


《HyperVision(简称)》论文阅读笔记
原文:Flow_Interaction_Graph_Analysis_Unknown_Encrypted_Malicious_Traffic_Detection.pdf
源码地址:HyperVision: Flow Interaction Graph based attack traffic detection system
0 摘要
加密的恶意流量与良性流量相似,很容易逃避传统的检测。
原来的检测方法都是靠标记好的数据集训练,监督学习,未知的加密恶意流量难搞定。
提出了一种基于无监督机器学习的恶意流量检测系统——HyperVision
HyperVision:
思路:通过流量交互模式构建图-》分析图特征检测未知模式的加密恶意流量
效果:通过140次真实攻击的实验结果显示,HyperVision的准确率比最先进的方法提高了13.9%。
速度:平均检测延迟为0.29秒的情况下,实现了15.82 Mbps的检测吞吐量。
关键词:恶意加密流量检测、机器学习、图学习。
1 引言
互联网上的加密恶意流量比例显著增加,已经超过了整个恶意流量的70%。然而,由于加密流量的低速率和多样的流量模式,加密恶意流量的检测仍未得到很好地解决。传统的基于特征码的方法,如深度包检测(DPI),在面对加密负载时无效。现有的加密恶意流量检测方法不同于明文恶意流量的检测,前者与良性流量特征相似,因此也能逃避基于机器学习的现有检测系统。其次就是有监督的依赖于已知攻击的先验知识,无法检测出构建于未知模式的加密攻击流量。
简而言之,现有的方法无法通过学习单个流量的特征来检测未知模式的加密恶意流量。然而,检测这种攻击流量仍然是可行的,因为这些攻击涉及多个攻击步骤,并且在攻击者和受害者之间有不同的流量交互,这些交互模式与良性流量的交互模式显著不同。例如,即使单个攻击流量与良性流量相似,垃圾邮件机器人与SMTP服务器之间的加密流量交互也明显不同于合法通信。因此,本文探索了利用流量交互模式进行恶意流量检测。
为此,我们提出了HyperVision,这是一种实时检测系统,旨在捕获加密的恶意流量。特别是,它可以通过识别异常的流量交互来检测具有未知模式的加密恶意流量,即与良性流量不同的交互模式。为了实现这一目标,我们构建了一个图来表示流量交互模式,使HyperVision能够通过学习图的结构特征,既能检测加密的恶意流量,也能检测明文的恶意流量。同时,通过学习图的结构特征,它实现了无监督检测,不需要使用标记数据集进行模型训练。
然而,实时检测中构建图是一个挑战。我们不能简单地使用IP地址作为顶点,使用流量作为边来构建图,因为生成的密集图不能通过图学习方法进行分析。为了解决这个问题,我们采用了两种策略来记录不同大小的流量,并分别在图中处理短流量和长流量的交互模式。(整合密集的短流量,保留长流量信息)具体来说,它基于互联网上大量短流量的相似性聚合短流量,从而减少图的密度,并为长流量提取基于分布的特征,这可以有效地保留流量交互信息。
我们设计了一个轻量级的无监督图学习方法,通过利用图中丰富的流量交互信息来检测加密恶意流量:
步骤一:为了实现高效的图学习,我们通过提取连接组件来分析图的连通性,并通过聚类高级统计特征来识别异常组件。
步骤二:根据观察到的局部邻接关系对边进行预聚类,这大大减少了特征处理的开销,确保了实时检测。
步骤三:通过求解顶点覆盖问题来提取关键顶点,以最小化聚类数量。
步骤四:根据连接的边对每个关键顶点进行聚类,这些边位于预聚类生成的聚类中心,从而获得指示加密恶意流量的异常边。
我们还开发了一个基于信息理论的流量记录熵模型,证明现有的数据源如NetFlow和Zeek难以保留高保真度的流量信息,无法有效检测流量交互。而HyperVision的图结构能捕获接近最优的信息量,其信息密度远超现有方法,是实现高效检测的关键。
下面的图表展示了HyperVision所采用的“流量交互图”方法相较于其他现有检测方法的全面优势。
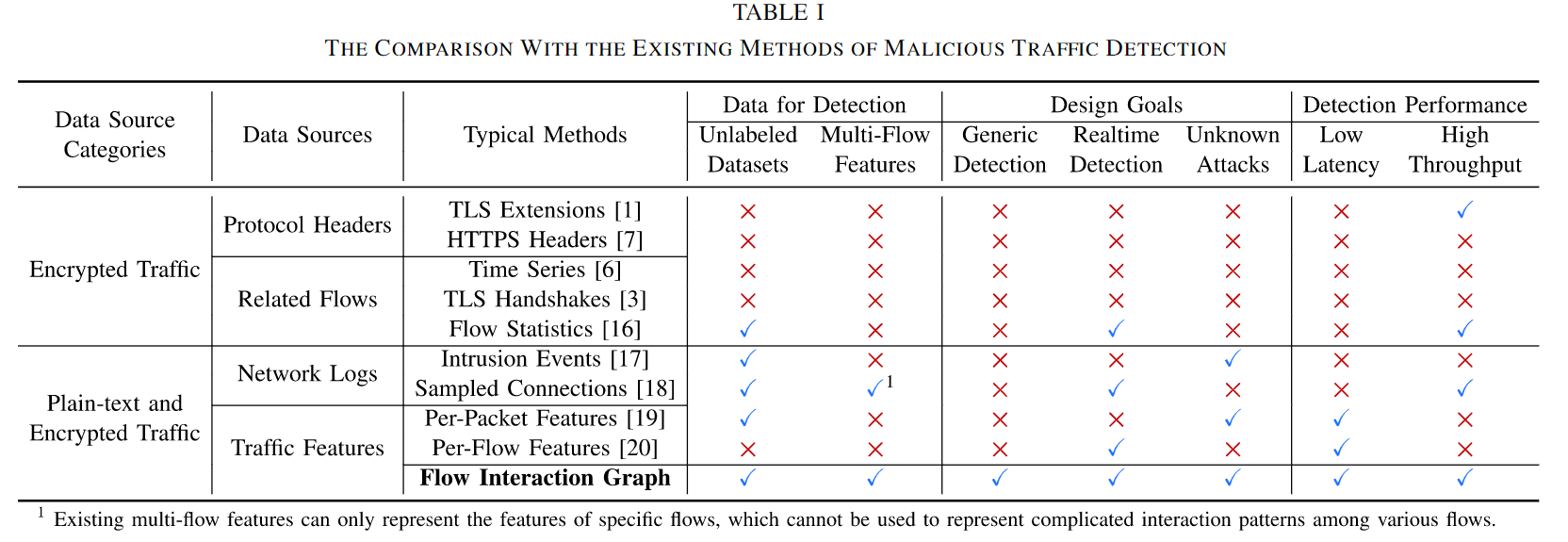
传统方法只能看到单个流的行为,而无法理解不同流之间如何相互作用,这在检测复杂的、多步的攻击时是一个明显的弱点。
我们使用Intel的Data Plane Development Kit (DPDK)实现了HyperVision的原型系统。为了全面评估该原型,我们重放了92个攻击数据集,其中包括在我们的虚拟私有云(VPC)中收集的80个新数据集,涵盖了超过1500个实例。在VPC中,我们收集了48种典型的加密恶意流量,这些流量包括:加密泛洪流量(例如泛洪目标链接)、Web攻击(例如利用Web漏洞)以及恶意软件活动(包括连接性测试、依赖项更新和下载等)。我们观察到,HyperVision的准确率相比于五种现有的最先进方法提高了13.9%。该系统能够在无监督的情况下检测所有加密恶意流量,F1得分超过0.86,而其中44种实际中的隐蔽流量无法被所有基线方法识别。这些隐蔽流量包括利用CVE-2020-36516的高级侧信道攻击以及许多新发现的加密劫持攻击。实际使用案例表明,HyperVision产生的误报极少,并且可以轻松过滤掉。此外,HyperVision平均检测吞吐量超过100 Gb/s,平均检测延迟为0.29秒。
总结而言,我们的贡献包括以下六点:
我们提出了HyperVision,这是第一个利用流量交互图进行未知模式加密恶意流量实时无监督检测的系统。
我们开发了多种算法来构建图,使我们能够准确捕捉不同流量之间的交互模式。
我们设计了一种轻量级的无监督图学习方法,通过图特征检测加密流量。
我们开发了一个基于信息理论的分析框架,证明该图能够捕捉近乎最优的流量交互信息。
我们采用了一种降维方法,显著提高了检测吞吐量并降低了检测延迟。
我们实现了HyperVision的原型,并通过对各种实际加密恶意流量的广泛实验验证了其准确性、效率和稳健性。
论文的结构如下:第二部分介绍了HyperVision的威胁模型;第三部分展示了系统的高级设计;第四、五和六部分详细描述了具体设计;第七部分进行理论分析;第八部分进行性能的实验评估;第九部分回顾了相关工作;第十部分总结了全文。
2 威胁模型和设计目标
我们旨在开发一个实时系统(即HyperVision),用于检测加密的恶意流量。系统根据路由器通过端口镜像复制的流量执行检测,这样可以确保系统不会干扰流量转发。在识别出加密的恶意流量后,该系统可以与现有的路径恶意流量防御系统协同工作,以限制检测到的恶意流量。由于处理的是加密流量,我们无法解析和分析应用层的报头和负载。
在本文中,我们的关注点是检测由加密流量构成的主动攻击。这类攻击是通过产生流量来攻击受害者的,而非仅仅进行被动监听或分析,如流量窃听或被动流量分析。根据现有研究,攻击者通常会利用侦查步骤来探测受害者的信息,例如获取受害者的密码、TLS连接的TCP序列号以及Web服务器的随机内存布局,这些信息由于缺乏先验知识,攻击者通常无法直接获取。需要注意的是,这些攻击通常涉及多个由攻击者拥有或伪造的地址。
HyperVision的设计目标如下:
通用检测:系统应能够检测由加密或非加密流量构成的攻击,确保攻击者无法通过加密流量逃避检测。
实时高速处理:系统应能够实时处理高速流量,确保在低延迟的情况下识别通过的加密流量是否为恶意流量。
无监督检测:系统的检测应为无监督方式,即不需要任何加密恶意流量的先验知识。换句话说,系统应能够处理未知模式的攻击(即0day攻击),这些攻击尚未被公开。因此,我们不使用任何标记数据集进行机器学习模型的训练。
这些设计目标是现有检测方法难以很好地解决的问题。
3 系统高级设计
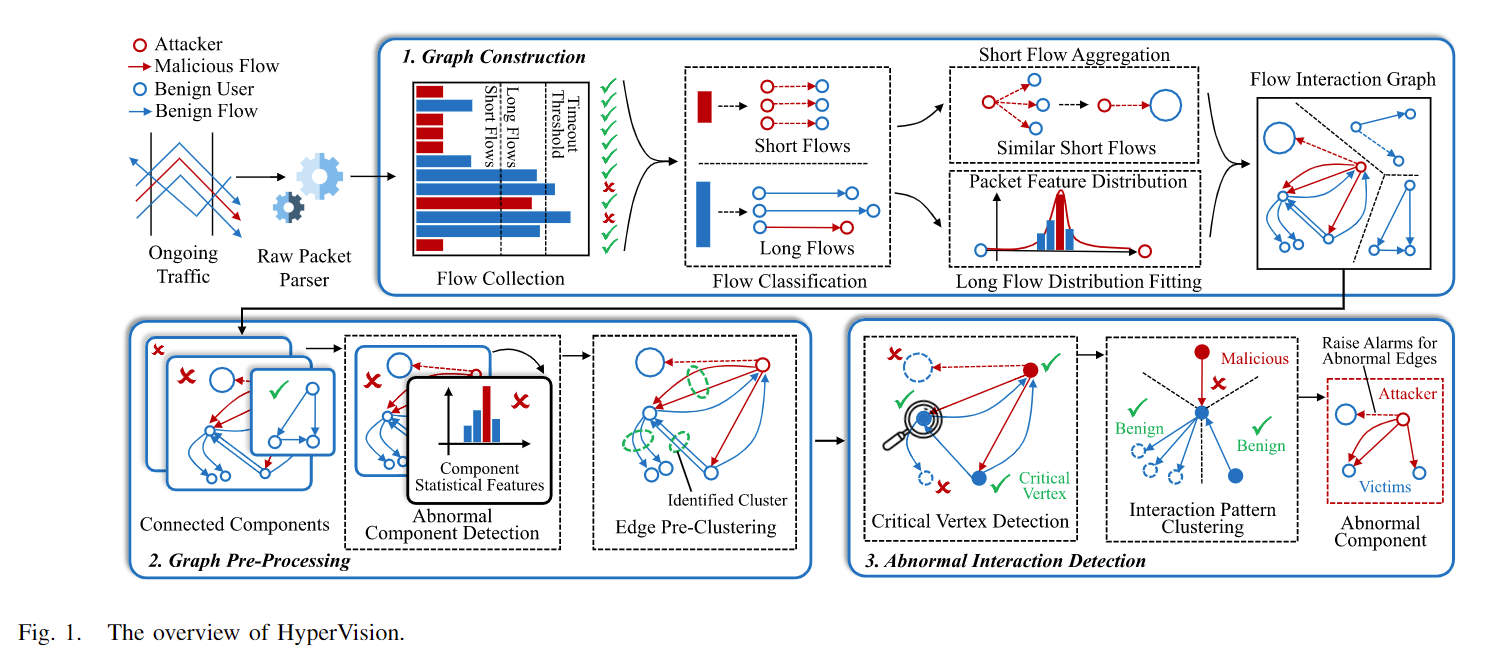
在本节中,我们介绍了HyperVision的高级设计。通常,单个流中的加密恶意流量模式(即单流模式)可能与正常流量相似,从而使其能够逃避现有检测。然而,攻击者与受害者之间的交互模式中出现的恶意行为将比正常行为更加显著。因此,在HyperVision中,我们构建了一个图来表示流量之间的交互模式,并通过无监督图学习检测异常交互模式。同时,它通过分析流量而不考虑流量类型,实现了通用检测,并能够检测加密和未加密的恶意流量。图1显示了HyperVision的三个关键部分,即图构建、图预处理和异常交互检测。
3.1 图构建
HyperVision收集网络流量以构建图。同时,它将流量分为短流和长流,并分别记录它们的交互模式,以减少图的密度。在图中,它使用不同的地址作为顶点,连接分别与短流和长流相关的边。它将大量相似的短流聚合为一个边,从而减少了维护流量交互模式的开销。此外,它记录长流的分组特征分布,以构建与长流相关的边,从而确保了高保真记录的流量交互模式,同时解决了传统方法中粗粒度流量特征的问题。我们将在第四节详细介绍HyperVision如何在图中保持高保真流量交互模式。
简言之:流分类-》长短流各自处理-》组成图
具体看第四节
在网络分析中,“流”(flow)通常指的是在一段时间内,从一个源地址到一个目标地址之间,基于某个协议的连续数据包的集合。一个流可以包含多次通信或数据包的传输。例如,从一台计算机发送到另一台计算机的一系列TCP数据包可以被视为一个流。每个流的特征(如源地址、目标地址、协议类型、端口号等)是相对固定的,但流内的数据包内容可能各不相同。
在系统中区分了“长流”和“短流”,并对它们进行了不同的处理:
短流(Short Flows):
定义:短流通常是指那些数据包数量较少、持续时间较短的流。
处理方法:由于短流在网络中数量庞大且特征相似,论文中的HyperVision系统将多个相似的短流聚合为一个边(edge),并在图中表示。这样做的目的是减少图的密度和处理开销。通过这种聚合方式,一个代表多个相似短流的边可以有效地降低系统在处理这些短流时的复杂度和存储需求。
长流(Long Flows):
定义:长流是指那些数据包数量多、持续时间较长的流。
处理方法:对于长流,系统会记录这些流的分组特征(如包的长度、到达时间间隔等)的分布,并将这些信息构建为图中的边。这种方法确保了长流的高保真度记录,同时避免了仅依赖简单统计信息所带来的信息丢失。
3.2 图预处理
我们对构建的交互图进行预处理,以通过提取连接的组件并使用高级统计数据对组件进行聚类来减少处理图的开销。特别是,聚类可以准确检测仅包含正常交互模式的组件,从而过滤这些正常组件以减少图的规模。此外,我们进行预聚类,并使用生成的聚类中心来表示标识的聚类中的边。我们将在第五节详细介绍图预处理,并进一步通过降维方法提高预聚类的效率。
简言之:统计特征-》找到异常组件-》聚合组件中相似边提高效率
具体看第五节
3.3 基于图的恶意流量检测
我们通过分析图特征来实现无监督的加密恶意流量检测。通过解决顶点覆盖问题,我们在图中识别关键顶点,以确保基于聚类的图学习以最小的聚类数量处理所有边。对于每个选定的顶点,我们根据它们的流量特征和表示流量交互模式的结构特征聚类所有连接的边。通过计算聚类的损失函数,HyperVision可以实时识别异常边缘,从而标识加密的恶意流量。我们将在第六节中描述基于图学习的检测详细信息。
简言之:通过关键节点进行聚类-》找到异常的流量模式-》定位所处的组件再具体分析
具体看第六节
4 图构建

在本节中,我们介绍了构建维护各种流之间交互模式的流量交互图的设计细节。特别地,我们对不同的流(即短流和长流)进行分类和聚合,同时分别记录特征分布,以实现高效的图构建。在第七节中,我们将展示该图在检测中的信息保留接近最优。
4.1 流分类
为了高效分析从互联网捕获的流量,我们需要在图构建过程中避免流量之间的依赖爆炸。
根据流量大小分布(见图2)将捕获的流量分类为短流和长流。图2展示了MAWI互联网流量数据集中流量完成时间(FCT)和流量长度的分布情况。我们使用2020年1月随机选择一天收集的前5%(1300万个)数据包绘制了该图。根据该图,我们观察到仅有5.52%的流量FCT超过2.0秒,这与其他月份的比例相似,如3月份为5.34%,4月份为5.18%。然而,数据集中93.70%的数据包是长流量,且比例仅为2.36%。受这些观察的启发,我们对短流和长流应用了不同的流量收集策略。
我们从数据平面高速数据包解析引擎中轮询每个数据包的信息,并获取其源地址和目标地址、端口号以及每个数据包的特征,包括协议、长度和到达间隔。这些特征可以从加密和非加密流量中提取,以实现通用检测。我们开发了一个流分类算法来对流量进行分类(参见附录A中的算法1,见补充材料)。它维护一个定时器TIME_NOW,一个使用HASH(SRC, DST, SRC_PORT, DST_PORT)作为键的哈希表,和以它们的每个数据包特征序列作为值的已收集流量。算法每隔JUDGE_INTERVAL秒根据TIME_NOW遍历哈希表,并在最后一个数据包到达时间早于TIME_NOW的PKT_TIMEOUT秒时判断流量完成。当流量完成时,如果流量的包数超过FLOW_LINE,我们将其分类为长流,否则分类为短流。如图2(b)所示,我们可以准确地分类短流和长流。超参数的定义可以在表VI中找到(见附录A中的补充材料)。注意,我们从数据平面轮询无状态的每个数据包信息,而不是在数据平面上维护流状态(例如状态机)以防止攻击者操纵状态,如侧信道攻击和逃避检测。
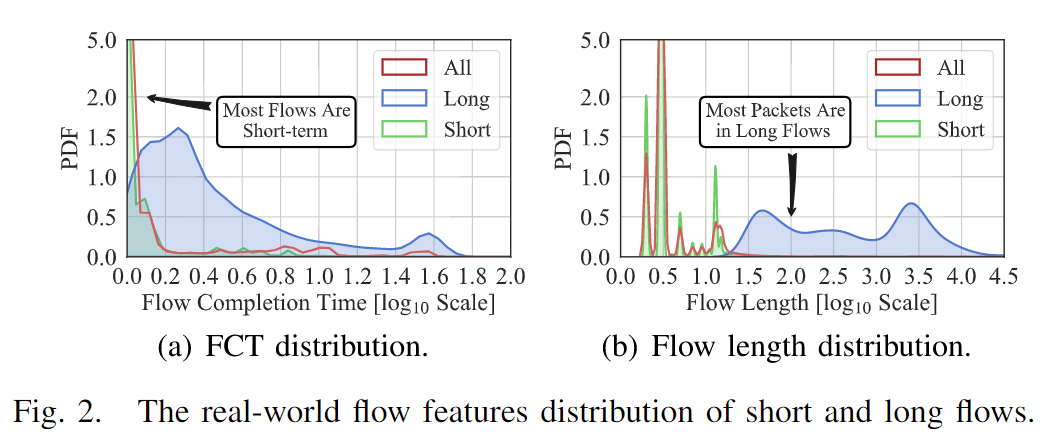
长流不仅仅是完成时间长再叫长流,也可以是传输的数据量大
这篇论文中主要是通过流长度来判断的,流长度指的是一个流中包含的数据包数量。
然后降低图的密度(如图3所示)。
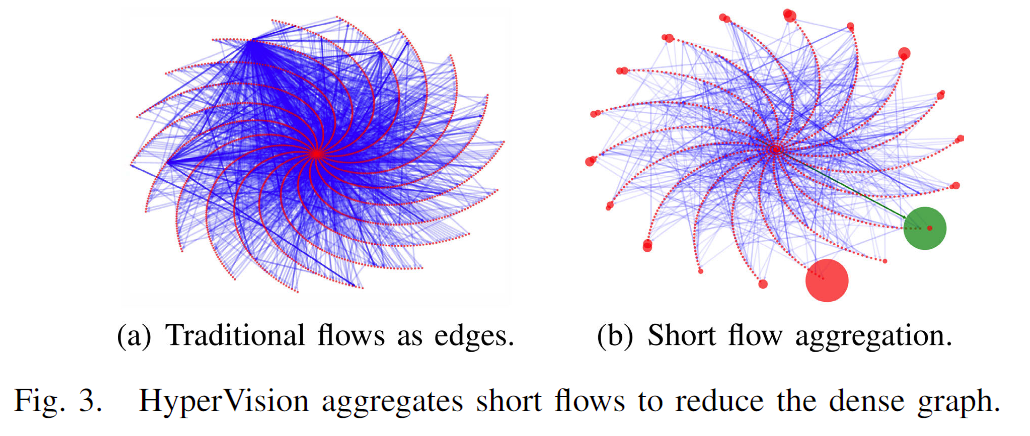
4.2 短流聚合
我们需要减少图的密度以便分析。如图3(a)所示,如果我们使用传统的四元组流作为边,则图将非常密集,类似于在溯源分析中的依赖爆炸问题。我们观察到大多数短流具有几乎相同的每个数据包特征序列。例如,特定攻击者发起的重复SSH破解尝试的加密流。因此,我们执行短流聚合,将相似的流量使用一条边表示,完成分类后再构建图。
我们设计了一个算法来聚合短流(参见附录A中的算法2,见补充材料)。当所有以下条件都满足时,一组流可以被聚合:
流具有相同的源和/或目标地址,意味着这些地址生成了相似的行为。
流具有相同的协议类型。
流的数量足够大,即当短流的数量达到阈值
AGG_LINE时,确保这些流量足够重复。
接下来,我们为短流构建一条边,保存所有聚合流的单个特征序列,包括协议、长度和数据包之间的到达间隔。通过这种方式,我们可以有效地减少实时检测的存储开销。总之,在图中存在四种类型的与短流相关的边,即源地址聚合、目标地址聚合、双地址聚合和无聚合。因此,与边相连的顶点可以表示一组地址或单个地址。
图3比较了使用传统流作为边的图和我们通过使用真实世界主干流量数据集的聚合图。顶点的直径表示顶点表示的地址数量,颜色的深浅表示重复边的深浅。在图3(b)中,我们观察到该算法减少了93.94%的顶点和94.04%的边。用绿色突出显示的边表示利用漏洞的短流(即2.38 Kpps,来自PH)。注意,为了最小化存储开销,流聚合在接收流量时执行,实现实时检测的内存图维护。
4.3 长流的特征分布分析
现在我们使用直方图表示长流的每个数据包特征分布(例如到达间隔),从而避免保存它们的长数据包特征序列,因为长流中的特征通常集中分布。具体来说,我们维护一个哈希表,为每个长流中的每个数据包特征序列构建直方图。根据我们的经验研究,我们设置了数据包长度和到达间隔的桶宽度分别为10字节和1毫秒,以在拟合精度和开销之间进行权衡。我们通过将每个数据包特征除以桶宽来计算哈希码,并增加由哈希码索引的计数器。最后,我们将哈希码和相关计数器记录为直方图。注意,对于短流,直方图不能有效地表示短数据包特征序列,因此我们直接保存短流的特征序列。
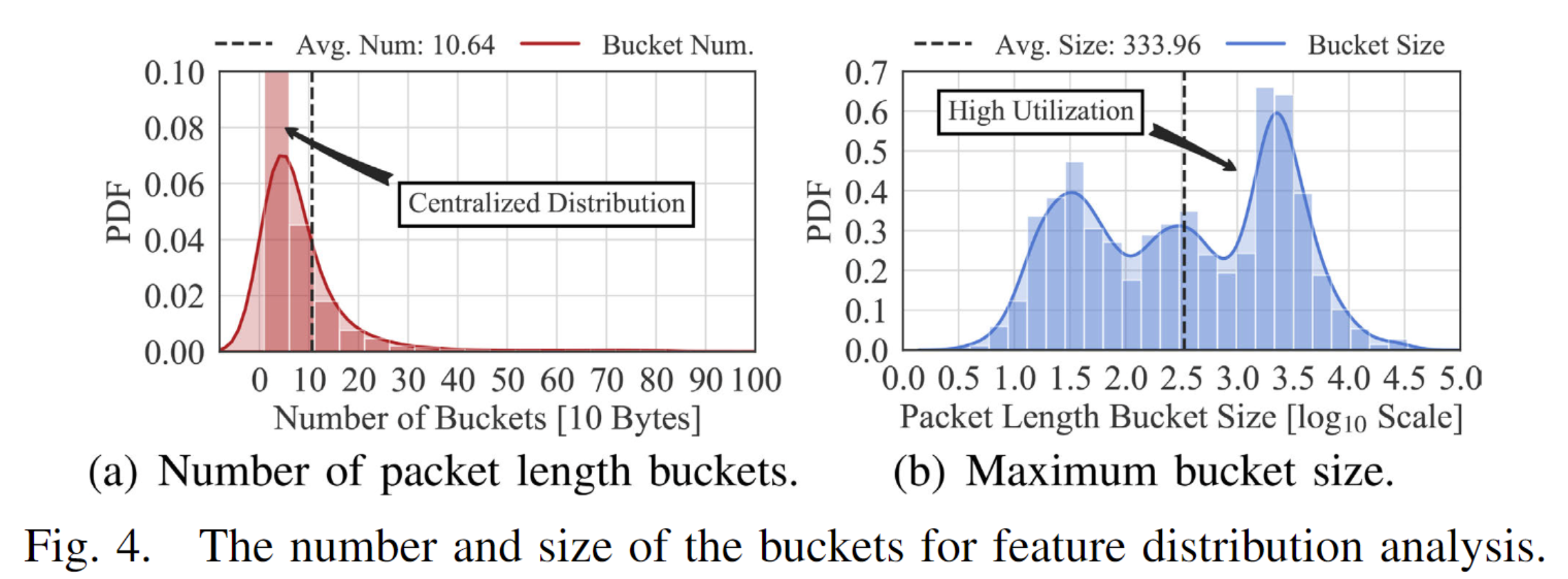
图4展示了相同数据集(如图2所示)中长流使用的桶数和最大桶大小。我们确认特征分布集中,即大多数长流中的数据包具有相似的包长度和到达间隔。具体来说,在图4(a)中,我们仅用11个桶就可以拟合数据包长度的分布,且大多数桶收集了200个以上的数据包(见图4(b)),这表明基于直方图的拟合在低存储开销的情况下是有效的。类似地,到达间隔的拟合平均使用121个桶,实现了每个桶71个数据包的高利用率。此外,我们使用相同的方法处理协议。我们使用协议掩码作为哈希码,并使用更少的桶来实现更高效的拟合,因为协议类型的数量有限。注意,两个顶点之间的重复边表示两个主机之间的并发流。这意味着并发流的特征是分别提取的。
5 图预处理
在本节中,我们介绍如何对流量交互图进行预处理,以便减少计算开销并为无监督的恶意流量检测做好准备。具体来说,我们首先进行连通性分析,以提取图中的连通组件。接着,我们对每个连通组件进行聚类分析,进一步减少图的规模。最后,我们介绍一种预聚类的方法,通过减少边的数量来提高聚类效率。
5.1 连通性分析
为了执行图的连通性分析,我们使用深度优先搜索(DFS)获得连通组件,并通过这些组件将图进行拆分。
图5(a)展示了在2020年1月收集的MAWI流量数据集中识别出的组件的大小分布。我们观察到,大多数组件仅包含少量边,并且具有相似的交互模式。
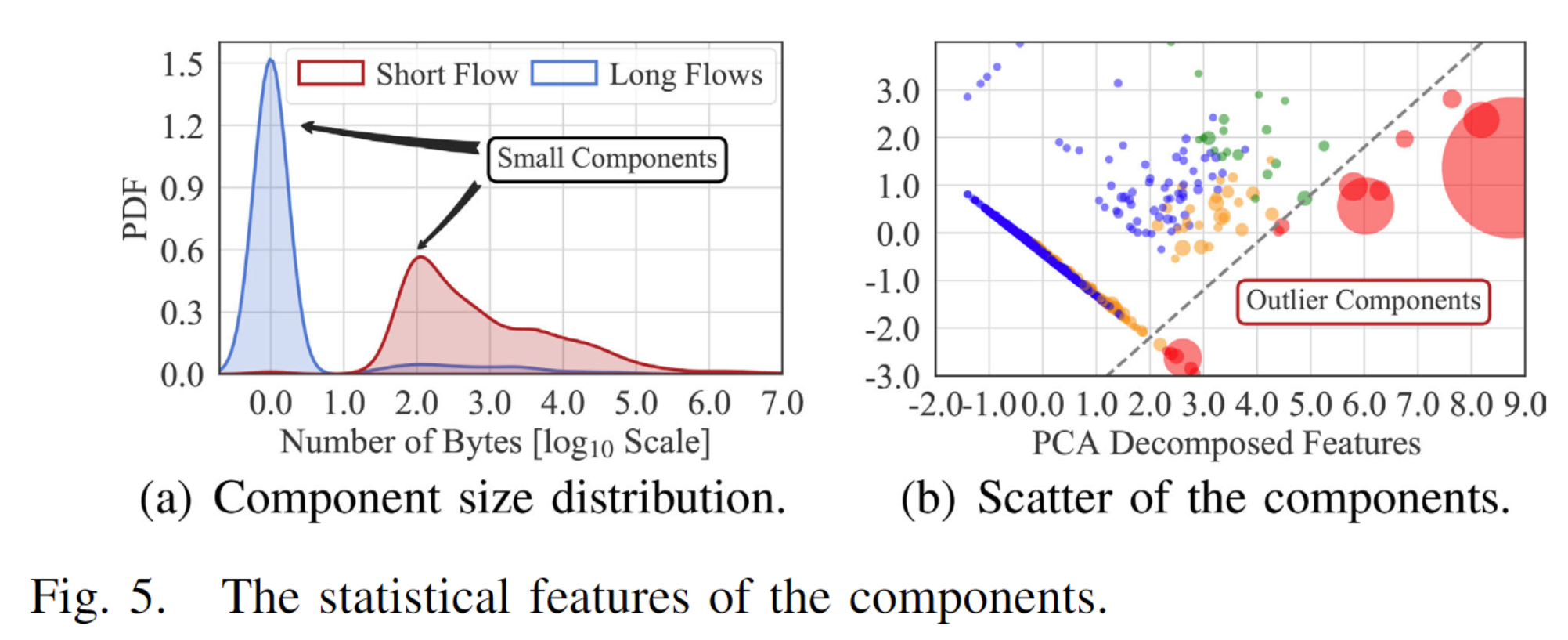
因此,我们对连通组件的高级统计数据进行聚类,以捕获那些聚类损失超过正常组件一个数量级的异常组件,将其作为聚类异常点。具体来说,我们提取了五个特征来描述这些组件,包括:
长流的数量
短流的数量
表示短流的边的数量
长流中的字节数
短流中的字节数。
我们对这些特征进行最小-最大归一化,并使用基于密度的聚类方法(如DBSCAN [48])获取聚类中心。对于每个组件,我们计算其到最近聚类中心的欧氏距离。当某个组件的距离超过所有距离的99百分位数时,我们将其检测为异常组件。
图5(b)显示了一个聚类实例,其中的直径表示组件上的流量规模(以字节为单位)。我们观察到,大多数组件很小,而大量巨大的组件被归类为异常组件。所有与正常组件相关的边都被标记为良性流量,而与异常组件相关的边将由后续步骤进一步处理。
5.2 边的预聚类
现在我们进一步处理图,并对其进行预聚类,以实现高效的检测。如图5所示,图中的异常组件包含大量顶点和边。特别是,我们无法直接应用图表示学习方法(如图神经网络,GNN)进行实时检测。
图6显示了图结构特征空间中组件的边的分布情况。我们观察到边的分布是稀疏的,即大多数边在特征空间中邻近大量相似的边。
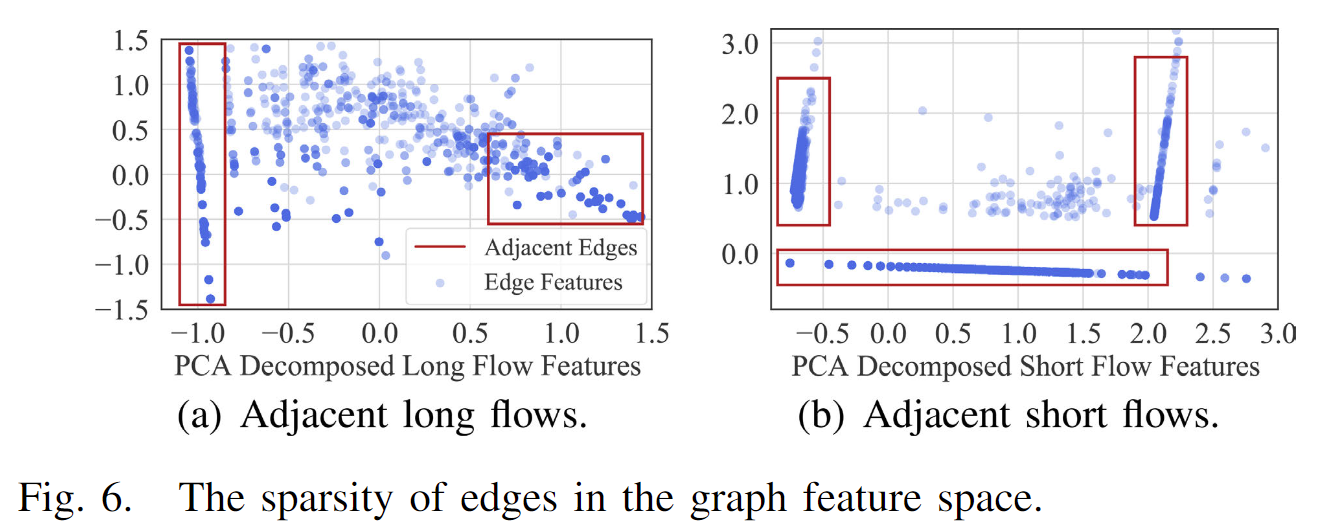
为了利用这种稀疏性,我们使用DBSCAN [48]进行预聚类,该方法利用KD-Tree进行高效的局部搜索,并选择识别出的聚类的聚类中心来表示每个聚类中的所有边,从而减少图处理的开销。具体来说,我们为与短流和长流相关的边分别提取了八个和四个图结构特征(见附录A中的表V,补充材料部分),例如与长流相关的边的源顶点的入度。
这些恶意流量的度特征与良性流量显著不同,例如,由于垃圾邮件机器人频繁与服务器交互,表示它们的顶点具有比良性客户端更高的出度。然后,我们对这些特征进行最小-最大归一化,并采用较小的搜索范围ε和较大的最小点数来进行DBSCAN聚类(见第VIII-A节中的超参数设置),以避免将无关的边包含在聚类中,这可能导致误报。
此外,有些边无法被聚类,这些边将被视为异常点,并作为只有一条边的聚类进行处理。
这里的聚类中心不仅仅可以是点,也可以代表边:
假设我们有一组边,每条边都有一个长度特征和一个持续时间特征。在进行聚类后,假设我们得到以下两个聚类:
聚类1:包含10条边,长度集中在50-60,持续时间集中在200-250毫秒之间。
聚类2:包含15条边,长度集中在70-80,持续时间集中在300-350毫秒之间。
在这种情况下,聚类中心可能是:
聚类1的中心:长度55,持续时间225毫秒。
聚类2的中心:长度75,持续时间325毫秒。
这些聚类中心可以用来代表各自的聚类,而不需要逐一处理聚类中的每一条边。
6 基于图的恶意流量检测
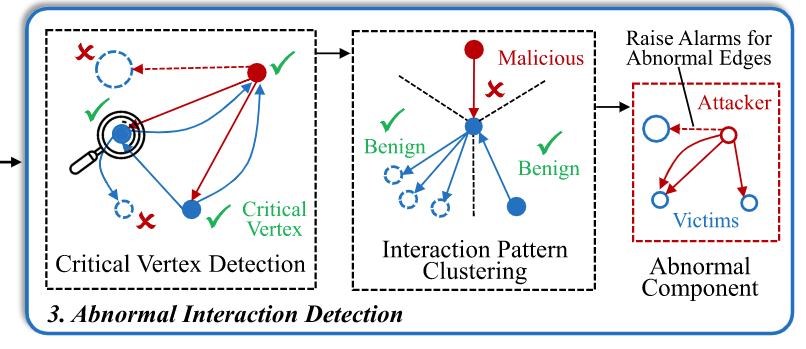
在本节中,我们描述了如何通过分析图结构来实现无监督的恶意流量检测。我们的方法旨在识别那些未被识别出但确实是异常的流量,这些流量可能包含恶意行为。
特别地,我们对连接到同一关键顶点的边进行聚类,并将离群点检测为恶意流量(见图7)。
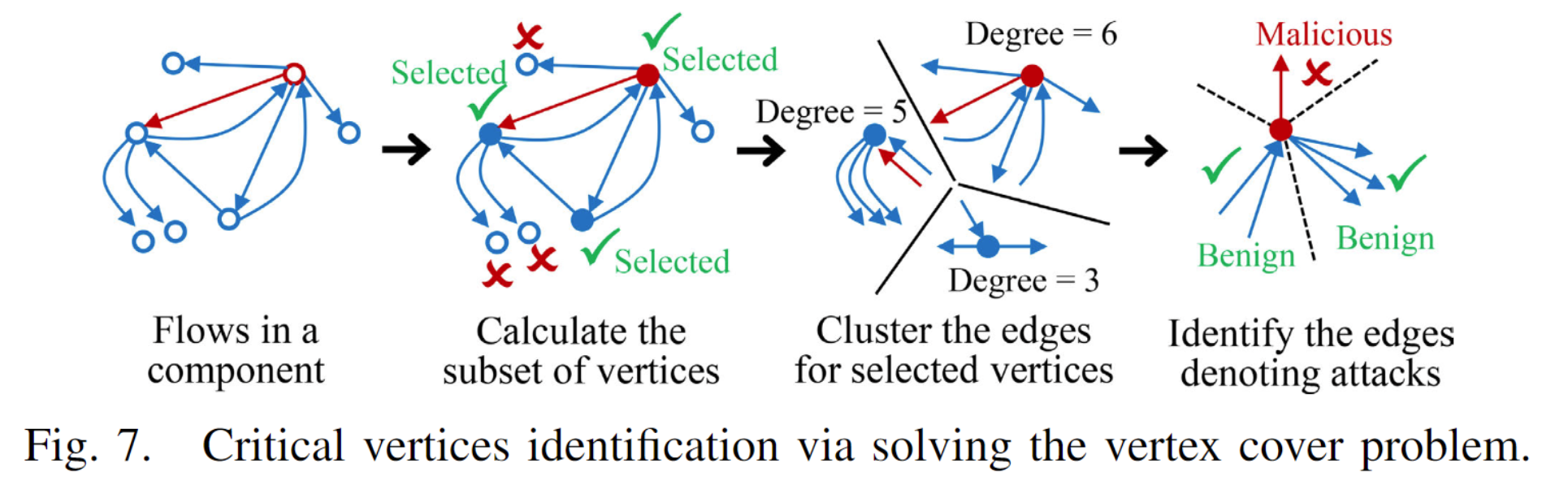
6.1 关键顶点检测
为了高效地学习流量的交互模式,我们并不直接对所有的边进行聚类,而是对连接到关键顶点的边进行聚类。
对于每个连通组件,我们根据以下条件选择该组件中所有顶点的一个子集作为关键顶点:
子集中包含组件中每条边的源顶点和/或目标顶点,这确保了所有的边都连接到至少一个关键顶点,并且至少被聚类一次。
子集中选定的顶点数量最小化,目的是减少聚类次数,从而降低图学习的开销。
找到这样的顶点子集是一个优化问题,等价于顶点覆盖问题(vertex cover problem)[49],这个问题已被证明是NP完全(NP Complete,NPC)问题。我们选择每个组件中的所有边和所有顶点来解决这个问题。我们将该问题重新表述为一个可满足性模理论(SMT)问题,并使用Z3 SMT求解器[50]来有效解决它。由于我们预先对大量边进行了聚类并减少了问题的规模(见第V-B节),这个NPC问题可以实时解决。
需要注意的是,使用阈值选择高度顶点作为关键顶点并不是一个合适的方法。与顶点覆盖问题不同,这种方法无法保证每条边都连接到至少一个关键顶点。因此,任何未连接的边将不会被考虑在每个关键顶点的聚类分析中。
6.2 用于检测的边特征聚类
现在我们对连接到每个关键顶点的边进行聚类,以识别异常交互模式。在这个步骤中,我们使用了第V-B节中的结构特征,以及从短流的每包特征序列或长流的拟合特征分布中提取的流特征(参见附录A中的所有特征,补充材料部分)。我们采用基于度的特征,因为具有高度的顶点表示异常用户正在发起大量攻击流,例如密码破解[8]。与现有方法不同,我们不分析特定协议的特征(如TLS头中的字段),以实现对各种协议的通用检测。我们分别使用轻量级的K-Means算法对与短流和长流相关的边进行聚类,并计算聚类损失,这表明用于恶意流量检测的恶意程度。
聚类损失的计算公式如下:
其中,K是获得的聚类中心的数量,C_i是第i个聚类中心,f(edge)是特征向量,C(edge)包含了预聚类生成的边所在的聚类中的所有边,TimeRange 计算由边表示的流量覆盖的时间范围。
根据公式(4),损失有三个部分:
公式(1)中的 loss_\mathrm{center}是到聚类中心的欧氏距离,表示与连接到关键顶点的其他边的差异;
公式(2)中的 loss_\mathrm{cluster}表示由第V-B节中的预聚类识别的聚类所覆盖的时间范围,这意味着持续时间较长的交互模式往往是良性的;
公式(3)中的 loss_\mathrm{count}是由边表示的流量数量,这意味着大量流量的爆发暗示了恶意行为。
此外,我们使用权重\alpha、\beta、\gamma来平衡损失项。最后,当边的损失超过某个阈值时,系统会将相关流量检测为恶意流量。
6.3 异常组件检测
最后,我们将检测的重点放在那些与恶意流量相关的异常组件上。异常组件是指图中的子图,这些子图中的顶点和边显示出与正常流量显著不同的模式。通过分析这些组件,我们能够识别出潜在的攻击者及其目标,并对这些异常行为发出警报。异常组件检测是我们恶意流量检测框架的最终一步,旨在精准定位恶意行为并提供进一步分析的依据。
7 理论分析
需要再说吧。
8 实验评估
8.1 使用的数据集
使用的数据集类型
加密的攻击流量:
这些流量通常使用TLS或IPSec等加密协议进行传输,具有高度的隐蔽性。为了测试系统在应对加密攻击时的有效性,研究人员使用了多种模拟攻击流量,包括但不限于SSL攻击、加密的网络爬虫流量、以及通过TLS加密的垃圾邮件传播流量。
恶意软件生成的加密流量:
这类流量通常是低速且持续性的,如恶意软件组件的更新、命令与控制(C&C)通道、数据泄露等。为了模拟恶意软件活动,研究人员使用了实际恶意软件感染的数据,例如恶意软件的C&C流量、数据泄露流量等。
具体的数据集来源
MAWI 流量数据集:
MAWI(Measurement and Analysis on the WIDE Internet)是一个公共的流量数据集,用于研究网络流量特性。研究人员在实验中使用了2020年1月收集的MAWI数据集,其中包含了大量的互联网流量数据。
ISCX VPN-NonVPN 流量数据集:
ISCX(Information Security Center of Excellence)VPN-NonVPN数据集是一个常用的数据集,包含了不同类型的网络流量,包括VPN和非VPN流量。该数据集用于评估系统在区分VPN与非VPN流量时的表现。
Kitsune 数据集:
Kitsune 数据集是一个广泛用于异常检测和恶意流量检测的公共数据集。它包含了许多不同类型的攻击流量,包括洪水攻击、端口扫描等。
CIC-IDS2017 数据集:
CIC-IDS2017 数据集是一个综合性的数据集,包含了多种恶意行为和网络攻击。它被用于网络入侵检测系统(IDS)的性能评估。
CIC-DDoS2019 数据集:
CIC-DDoS2019 数据集是一个专门用于分布式拒绝服务攻击(DDoS)检测的数据集,包含了多种DDoS攻击流量和背景流量。
实验流量的生成
模拟恶意流量:为了使实验更贴近真实世界,研究人员模拟了各种真实的攻击行为,包括暴力破解攻击、加密洪水攻击、加密恶意软件流量、以及探测漏洞的低速攻击流量。通过对这些流量进行捕获和重放,研究人员生成了实验所需的数据集。
混合背景流量:为了更好地模拟实际网络环境,研究人员将恶意流量与背景流量混合重放。背景流量主要来自公共数据集,如MAWI和ISCX数据集,并结合了现实世界的互联网流量特性。
数据集大小与流量量级
数据包数量:每个数据集包含约1200万至1500万数据包,实验时间为45秒。
流量速率:恶意加密攻击流量的速率范围为0.01至8.79千包每秒(Kpps),仅占用了0.01%至0.72%的带宽。
数据集分析的目的
研究人员使用这些数据集进行了一系列实验,以评估系统在不同攻击场景下的表现,包括检测精度、资源消耗、误报率等。实验结果显示,系统在处理各种加密攻击流量时表现出色,尤其是在面对低速和隐蔽的恶意流量时。
8.2 实验效果
多种检测方法在不同数据集下的平均精度。
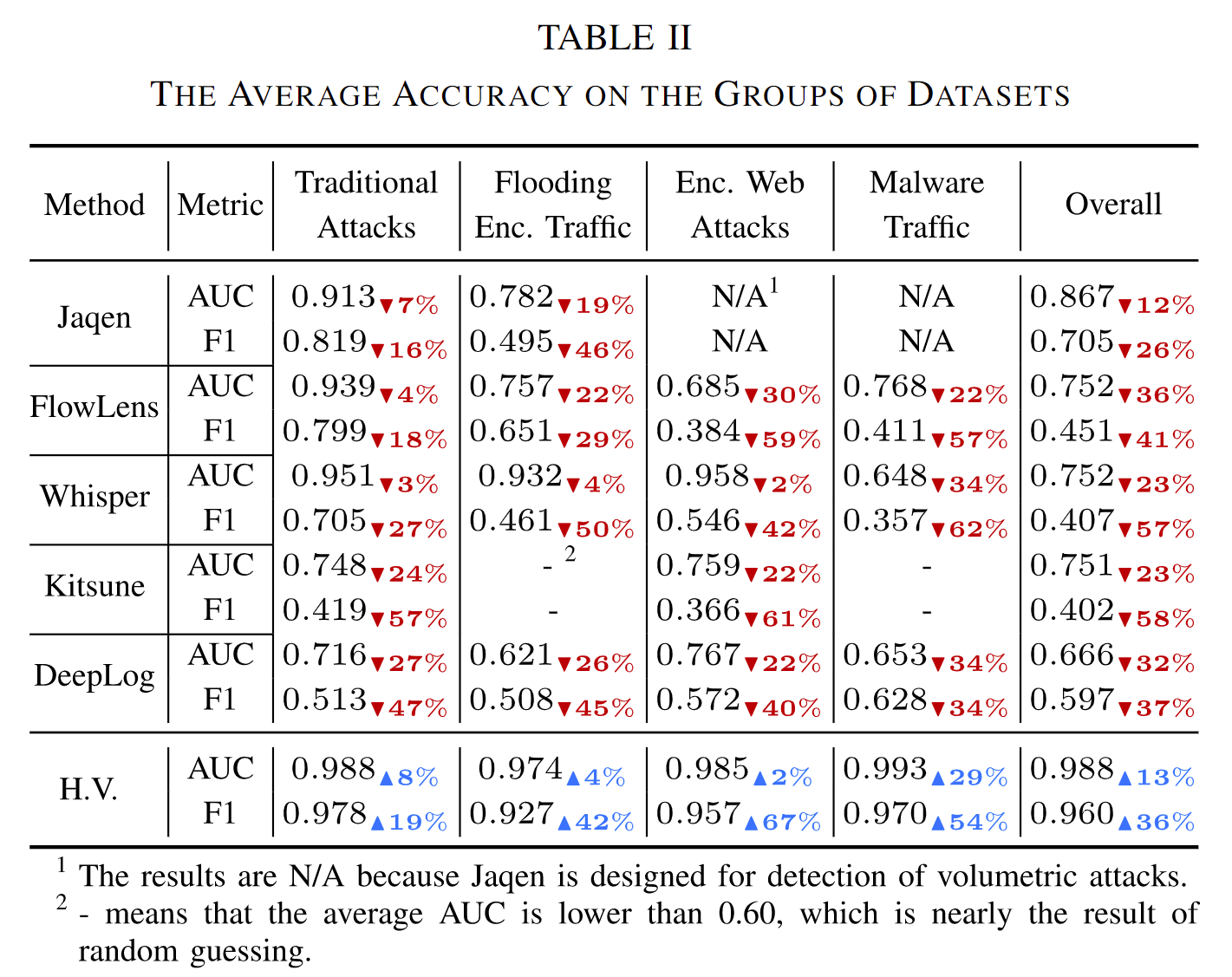
HyperVision与几种基线方法在检测传统暴力攻击(Brute Force Attacks)方面的准确性对比。图表对比了不同方法在多种攻击类型(如暴力扫描、放大攻击、源地址伪造的DDoS攻击)下的检测性能,使用了两个主要指标:AUC(ROC曲线下面积)和F1分数。

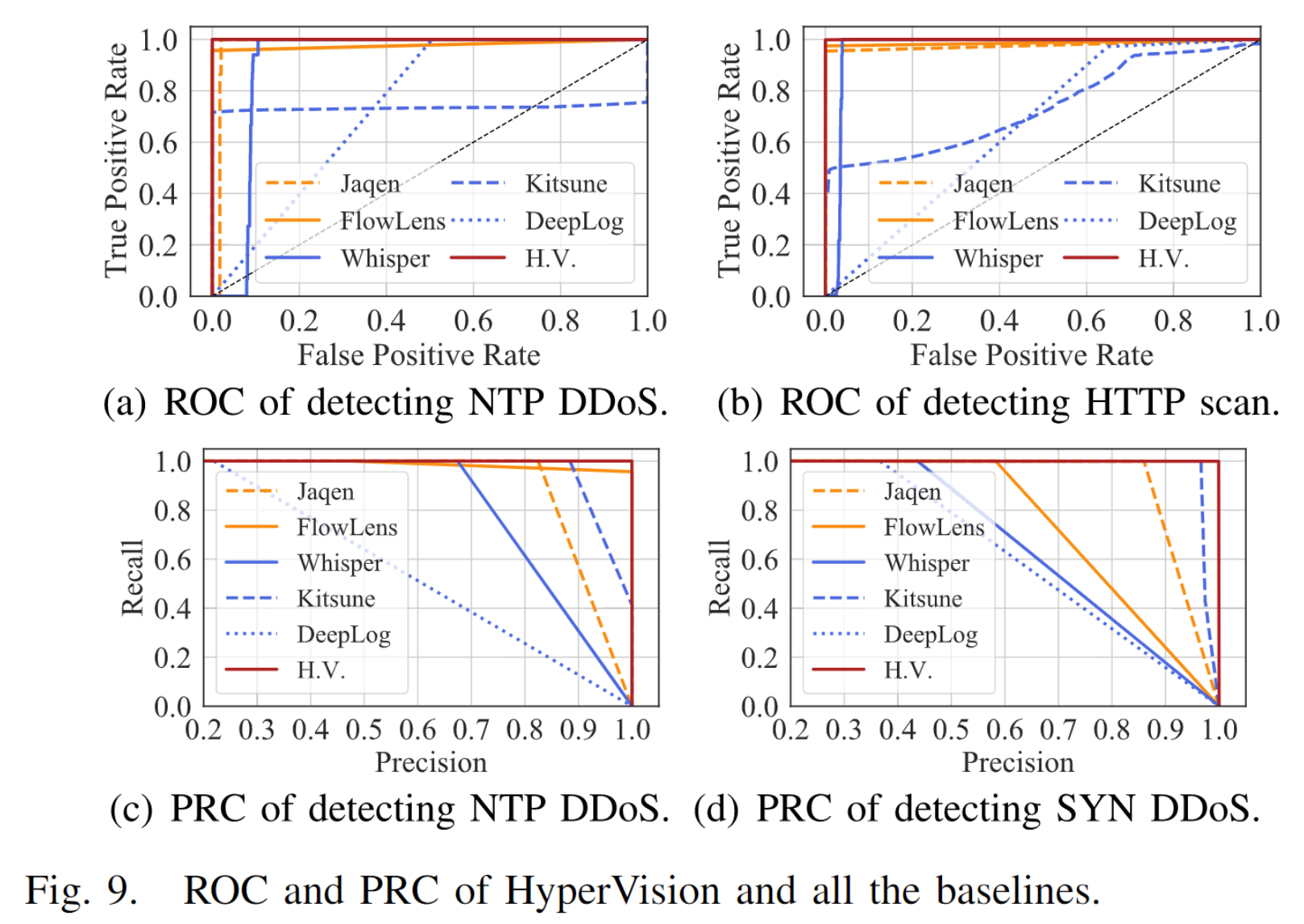
这个图表展示了不同检测方法在应对NTP DDoS攻击和HTTP扫描攻击时的性能比较,分别使用了ROC曲线和PRC曲线进行分析。
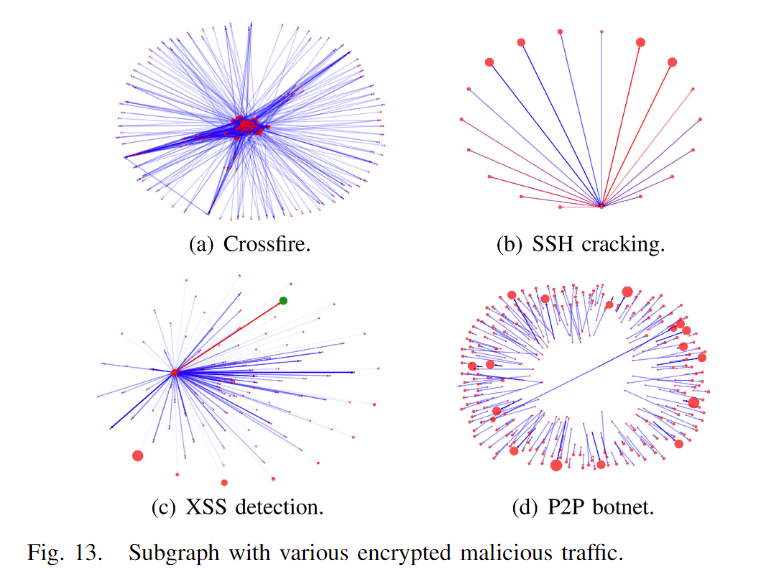
下面这张图展示了不同类型的加密恶意流量在图结构中的表示,展示了四种常见的攻击类型:Crossfire攻击、SSH暴力破解、XSS(跨站脚本)检测以及P2P僵尸网络。
蓝色边:代表正常的(非恶意的)流量。这些边连接的节点通常代表合法的网络活动。
红色边:代表检测到的恶意流量。这些边连接的节点通常代表被检测为异常的恶意行为。
红色节点:这些节点通常表示被识别为与恶意活动相关的关键节点(如攻击者或被感染的主机)。它们是连接红色边的主要节点。
绿色节点:在XSS检测子图(图13(c))中,绿色节点表示攻击者的起点,它们与许多红色边相连,表明该节点是恶意流量的来源。
9 相关工作
9.1 基于图的异常检测
(Graph Based Anomaly Detection)
任务特定的流量检测:已有的方法主要依赖于深度包检测(DPI)来构建图结构用于检测特定的流量类型。这些方法无法应用于加密流量的检测。
相关研究:
Kwon等人分析了下载关系图以识别恶意软件下载行为。
Eshete等人通过构建HTTP交互图来检测静态恶意软件资源。
Invernizzi等人使用从明文流量中构建的图来识别恶意软件基础设施。
HyperVision的区别:不同于上述方法,HyperVision在不解析特定应用层报头的情况下构建交互图,因而可以实现任务无关的加密流量检测。
9.2 基于机器学习的恶意流量检测
(ML Based Malicious Traffic Detection)
现有方法:基于机器学习的检测方法可以检测零日攻击,并且在准确性上优于传统的基于签名的方法。
Barradas等人开发了Flowlens,用于在数据平面提取流量分布特征,并通过随机森林算法检测攻击。
Stealthwatch通过分析从NetFlow中提取的流量特征来检测攻击。
Mirsky等人开发了Kitsune,使用自编码器学习每个数据包的特征。
限制:这些方法无法有效检测基于加密流量的攻击。
9.3 任务特定的加密流量检测
(Task-Specific Encrypted Traffic Detection)
现有方法:现有的加密流量检测方法依赖于领域知识,主要通过短期的流级特征进行检测。
例如,Zheng等人利用SDN实现了Crossfire攻击检测,Xing等人设计了可编程交换机的原语来检测链路洪水攻击。
Bilge等人通过分析流量历史来检测C&C服务器,Anderson等人研究了通过检测畸形的TLS头来识别恶意加密通信的可行性。
HyperVision的贡献:HyperVision是首个能够针对未知模式的加密流量进行无监督检测的系统。
9.4 加密流量分类
(Encrypted Traffic Classification)
HyperVision的目标:HyperVision旨在根据加密流量识别恶意行为,这与加密流量分类有所不同,后者主要决定流量是否由特定应用或用户生成。
相关研究:
Rimmer等人利用深度学习进行网络指纹识别,旨在通过分类加密的网络流量来去匿名化Tor流量。
Siby等人展示了分类加密DNS流量可能会损害用户隐私。
Bahramali等人分类了即时通讯应用的加密流量。
Ede等人设计了半监督学习方法用于移动应用的指纹识别。
HyperVision的区别:这些分类任务与HyperVision的目标是正交的,即它们关注的重点不同。
10 全文总结
在本文中,我们提出了HyperVision,这是一种基于机器学习的实时检测系统,用于检测具有未知模式的加密恶意流量。HyperVision利用图来表示流量交互模式,而无需事先了解流量的具体特征。具体而言,HyperVision使用两种不同的策略来表示由短流量和长流量生成的交互模式,并聚合这些流量的信息。我们开发了一种无监督的图学习方法,通过利用图中的连通性、稀疏性和统计特征来检测流量。此外,我们建立了一个基于信息理论的分析框架,以证明HyperVision在有效检测中保留了接近最优的信息量。通过对92个真实世界攻击流量数据集的实验表明,HyperVision实现了至少0.86的F1分数和0.92的AUC,并且检测延迟为0.29秒。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝