out_features=10)
# 引入sequential的写法
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10)
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model1(x)
return x
ghj = GuoHangJiang()
print(ghj)
# 用于测试模型是否正确
input = torch.ones(64, 3, 32, 32)
output = ghj(input)
print(output.shape)
# 除了print可以用来可视化,tensorboard也可以用来可视化
writer = SummaryWriter('logs_seq')
writer.add_graph(ghj, input)
writer.close()
我们运行一下看一下图片张量在这个模型中是怎样变化的:
(pytorch) PS D:\Python\learn_pytorch> & C:/Users/67093/.conda/envs/pytorch/python.exe d:/Python/learn_pytorch/ShuziShibie.py
GuoHangJiang(
(model1): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])
整个流程是非常的清晰且直观的,用来解决手写数字的识别问题绰绰有余。
2. 针对手写数字识别的模型改进
在本次任务中,我将选用MNIST数据集,它是一个包含手写数字的广泛使用的数据集,非常适合用来进行图像分类任务。MNIST数据集包括60,000张训练图像和10,000张测试图像,每张图像都是28x28像素的灰度图像,并且标签为0到9的数字。
要将原本适用于CIFAR-10数据集的模型设计改为适用于MNIST数据集,需要做以下调整:
- 输入通道数由3改为1,因为MNIST是灰度图像。
- 输入图像尺寸由32x32改为28x28,因为MNIST图像尺寸是28x28。
以下是改进的模型代码:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class GuoHangJiang(nn.Module):
def __init__(self):
super(GuoHangJiang, self).__init__()
# 使用sequential的写法
self.model1 = Sequential(
Conv2d(in_channels=1, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=64*3*3, out_features=64),
Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model1(x)
return x
ghj = GuoHangJiang()
print(ghj)
# 用于测试模型是否正确
input = torch.ones(64, 1, 28, 28)
output = ghj(input)
print(output.shape)
# 除了print可以用来可视化,tensorboard也可以用来可视化
writer = SummaryWriter('logs_seq')
writer.add_graph(ghj, input)
writer.close()
测试结果:
(pytorch) PS D:\Python\learn_pytorch> & C:/Users/67093/.conda/envs/pytorch/python.exe d:/Python/learn_pytorch/ShouXieShiBie.py
GuoHangJiang(
(model1): Sequential(
(0): Conv2d(1, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=576, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])
下面是代码运行实例截图:
步骤二:模型可视化训练
我们引入上一步设计的模型,对其进行训练,下面是我对其完整训练流程的介绍:
1. 数据准备
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch import nn
from torch.utils.tensorboard import SummaryWriter
# 加载MNIST数据集并进行预处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_data = torchvision.datasets.MNIST(root='dataset', train=True, transform=transform, download=True)
test_data = torchvision.datasets.MNIST(root='dataset', train=False, transform=transform, download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{},测试数据集的长度为:{}".format(train_data_size, test_data_size))
train_dataloader = DataLoader(train_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=False)
这部分代码加载MNIST数据集,并应用了标准化变换。transforms.Normalize((0.5,), (0.5,)) 将图像数据标准化到均值为0.5、标准差为0.5。数据加载器(DataLoader)用于将数据分批次加载到训练和测试中。
2. 模型定义
# 搭建神经网络
# 借鉴之前写过的一个MNIST模型
from model import GuoHangJiang
# 创建网络模型
ghj = GuoHangJiang()
这一部分导入并实例化了之前定义的神经网络模型 GuoHangJiang。
3. 损失函数和优化器
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
# 创建优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(ghj.parameters(), lr=learning_rate)
这部分代码创建了交叉熵损失函数和随机梯度下降(SGD)优化器。学习率设置为0.01。
4. 训练参数和TensorBoard
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard可视化
writer = SummaryWriter("logs_train")
这里设置了训练过程中的一些参数,包括总训练步数、总测试步数和训练轮数。还使用TensorBoard记录训练过程中的损失,以便可视化。
5. 训练和测试过程
for i in range(epoch):
print("----------第{}轮训练开始----------".format(i + 1))
ghj.train()
for data in train_dataloader:
imgs, targets = data
outputs = ghj(imgs)
loss = loss_fn(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
writer.add_scalar("train_loss", loss.item(), total_train_step)
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
ghj.eval()
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = ghj(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
total_test_step += 1
torch.save(ghj, "ghj_{}.pth".format(i + 1))
print("第{}轮训练结束,模型已保存".format(i + 1))
writer.close()
这部分代码进行模型训练和测试:
- 每轮训练开始时,打印当前轮数。
- 设置模型为训练模式 (
ghj.train())。 - 遍历训练数据进行前向传播、计算损失、反向传播和参数更新。
- 每训练100次打印一次训练损失。
- 设置模型为评估模式 (
ghj.eval())。 - 禁用梯度计算 (
with torch.no_grad()),遍历测试数据计算总测试损失。 - 打印整体测试集上的损失。
- 保存当前训练轮次的模型参数。
- 关闭TensorBoard写入器。
6. 训练结果展示
下面是运行的时的部分输出展示:
(pytorch) PS D:\Python\learn_pytorch> & C:/Users/67093/.conda/envs/pytorch/python.exe d:/Python/learn_pytorch/ShouXieShiBie_train.py
训练数据集的长度为:60000,测试数据集的长度为:10000
GuoHangJiang(
(model1): Sequential(
(0): Conv2d(1, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=576, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])
----------第1轮训练开始----------
训练次数:100, Loss:2.150526762008667
训练次数:200, Loss:1.1308094263076782
训练次数:300, Loss:0.6747239828109741
训练次数:400, Loss:0.3342771828174591
训练次数:500, Loss:0.23235106468200684
训练次数:600, Loss:0.4987734258174896
训练次数:700, Loss:0.35505443811416626
训练次数:800, Loss:0.27889004349708557
训练次数:900, Loss:0.3870258927345276
整体测试集上的Loss:26.561247029341757
第1轮训练结束,模型已保存
----------第2轮训练开始----------
训练次数:1000, Loss:0.27520230412483215
训练次数:1100, Loss:0.04403237998485565
训练次数:1200, Loss:0.12688487768173218
训练次数:1300, Loss:0.15233315527439117
训练次数:1400, Loss:0.1719307005405426
训练次数:1500, Loss:0.18218977749347687
训练次数:1600, Loss:0.13730388879776
训练次数:1700, Loss:0.07805894315242767
训练次数:1800, Loss:0.27868708968162537
整体测试集上的Loss:14.277361426735297
第2轮训练结束,模型已保存
----------第3轮训练开始----------
训练次数:1900, Loss:0.051657937467098236
训练次数:2000, Loss:0.08964638411998749
可以发现训练速度较慢,于是我们对代码进行小修改,使用GPU进行训练。
7. 使用GPU进行训练
以下是使用GPU进行训练的完整代码,我们还添加了正确率的计算:
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch import nn
from torch.utils.tensorboard import SummaryWriter
# 检查是否有可用的GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if device.type == 'cuda':
print(f"使用的GPU是: {torch.cuda.get_device_name(0)}")
else:
print("没有可用的GPU,使用CPU")
# 加载MNIST数据集并进行预处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_data = torchvision.datasets.MNIST(root='dataset', train=True, transform=transform, download=True)
test_data = torchvision.datasets.MNIST(root='dataset', train=False, transform=transform, download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{},测试数据集的长度为:{}".format(train_data_size, test_data_size))
train_dataloader = DataLoader(train_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=False)
# 搭建神经网络
from ShouXieShiBie_model import GuoHangJiang
# 创建网络模型
ghj = GuoHangJiang()
# 将模型转移到GPU
guj = ghj.to(device)
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 创建优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(ghj.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
total_train_step = 0
total_test_step = 0
epoch = 30
# 添加tensorboard可视化
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("----------第{}轮训练开始----------".format(i + 1))
ghj.train()
for data in train_dataloader:
imgs, targets = data
# 将数据转移到GPU
imgs, targets = imgs.to(device), targets.to(device)
outputs = ghj(imgs)
loss = loss_fn(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
writer.add_scalar("train_loss", loss.item(), total_train_step)
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
ghj.eval()
total_test_loss = 0
total_accuracy = 0 # 为了计算整体测试集上的准确率,需要记录预测正确的样本数量
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
# 将数据转移到GPU
imgs, targets = imgs.to(device), targets.to(device)
outputs = ghj(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
# 计算当前批次的准确率,具体计算方法见test.py的解释以及对应的视频链接
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step += 1
torch.save(ghj, "ghj_{}.pth".format(i + 1))
print("第{}轮训练结束,模型已保存".format(i + 1))
writer.close()
我们进行30轮训练,下面是部分输出展示:
pytorch) PS D:\Python\learn_pytorch> & C:/Users/67093/.conda/envs/pytorch/python.exe d:/Python/learn_pytorch/ShouXieShiBie_train_GPU.py
使用的GPU是: NVIDIA GeForce RTX 3070 Laptop GPU
训练数据集的长度为:60000,测试数据集的长度为:10000
GuoHangJiang(
(model1): Sequential(
(0): Conv2d(1, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=576, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])
----------第1轮训练开始----------
训练次数:100, Loss:2.0744383335113525
训练次数:200, Loss:0.9707316756248474
训练次数:300, Loss:0.5561598539352417
训练次数:400, Loss:0.3622879683971405
训练次数:500, Loss:0.44760021567344666
训练次数:600, Loss:0.18201066553592682
训练次数:700, Loss:0.09421295672655106
训练次数:800, Loss:0.26845136284828186
训练次数:900, Loss:0.15463638305664062
整体测试集上的Loss:31.788333610631526
整体测试集上的正确率:0.9311999678611755
第1轮训练结束,模型已保存
----------第2轮训练开始----------
训练次数:1000, Loss:0.09018311649560928
训练次数:1100, Loss:0.16740190982818604
训练次数:1200, Loss:0.09253757447004318
训练次数:1300, Loss:0.3073056638240814
训练次数:1400, Loss:0.2571570873260498
训练次数:1500, Loss:0.12080878019332886
训练次数:1600, Loss:0.3311219811439514
训练次数:1700, Loss:0.22441141307353973
训练次数:1800, Loss:0.033919304609298706
整体测试集上的Loss:16.8317426412832
整体测试集上的正确率:0.9659000039100647
第2轮训练结束,模型已保存
----------第3轮训练开始----------
训练次数:1900, Loss:0.02228640764951706
训练次数:2000, Loss:0.11637557297945023
训练次数:2100, Loss:0.06177337095141411
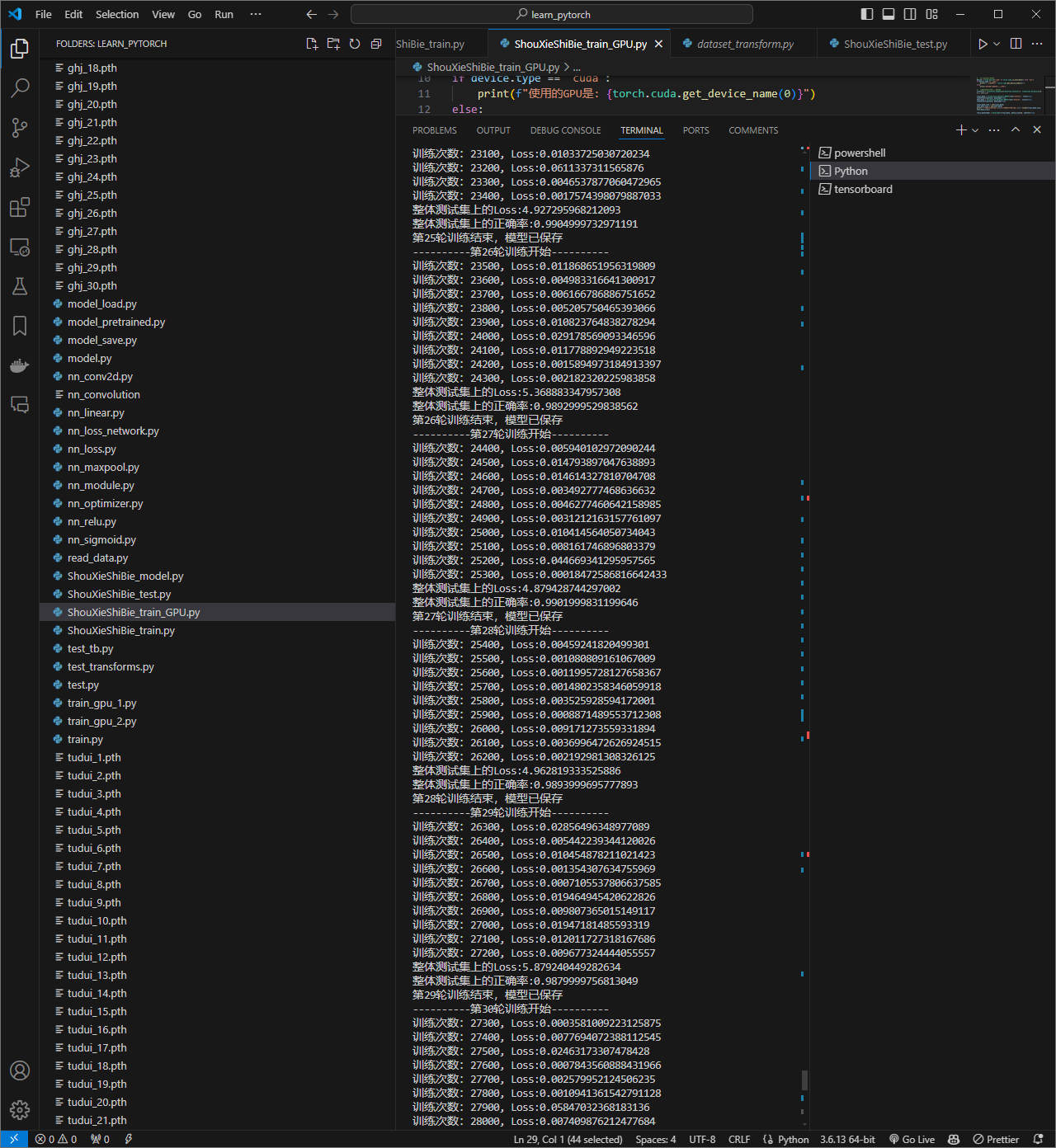
8. 训练可视化及结果查询
我们打开tensorboard查看训练的可视化过程如下:
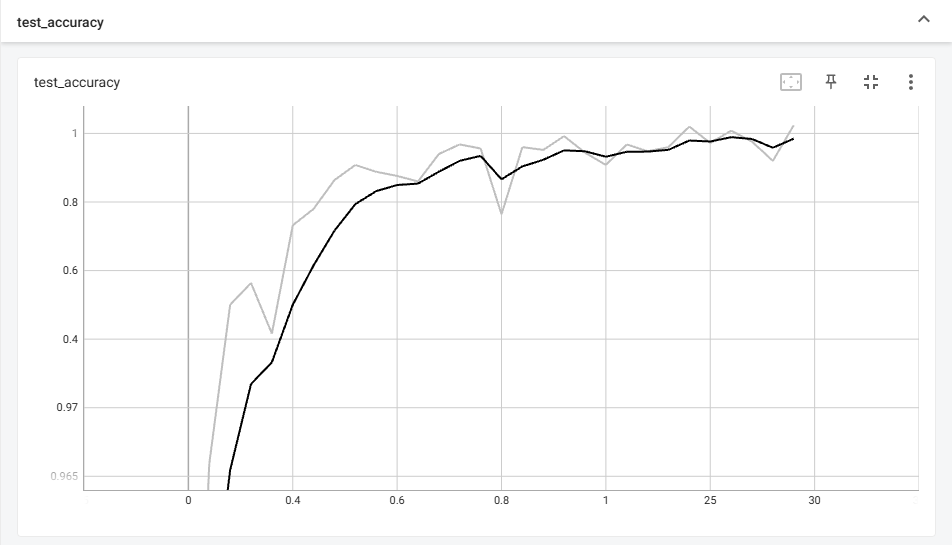

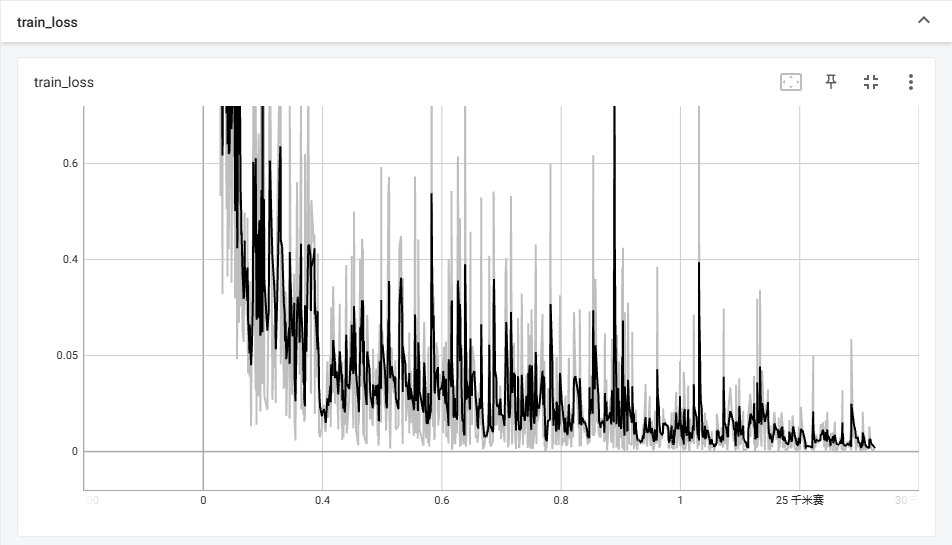
上一步中我们存储了每次训练好的模型(如下),我们讲使用第30轮的模型来完成实验的后续部分。
下面是代码实录:
步骤三:模型测试
我们取用第30轮的模型参数,给出一张手写图片来进行测试,图片如下:
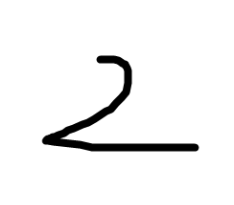
我们给出下面的测试代码,看模型能否识别这个为数字2:
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "./imgs/shuzi2.png"
# 打开是PIL类型
image = Image.open(image_path).convert('L') # 转换为灰度图像
print(image)
# 为了适应我们的模型,需要对图片进行预处理
transform = torchvision.transforms.Compose(
[torchvision.transforms.Resize((28, 28)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5,), (0.5,))]
)
image = transform(image)
print(image.shape)
# 加载网络模型
from ShouXieShiBie_model import GuoHangJiang
# 如果模型原来是使用gpu训练的,这时候就需要告诉电脑使用cpu进行测试,要不然会报错
model = torch.load("ghj_30.pth", map_location=torch.device('cpu'))
print(model)
# 要求输入的image是一个四维的,但现在是torch.Size([1, 28, 28]),少了一个batch size的维度
image = torch.reshape(image, (1, 1, 28, 28))
# 下面这几行不要忘记了,养成一个良好的代码习惯
model.eval()
with torch.no_grad():
output = model(image)
print(output)
# 告知当前是哪个数字
print("预测的结果为:{}".format(torch.argmax(output, 1).item()))
发现识别错误:
tensor([[-0.7378, -3.9288, 3.1303, 5.3542, -2.3251, -1.9398, 0.1089, -7.0653,
10.1833, -2.1943]])
预测的结果为:8
问题描述
我们把诸如下面的1-9的数字都测试一遍,发现都识别为8,8的张量特别的大!!

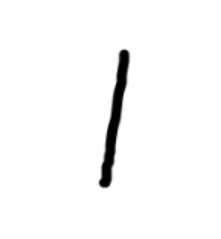
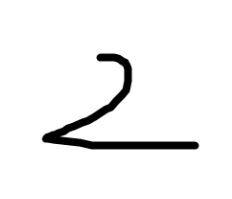

问题解决
经过我的分析发现,mnist数据集使用的样本都是黑色背景,白色数字。
而我们做测试、实际用起来,肯定都是白色背景,黑色数字,所以模型就会把白色的背景部分当作是数字,我们简单考虑以下,去掉数字以后剩下的背景确实是跟8最相近的!
为了验证我们的猜想,我们使用一张黑色背景白色数字的图片来做测试如下:
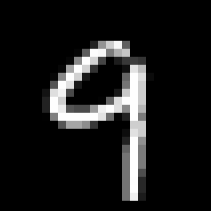
tensor([[-10.6956, -4.9937, -5.2039, -0.2524, 10.5677, -2.5184, -16.6606,
5.5232, -0.6070, 19.9935]])
预测的结果为:9
可以看到问题迎刃而解!并且9对应的张量非常大,效果非常好!
那么如何彻底解决这个问题呢,我们只需要在代码的
image = Image.open(image_path).convert('L') # 转换为灰度图像
这个部分加一个颜色黑白反转即可!
image = Image.open(image_path).convert('L') # 转换为灰度图像
# 黑白反转
image = torchvision.transforms.functional.invert(image)
然后再进行测试,输入黑字1,结果如下:
tensor([[ 1.7799, 10.0625, -0.3011, -3.6549, -0.6460, -4.5650, -0.0875, 1.8749,
-2.2461, -1.0116]])
预测的结果为:1
现在,我们就彻底完成了单个手写数字的识别!
步骤四:封装模型
将上述代码封装成一个函数,接受一张图片的路径,返回预测的数字:
import torch
import torchvision
from PIL import Image
from torch import nn
def predict_digit(image_path):
# 打开图片并转换为灰度图像
image = Image.open(image_path).convert('L')
# 黑白反转
image = torchvision.transforms.functional.invert(image)
# 预处理图片
transform = torchvision.transforms.Compose(
[torchvision.transforms.Resize((28, 28)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5,), (0.5,))]
)
image = transform(image)
# 加载预训练模型
from ShouXieShiBie_model import GuoHangJiang
model = torch.load("ghj_30.pth", map_location=torch.device('cpu'))
# 添加batch size维度
image = torch.reshape(image, (1, 1, 28, 28))
# 预测
model.eval()
with torch.no_grad():
output = model(image)
# 返回预测结果
return torch.argmax(output, 1).item()
# 使用示例
image_path = "./imgs/shuzi1.png"
predicted_digit = predict_digit(image_path)
print("预测的结果为:{}".format(predicted_digit))
(pytorch) PS D:\Python\learn_pytorch> & C:/Users/67093/.conda/envs/pytorch/python.exe d:/Python/learn_pytorch/ShouXieShiBie_function.py
预测的结果为:1
二、一段手写数字的识别
步骤一:图片分割
目标:能将不止一行的数字大图分割成一个数字一个小图,譬如我们使用下面一幅于渊龙同学的手写笔记,目标是写一个算法能将其分为多个小图,并且按照书写顺序从左到右,从上到下进行分割并依次编号。
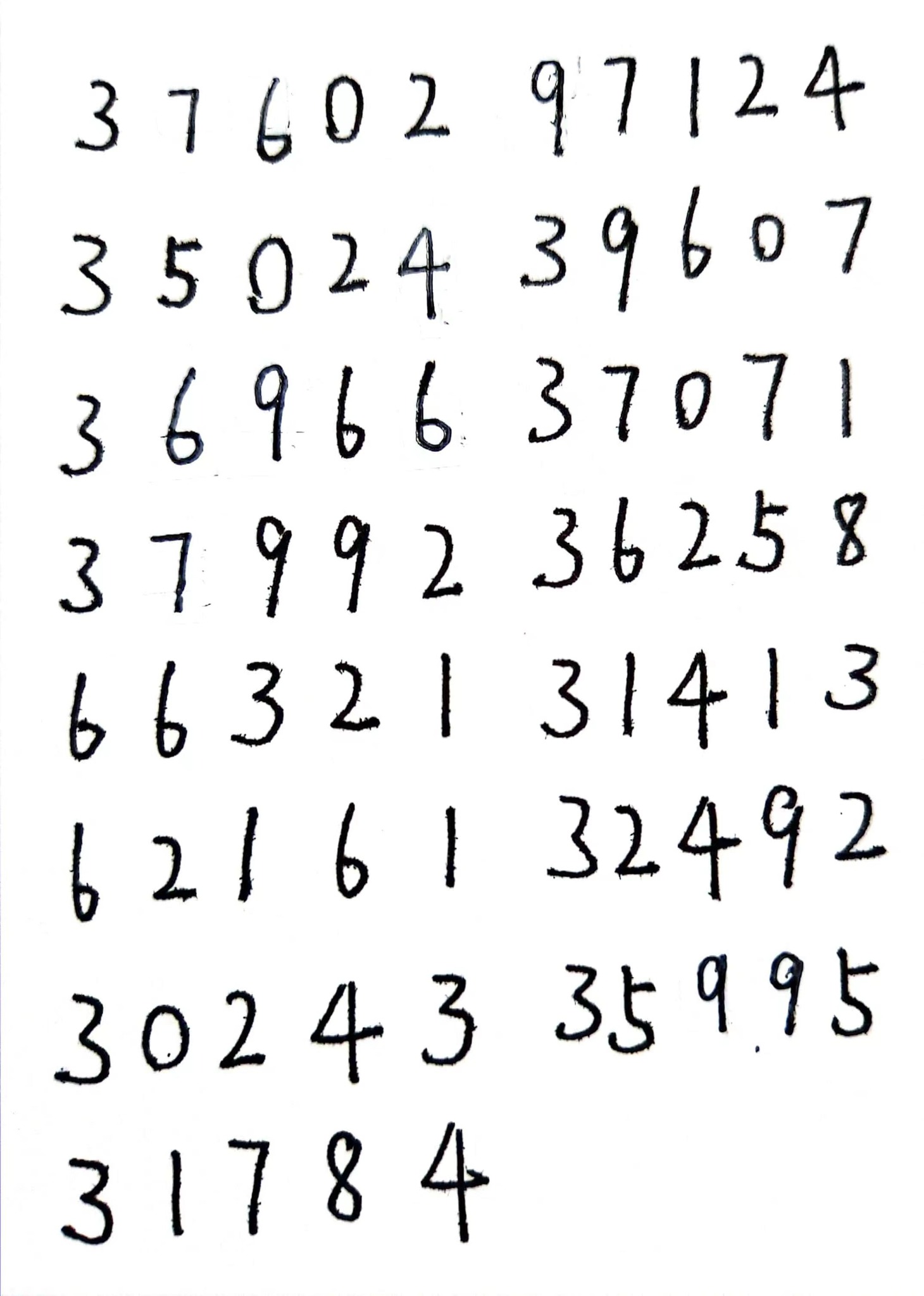
我们使用OpenCV来完成这部分的图像处理,设计这么一个函数:
输入:
image_path(str): 输入图片的文件路径。这个路径指向包含手写数字的图像文件。output_dir(str): 输出目录的路径。这个目录用于保存分割后的数字图片。如果目录不存在,会自动创建。
输出:
- 没有返回值,但会在指定的输出目录中保存分割后的数字图片。每个图片文件命名为
digit_{i}.png,其中{i}是数字图片的索引。
代码如下:
import cv2
import os
def split_image_into_digits(image_path, output_dir):
# 加载图片
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 反转颜色
image = cv2.bitwise_not(image)
# 二值化
_, thresh = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 查找轮廓
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 创建一个目录存储分割后的数字图像
os.makedirs(output_dir, exist_ok=True)
# 遍历轮廓并保存每个数字图像
for i, contour in enumerate(contours):
# 获取轮廓的边界框
x, y, w, h = cv2.boundingRect(contour)
# 提取数字图像
digit_image = image[y:y+h, x:x+w]
# 保存图像
cv2.imwrite(f"{output_dir}/digit_{i}.png", digit_image)
print("数字图像已保存至目录:", output_dir)
# split_image_into_digits使用示例
image_path = "./imgs/shuzi_da.png"
output_dir = "./imgs_output"
split_image_into_digits = split_image_into_digits(image_path, output_dir)
问题描述
分割效果很差,且没有按照顺序排序,75个数字被识别出来了一百多个数字,且成功率很低:
问题解决
- 去噪处理:使用中值滤波(
cv2.medianBlur)来去除图像噪点。难点在于找一个很好的去噪参数,这里取为13。 - 排序轮廓:在提取轮廓的边界框后,通过
sorted函数按照y坐标和x坐标进行排序,确保从左到右、从上到下的顺序。难点在于从上到下不能单单以y值作为排序依据,因为我们手写的时候不能确保一行的字的起始y值是一样的,所以要给出一定的浮动,这个浮动值也比较难调,这里取230
下面是改进后的代码:
import cv2
import numpy as np
import os
def split_image_into_digits(image_path, output_dir):
# 加载图片
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 反转颜色
image = cv2.bitwise_not(image)
# 去噪处理
image = cv2.medianBlur(image, 13)
# 二值化
_, thresh = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 查找轮廓
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 创建一个目录存储分割后的数字图像
os.makedirs(output_dir, exist_ok=True)
# 提取轮廓的边界框
bounding_boxes = [cv2.boundingRect(contour) for contour in contours]
# 排序边界框,首先按y坐标排序,再按x坐标排序,并考虑一定的浮动
def sort_key(box):
x, y, w, h = box
return (y // 230, x) # 使用y // 10给出一定的浮动
bounding_boxes = sorted(bounding_boxes, key=sort_key)
# 遍历边界框并保存每个数字图像
for i, (x, y, w, h) in enumerate(bounding_boxes):
# 提取数字图像
digit_image = image[y:y+h, x:x+w]
# 保存图像
cv2.imwrite(f"{output_dir}/digit_{i}.png", digit_image)
print("数字图像已保存至目录:", output_dir)
# split_image_into_digits使用示例
image_path = "./imgs/shuzi_da.png"
output_dir = "./imgs_output"
split_image_into_digits = split_image_into_digits(image_path, output_dir)
经检查,所有数字都按照顺序被分割了出来🎉
步骤二:小图识别及可视化展示
将封装好的模型函数与图片分割函数组合起来,即可实现一段手写数字的识别,我们采取可视化的方式进行直观展示。
问题描述
识别率很低,模型对于下面这种会先拉伸成28*28的正方形,从而导致识别正确率下降。
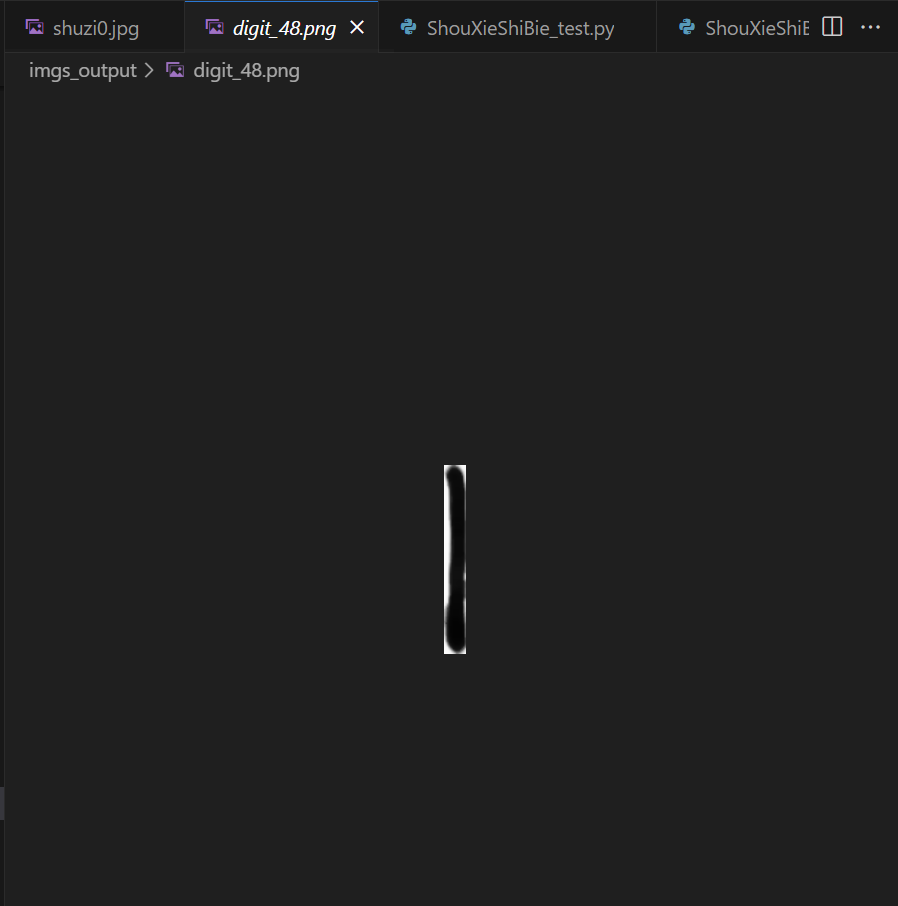
问题解决
在分割时就进行白色填充。填充规则为正方形的长宽变为28的整数倍,并且数字的上下起码要空出18的距离。
ps. 如果文字太过贴边会降低识别正确率,就譬如下面这张图很容易识别成1(白色的为图片轮廓,黑色的不属于图片部分):

# 遍历边界框并保存每个数字图像,并进行黑白反转和填充
for i, (x, y, w, h) in enumerate(bounding_boxes):
# 提取数字图像
digit_image = image[y:y+h, x:x+w]
# 黑白反转
digit_image = cv2.bitwise_not(digit_image)
# 将图像填充到正方形,使数字居中
size = max(w, h)
square_image = np.ones((size, size), dtype=np.uint8) * 255 # 创建一个白色正方形背景
x_offset = (size - w) // 2
y_offset = (size - h) // 2
square_image[y_offset:y_offset+h, x_offset:x_offset+w] = digit_image
# 保存图像
cv2.imwrite(f"{output_dir}/digit_{i}.png", square_image)
下面是完整的整合代码:
import torch
import torchvision
from PIL import Image
from torch import nn
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
# 该函数用于预测图片中的单个数字
def predict_digit(image_path):
# 打开图片并转换为灰度图像
image = Image.open(image_path).convert('L')
# 黑白反转
image = torchvision.transforms.functional.invert(image)
# 预处理图片
transform = torchvision.transforms.Compose(
[torchvision.transforms.Resize((28, 28)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5,), (0.5,))]
)
image = transform(image)
# 加载预训练模型
from ShouXieShiBie_model import GuoHangJiang
model = torch.load("ghj_18.pth", map_location=torch.device('cpu'))
# 添加batch size维度
image = torch.reshape(image, (1, 1, 28, 28))
# 预测
model.eval()
with torch.no_grad():
output = model(image)
# 返回预测结果
return torch.argmax(output, 1).item()
# 该函数负责将一张大图中的多个数字分割成小图片
def split_image_into_digits(image_path, output_dir):
# 加载图片
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 检查图片是否加载成功
if image is None:
raise ValueError(f"无法加载图像,请检查路径是否正确: {image_path}")
# 反转颜色
image = cv2.bitwise_not(image)
# 去噪处理
image = cv2.medianBlur(image, 13)
# 二值化
_, thresh = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 查找轮廓
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 创建一个目录存储分割后的数字图像
os.makedirs(output_dir, exist_ok=True)
# 提取轮廓的边界框
bounding_boxes = [cv2.boundingRect(contour) for contour in contours]
# 排序边界框,首先按y坐标排序,再按x坐标排序,并考虑一定的浮动
def sort_key(box):
x, y, w, h = box
return (y // 230, x) # 使用y // 10给出一定的浮动
bounding_boxes = sorted(bounding_boxes, key=sort_key)
# 遍历边界框并保存每个数字图像,并进行白色填充
for i, (x, y, w, h) in enumerate(bounding_boxes):
# 提取数字图像
digit_image = image[y:y+h, x:x+w]
# 计算填充后的正方形边长,并确保上下至少有18像素的间距
target_size = max(w, h + 36)
target_size = ((target_size + 27) // 28) * 28 # 调整为28的整数倍
# 创建一个新的正方形图像,并将数字图像居中放置
padded_image = np.ones((target_size, target_size), dtype=np.uint8) * 0
y_offset = (target_size - h) // 2
x_offset = (target_size - w) // 2
padded_image[y_offset:y_offset+h, x_offset:x_offset+w] = digit_image
# 反转颜色,恢复为黑字白底
padded_image = cv2.bitwise_not(padded_image)
# 保存图像
cv2.imwrite(f"{output_dir}/digit_{i}.png", padded_image)
print("数字图像已保存至目录:", output_dir)
# 该函数负责对大图中的所有数字进行识别,并以可视化方式展示
def recognize_and_visualize(image_path, output_dir):
split_image_into_digits(image_path, output_dir)
digit_images = sorted(os.listdir(output_dir), key=lambda x: int(x.split('_')[1].split('.')[0]))
predictions = []
for digit_image in digit_images:
digit_path = os.path.join(output_dir, digit_image)
prediction = predict_digit(digit_path)
predictions.append(prediction)
# 可视化结果,每行显示10个数字
num_digits = len(predictions)
num_cols = 10
num_rows = (num_digits + num_cols - 1) // num_cols
fig, axes = plt.subplots(num_rows, num_cols, figsize=(num_cols, num_rows))
axes = axes.flatten()
for i, digit_image in enumerate(digit_images):
digit_path = os.path.join(output_dir, digit_image)
img = Image.open(digit_path).convert('L')
axes[i].imshow(img, cmap='gray')
axes[i].set_title(str(predictions[i]))
axes[i].axis('off')
for i in range(num_digits, len(axes)):
axes[i].axis('off')
plt.tight_layout()
plt.show()
# 示例调用
image_path = "./imgs/shuzi_da.png"
output_dir = "./imgs_output"
recognize_and_visualize(image_path, output_dir)
运行结果如下:
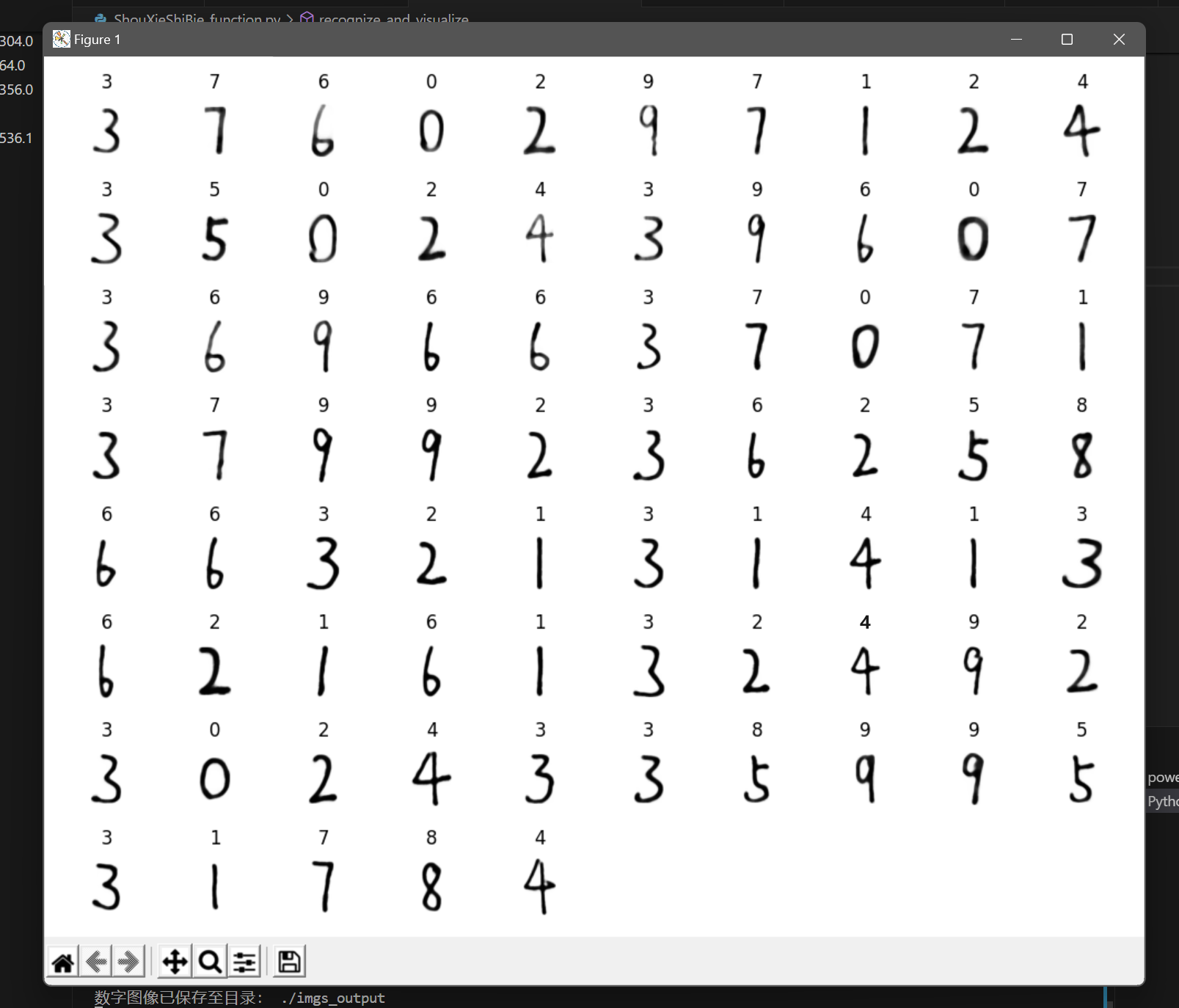
至此,成功实现了一段手写数字的识别。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝