


企业信用评级综述
0 摘要
企业信用评级(CCR)在当代经济和社会发展过程中发挥着非常重要的作用。如何使用信用评级方法对企业进行评估一直是一个值得讨论的问题。通过阅读和研究国内外相关文献,本文对CCR进行了系统的综述。本文从统计模型、机器学习模型和神经网络模型三个层次梳理了CCR方法的发展脉络,概述了CCR常用的数据库,并深入比较了各模型的优缺点。最后,本文总结了当前研究中存在的问题并展望了CCR的未来发展。与现有的CCR综述相比,本文阐述并分析了近年来神经网络模型在该领域的进展。
关键词:企业信用评级(Corporate credit rating),统计方法(Statistical method),机器学习(Machine learning),神经网络(Neural network)
1 企业信用评级的研究背景
1.1 定义
到目前为止,尚未有一个统一的企业信用评级(CCR)概念。它最初来源于债券评级。评级对象是企业根据合同按时履行义务的意愿和能力。评级的目的是评估企业作为债务人的违约风险。被评级的企业主要分为非金融公司(如工业公司、交通运输公司和旅游公司)和金融公司(如保险公司和证券公司)。由于资本流动和组织结构的特殊性,后者的信用风险通常更大,评级工作也更加复杂。
1.2 相关评级机构
目前,全球最著名的三大信用评级机构是标准普尔(S&P)、穆迪(Moody's)和惠誉(Fitch)。标准普尔(S&P)已有超过160年的历史,在行业中处于领先地位,业务覆盖全球126个国家和地区。S&P 于2019年进入中国信用评级市场,每周更新各国和地区的主权信用评级。穆迪(Moody's)已有120多年的历史,源自邓白氏(Dun & Bradstreet),其评级覆盖全球100多个国家和地区,并于2001年进入中国市场。惠誉(Fitch)也有100多年的历史,规模略小于S&P和穆迪,评级范围覆盖全球70多个国家和地区,并于2020年获准进入中国市场。除这三家美国机构外,中国的评级机构也在发展中,如大公国际信用评级、联合资信和金诚信评级等。然而,由于中国的评级机构起步较晚,评级方法方面仍有很多工作要做。专家和学者们在建立信用评级模型时使用了多种数据集。表I列出了常用的数据集。
表I 企业信用评级常用数据库
| 数据库 | 简介 |
|---|---|
| Reset | 中国的一个综合数据平台,提供全球金融市场数据,主要包括股票、黄金、研究报告、宏观统计等系列数据。 |
| 上市公司财务报告 | 披露上市公司业务概况和财务状况等信息的报告。 |
| 中国人民银行信用调查系统 | 中国最完整的企业和个人信用调查数据库。 |
| CSMAR | 根据中国国情建立的经济金融领域研究型数据库,涵盖18个系列,如因子研究、绿色经济、股票、信息和基金。包括160多个数据库,超过4000张表,超过50000个字段。 |
| WRDS | 由宾夕法尼亚大学沃顿商学院于1993年开发的跨数据库金融领域研究工具,整合了许多著名的数据库,如Compustat、CRSP、TFN和TAQ。 |
| Bloomberg | 全球最大的金融信息和金融数据服务提供商。 |
| FAME | 覆盖英国和爱尔兰的380万家公司。 |
| UCI 机器学习知识库 | 加利福尼亚大学欧文分校提出的机器学习数据库。 |
| Compustat | 由标准普尔发布,涵盖了北美及全球上市公司近20年的财务数据。 |
| CRSP | 由芝加哥大学建立的证券和交易领域的上市公司权威数据库。 |
| NEEDS | 日本最大的综合经济数据库。 |
| Bankscope | 由BVD与惠誉评级合作开发的银行信息数据库,作为银行业权威评级机构,提供了全球12800多家主要银行和重要金融机构的经营和信用分析数据。 |
| WIND | 中国企业提供的金融和证券数据库。 |
| Kis-value | 韩国的一个数据库,提供企业报告和股票市场数据分析。 |
1.3 企业信用评级的意义
作为市场经济条件下的社会中介服务,企业信用评级在维护社会和经济秩序方面发挥着重要作用。企业在开发客户时,应该基于对客户信用状况的全面了解,盲目追求大量订单必然会导致坏账。信用评级可以帮助金融从业者规避风险,为投资者和合作伙伴提供客观、公正的信用信息,减少企业的管理压力。为了维护资本秩序的稳定,资本市场管理部门需要定期调查企业。企业信用评级提高了经济管理部门的监管能力,并提升了企业的社会知名度。
与企业信用评级类似的是债券信用评级。虽然两者都旨在促进资源的有效配置,减少评级对象和投资者之间的信息不对称,但它们的评级对象不同。前者针对的是商业银行或相关监管机构,后者则面向债券投资者。由于债券发行的独特性,企业的信用评级通常较高,而企业发行的债券评级可能不高。此外,由于债券评级机构需要经过信息收集、处理、二次评级和跟踪评级等多个阶段,信用风险的变化往往不能及时响应。因此,金融机构建立自己的信用评级系统非常重要。然而,评级机构的完整、详细的评级需要大量的人力、资本和时间【1】,这是大多数企业和金融从业者难以承受的。因此,为投资者建立一个准确的企业信用评级模型显然具有重要价值。
目前,许多专家和学者对企业信用评级模型进行了详细研究,但对于这些模型的整体综述相对较为不足。近年来,基于神经网络的评级模型综述较少。本文结合传统的统计模型、机器学习模型和近年来热门的神经网络模型,对企业信用评级进行了全面的综述。
2 基于不同模型的企业信用评级
2.1 统计模型
大多数用于评估金融领域企业信用风险的传统模型基于统计情境,并源于企业破产预测模型。这些模型基于企业的财务指标(如资产负债结构、现金流、盈利能力、资产流动性等)建立评级指标体系,然后使用统计方法分析这些指标体系的特征,完成企业信用评级的分类。常用的指标列于表II中。

以下是一些常用的统计模型:
- ZETA:Zeta模型最初用于评估企业破产风险,后来被广泛应用于信用评级领域。该模型的评价指标体系基于七个维度:资产回报率、收入稳定性、债务偿还能力、累计盈利能力、流动性、资本化程度和规模。文献【2】结合判别分析算法并引入先验概率来分析信用价值。然而,Zeta模型的七个指标是固定的,不能涵盖所有评级要素。之后,广泛使用的特征工程本质上是在寻找适合描述评级问题的因素指标。
- AHP:层次分析法(AHP)是将决策过程分解为多个层次进行定性和定量分析的方法,广泛应用于信用评级【3】。目前,它被用来确定参数的重要性顺序。为了平衡AHP方法的主观性,文献【4】结合了客观的DEA来评估信用水平。对于难以完全定量分析的复杂系统,层次分析法具有明显优势。然而,层次分析法要求决策者自行比较指标并判断其相对重要性,这不仅引入了更多的主观元素,当指标较多时,也难以判断哪个更重要。
- MDA:多元判别分析(MDA)是一种根据原始数据集分析新数据类别的统计方法,广泛应用于信用评分模型。判别方法可以分为距离判别法、Fisher判别法、贝叶斯判别法、逐步判别法等。Reichert等人【5】指出,大多数MDA模型假设变量服从多元正态分布。如果数据的真实分布显著偏离正态分布,分类结果将会产生严重偏差。基于MDA创建的Z-score模型最初用于企业破产分析,后来用于信用风险评估【6】。与前两种方法相比,MDA方法更多地考虑了数据的科学性,受分析师主观态度的影响较小。然而,MDA模型的分类结果在数据集较小时更为准确。此外,MDA模型没有使用与估算样本统计独立的数据来验证评级的准确性,导致验证结果偏差。MDA模型假设所有类别的方差-协方差矩阵相等,而这与现实不符。
- MARS:多元自适应回归样条(MARS)【7】也用于信用评级。与适用于小数据集的MDA模型相比,MARS可以准确快速地处理大量企业信用评级问题。更显著的是,MARS还可以捕捉变量之间的非线性和交互作用。然而,与其他模型相比,MARS在企业信用评级中的应用较少。
- LR:逻辑回归是一种由线性回归理论支持的非线性模型,常用于处理二元分类问题。Laitinen等人【8】使用逻辑回归和线性回归模型分析企业信用风险。West等人【9】结合经典因子分析和多元logit估计,构建了一个商业银行预警系统。作为一种广泛使用的分类算法,它速度快,适用于非线性分类,常与其他算法结合用于信用评级问题。
- 其他:文献【10】结合了定性和定量指标,为小企业建立了信用评估指标体系。该体系的指标权重通过基于蚂蚁化学识别系统的增量聚类算法生成。实验表明,聚类算法适用于高维特征。Shi等人【11】使用Pearson相关分析和F检验显著性判别来筛选小企业融资能力的关键特征,以兼顾分类准确性和计算效率。由于模糊TOPSIS方法的简单性和排序能力,它也被用于企业信用评级【12】。
纵观基于统计模型的历史,除了少数传统模型,所有模型都擅长处理线性关系,而不善于处理非线性关系。大型评级机构在确定评级模型参数或直接信用评级时,通常重视分析师主观判断的重要性。尽管这些传统方法基于统计和数据分析,但它们在企业信用评级上受到了人为因素的影响。此外,传统模型(如逻辑回归和KMV)在执行评级任务时,往往对数据集的参数分布做出假设,而这些假设可能与真实的数据分布相悖。机器学习模型为这些问题提供了答案。
2.2 机器学习模型
2.2.1 SVM
支持向量机(SVM)是信用评级领域中使用最广泛的模型之一。Huang等人【1】使用SVM对信用评级市场进行了比较研究,得出SVM比逻辑回归模型具有更高的准确性。他们发现,使用小而精确的指标数据集来进行信用评级,比使用包含广泛指标的财务数据集的结果更为准确。研究还比较分析了美国和台湾评级机构关注的指标数据,发现美国更关注公司的规模,而台湾则更关注公司的盈利能力。这与美国公司推崇高杠杆运营的方式相一致。不同于传统的统计学习模型,SVM强调评级方法的客观性,财务变量能比机构分析师更好地决定评级结果。特征工程的应用常常可以提高SVM的准确性,尽管这提升了SVM的上限,但也限制了SVM在信用评级领域的发展。
SVM最初是为二分类设计的。简单的二分类不适合企业信用评级,因为企业的信用评级并不是绝对的好或坏。模糊SVM(Fuzzy SVM)【13】为正负类别的每个样本分配不同的隶属度,从而增强了SVM的泛化能力。随后,随着多类支持向量机(MSVM)的发展,"一对一"、"一对多"和有向无环图SVM(DAGSVM)算法被用于企业信用评级。文献【14】使用上述三种多类SVM方法对公司债券评级进行研究,得出DAGSVM表现最佳。为了实现非线性样本的分类,RBF核函数被用来增加输入空间的维度。文献【15】使用具有RBF核函数的SVM对企业信用评级进行分类,并通过网格搜索技术找到了RBF核函数的最佳参数值。实验【13】表明,具有适当核函数和隶属度生成方法的SVM比标准SVM和模糊SVM在信用评级中具有更高的准确性。
然而,企业信用评级并不是一个简单的分类问题,其分类结果之间存在顺序关系。考虑到信用评级的独特顺序,提出了基于有序成对划分(OPP)策略的SVM【16】。为了优化模型参数,遗传算法(GA)也被引入SVM中。GA-SVM【17】通过网格搜索设置模型参数,并通过遗传算法优化参数。但SVM始终是一个"黑箱"问题,理解SVM的原理将提高模型的实用性。为了提高SVM的可解释性,CRCR-SVM【18】通过借鉴传统规则学习方法的覆盖约简算法进行训练。
此外,SVM经常用于特征选择。由于指标之间的相互依赖性,特征选择过程非常复杂。企业信用评级依赖于多变量因素。Fisher方法是一种常用的特征选择方法,该方法易于实现且速度快,但没有考虑变量与分类器之间的相互作用。其他双样本独立性度量,如KS检验和卡方检验,通常得出与Fisher分数相似的结果。为了避免特征排序方法所需的额外校准步骤,Maldonado等人【19】使用两种SVM方法(L1-MISVM、LP-MISVM)来获得银行信贷数据的最佳特征子集。在构建分类器时,该方法将考虑所有变量的交互以及它们之间的关系。文献【14】提出,特征选择可以进一步提高SVM的泛化性能。与遗传编程和决策树分类器相比,SVM的输入准确性较少依赖于大量输入特征【17】。
2.2.2 决策树
决策树(DT)是一种可解释性强且构建快速的算法。在企业信用评级中,ID3和gdbt算法都被使用,后者效果更佳【20】。结合集成学习和决策规则的方法,相关性调整决策森林(CADF)【21】平衡了模型的准确性和可解释性。该方法使用决策树作为基分类器,并选择了18个最重要的特征用于信用风险评级。穆迪KMV模型(KMV)是基于金融理论和违约概率的著名信用评级分析模型。混合KMV模型【22】将KMV与随机森林(RF)和粗糙集理论(RST)相结合,改善了信用评级的准确性。RST不对数据的分布做任何假设,适用于定量和定性分析。当决策过程涉及不确定的模糊数据时,RST在解决决策支持问题上取得了显著的成果。首先,使用KMV预测变量,然后由RF选择这些变量作为RST模型的输入。最终,模型以if-then规则的形式生成结果。这一过程透明且便于决策者理解。然而,该方法必须优化一些参数来构建RF的基分类器。由于财务数据的高维度、稀疏性和强相关性,DT模型的性能受限。在后续研究中,DT通常作为信用评级模型的基准或与其他算法结合使用。
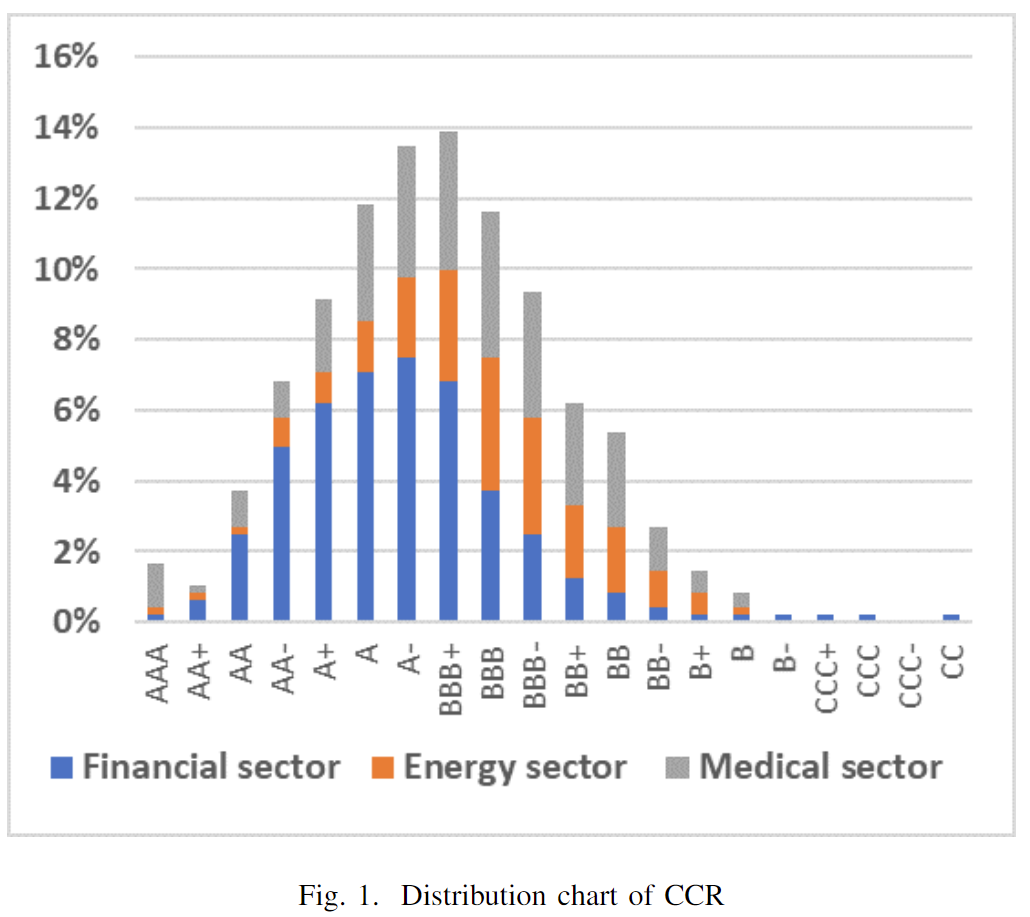
2.2.3 集成学习
集成学习并不是一种单一的机器学习算法,而是通过结合多个基学习器共同完成学习任务的思想。由于集成学习在分类任务中的出色表现,该算法在企业信用评级任务中也取得了很大进展。集成学习的基本思想是,当我们做出重要决策时,需要参考来自不同方面的各种意见。通过权衡多方面意见做出的决策往往比仅参考单一意见做出的决策更为恰当。因此,基学习器除了具备一定的准确性外,还应该具有相互之间的多样性。当基学习器给出的意见是互补的,集成学习算法通常能取得更好的结果。Abellan和Castellano【23】提出的信任决策树(CDT)改变了处理不确定性的方式。他们使用不精确概率和不确定性度量来构建模型,并使基分类器相对不稳定。所谓不稳定性是指训练数据的微小变化会在模型中产生较大的差异,从而导致基分类器的多样性,这非常适合集成学习。
近年来,许多专家将神经网络方法与集成学习相结合,应用于企业信用评级任务。Donate提出,在企业信用评级任务中,集成多个神经网络的模型比仅使用单一神经网络更为有效。通过加权多基学习器的集成策略比不加权策略更为准确,这证明了使用集成算法的神经网络方法的巨大潜力【24】。为了确保基学习器之间的差异,Yu等人【25】提出的多阶段神经网络集成学习模型采用了去相关最大化的方法在选择ANN时使用,然后将每个单一基学习器的决策值从(−∞, +∞)缩放至(0, 1)。接着,基分类结果分别使用最大、最小、中位数、平均和乘积策略进行集成。结果显示,乘积策略表现最佳,其次是平均策略。该结果的原因仍待进一步探讨。
常用的集成学习算法包括多数投票、加权平均、Bagging、Boosting、随机子空间、DECORATE、Rotation Forest等。多数投票算法使用最广泛,但它忽略了少数派有时会产生正确结果的事实。多数投票算法将每个神经网络的置信度视为相同。在企业信用评级任务中,可用的样本数据通常有限,而Bagging算法通过从原始训练集中随机抽取子集,以统计方式生成对整体数据集的更多估计。抽样在一定程度上弥补了训练数据的局限性,通常可以改善分类效果【25】。
此外,企业信用评级数据的类别严重不平衡。Brown和Mues提出了随机森林(RF)和梯度提升算法,这在缓解这一问题上表现良好。然而,He等人提出,在解决企业信用评级数据不平衡问题时,RF或梯度提升模型的参数需要进一步优化【26】。他们扩展了BalanceCascade方法,根据训练数据的不平衡率生成可调整的平衡子集,并构建了一个以RF和XGBoost为基分类器的三阶段集成模型。三阶段集成模型将前一层的预测结果作为下一层的新解释特征,并通过粒子群优化算法优化基分类器的参数。然而,EBCA阈值的选择仍需进一步研究。特征工程也用于人工神经网络集成模型。考虑到历史财务数据和信用评级对当前信用评级的影响,Wang等人【27】构建了基于集成学习的并行人工神经网络(PANNs),其经典而简洁的框架如图2所示。他们扩展了特征空间,其中差异和一阶变化能够更好地预测信用评级分数。
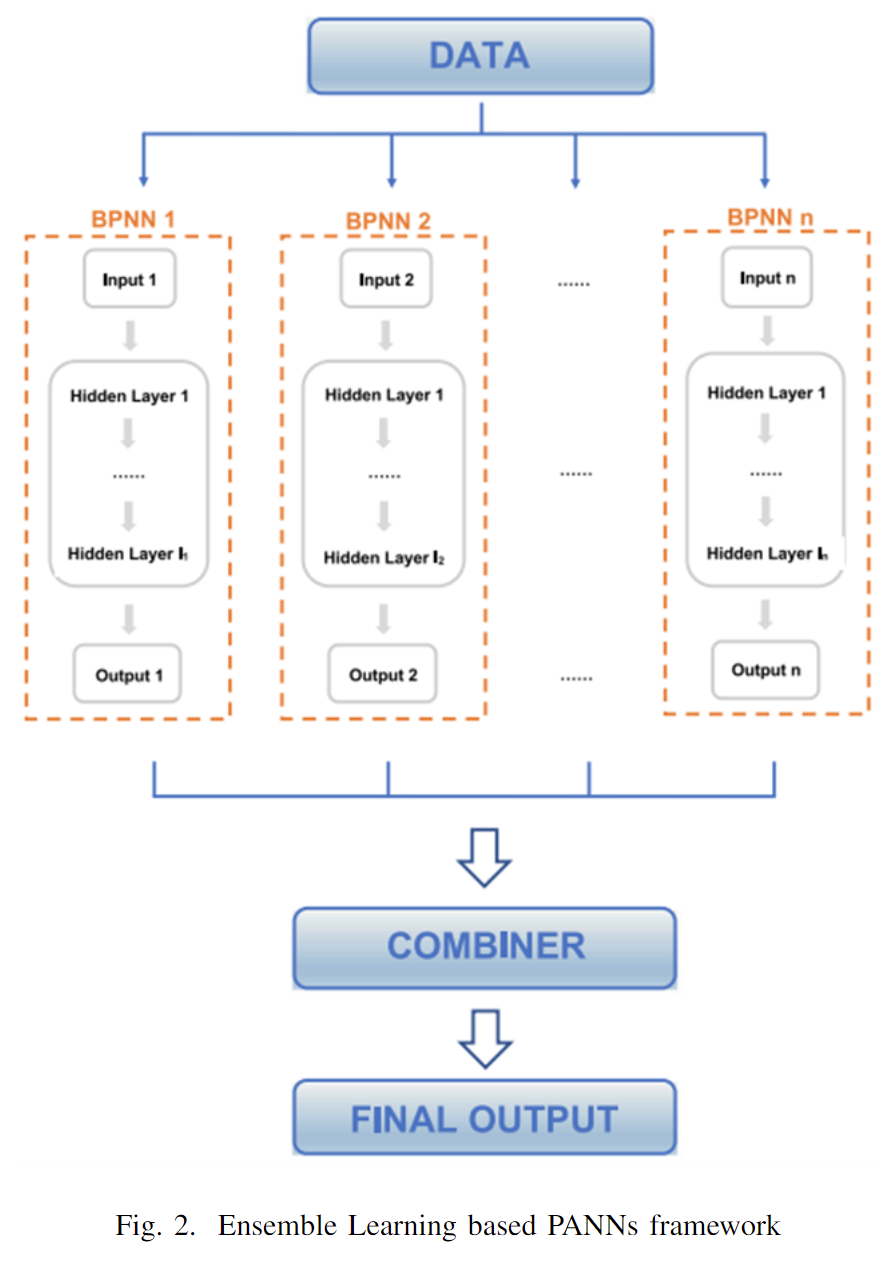
然而,如何确定集成学习方法中基分类器的数量和形式,并使其更适合企业信用评级,仍有待研究。集成学习集成了许多基分类器,其训练时间也呈指数增长。未来需要权衡基分类器数量与训练时间的平衡。虽然结合多个基分类器的模型能够从多个方面考虑问题,但集成策略也难以同时适应所有基分类器。如何提高包含多个基分类器的模型性能是集成学习方法未来的研究方向。Wang等人【27】的实验结果表明,神经网络集成模型的准确性并不总是随着数据量的增加而显著提高。一种可能的解释是,更多的财务数据会引入更多噪声。在未来的研究中,我们可以通过减少噪声获得更有用的数据集,从而提高预测准确性。
2.2.4 其他
为了提高模型的可解释性,文献【28】基于知识系统生成决策规则,并使用粗糙集(RS)构建了两个混合模型对银行业的信用评级进行分类。Chai等人【29】对小企业进行了信用评级研究,发现非财务因素对小企业的影响大于财务因素。在构建信用指标体系时,他们首先使用三角模糊数将定性数据转换为数值,然后使用偏相关分析(PCA)和Probit回归算法消除冗余指标。在分类阶段,该研究使用TOPSIS算法计算信用评分,随后使用模糊C均值(FCM)算法对小企业的信用评分进行聚类。
2.3 神经网络模型
从机器学习模型来看,虽然这些模型比之前的统计模型更加客观,但它们只使用定量数据,在一定程度上忽略了定性数据带来的信息。在企业信用评级问题中,诸如文本的定性数据包含大量的风险信息。此外,这些模型过度依赖特征工程,好的特征会显著提升模型的效果。神经网络模型为这些问题提供了很好的解决方案。
2.3.1 早期神经网络(NN)
在神经网络被广泛应用之前,特征工程一直是金融工程,尤其是企业信用评级的焦点。在早期的机器学习算法中,使用特征工程获得的新特征比使用原始特征的评级结果更为准确。Chen等人【30】使用单因素方差分析(ANOVA)的统计方法选择特征,揭示了虽然统计方法可以提高训练集上的分类准确性,但也带来了噪声,导致过拟合。
然而,由于NN在训练过程中会为特征赋予不同的权重,重要特征会被选作重点项。Golbayani等人【31】发现,在使用所有财务变量作为输入并在NN训练过程中进行特征工程时,评级结果更加准确。与统计方法和机器学习方法相比,NN不假设数据分布。早期的NN(如多层感知器,MLP)需要手动调整学习率,并避免陷入局部最小值。
与传统的机器学习方法相比,MLP可以有效处理高维数据和非线性关系。Brennan等人【32】利用财务报表中的信息构建了一个反向传播神经网络(BPNN)来对发行债券的公司进行评级,发现使用BPNN获得的结果比传统统计方法准确得多。Huang等人【1】使用BPNN模型解释企业信用评级,并试图从模型中分析不同输入财务变量的重要性。Angelini等人【33】认为,数据分析与处理以及参数优化是解决公司信用评级的关键和难点。他们使用经典的前馈神经网络以及一个带有特殊连接的前馈神经网络来评估信用风险。后者由四层前馈网络组成,每组由三个神经元连接到下一输入层。然而,MLP模型的收敛速度慢,过程不稳定。MLP更适合二分类,但在多类分类中的准确性较低。此外,传统BPNN算法在网络中训练大量参数,容易导致过拟合且训练时间较长。
文献【1】【15】【16】【17】指出,在信用评级中,NN的表现不如SVM。Choi等人认为,这可能是因为SVM在避免过拟合问题方面更为健壮,且与NN相比,SVM的参数较少【34】。Du等人【35】认为遗传算法可以修改和优化神经网络的参数,并提高企业信用评级的准确性。遗传算法信用评级模型在一定程度上缓解了BP神经网络的长训练时间、收敛速度慢以及陷入局部最小值的可能性问题。基于经典前馈网络模型的神经网络模型相继被提出。深度网络神经结构(DNN)由多个浅层神经网络组成,随着网络层数的增加,DNN在训练中会出现梯度消失,优化函数越来越容易陷入局部最优解,训练效率也大大降低。直到2006年,Hinton提出逐层训练受限玻尔兹曼机(RBM)的方法,解决了上述问题。这种结构被称为深度置信网络(DBN)。Luo等人首次使用DBN对企业信用评分进行了研究【36】,其分类性能优于多项逻辑回归(MLR)、多层感知器(MLP)和SVM。此外,Kim等人【37】使用自适应学习网络(ALN)预测债券评级。文献【38】使用概率神经网络(PNNs)对美国公司和地方政府进行评级。数据预处理阶段使用了基于相关性的方法和遗传算法。他们发现,PNNs的结果比其他基准分类器(如NNs、级联相关神经网络、统计方法(LR、MDA))更加准确。概率神经网络是径向基函数网络的一个分支,属于前馈网络的一种。它结合了密度函数估计和贝叶斯决策理论,使得判定界面接近贝叶斯最佳判定界面。其具有学习过程简单和训练速度快的优点。
2.3.2 CNN
卷积神经网络(CNN)是为了解决DNN参数爆炸问题而产生的,已被证明在各种金融问题中明显优于传统机器学习技术,尤其是在股票市场分析领域【39】【40】【41】。CNN主要由卷积层、池化层和全连接层组成,通过反向传播算法进行训练。Golbayani等人【31】是首次将CNN用于企业信用评级的研究者。他们提出了CNN模型和带有dropout和early stopping算法的CNN2D模型来解决企业信用评级问题。这两个模型都由两个卷积层和两个全连接层组成,区别在于CNN模型中的滤波器仅在一个方向上移动,而在CNN2D模型中滤波器在两个方向上移动。该研究还提出了一个双向ANOVA模型,用于比较网络架构的多重性能。此外,并非所有公司每年都能提供信用评级分数或财务信息。与MLP相比,由于CNN在调整特征权重方面的高效性,CNN在处理缺失数据问题上取得了良好的效果。各种派生的CNN模型广泛应用于计算机视觉(CV)和自然语言处理(NLP)领域,但它们不适合金融场景。早期的NN模型只提取了企业数据的一维特征。受CV领域的启发,Feng等人【42】构建了一个CCR-CNN模型,生成包含每个企业二维财务信息的图像,将其输入到CNN结构中,获得分类结果。该模型的优点是捕捉到了企业指标之间独特的二维关系,并生成图形,这是之前模型所忽略的。然而,企业信用评级是动态的,并且与时间因素密切相关。RNN是建立连续企业信用评级模型的一个很好的算法。
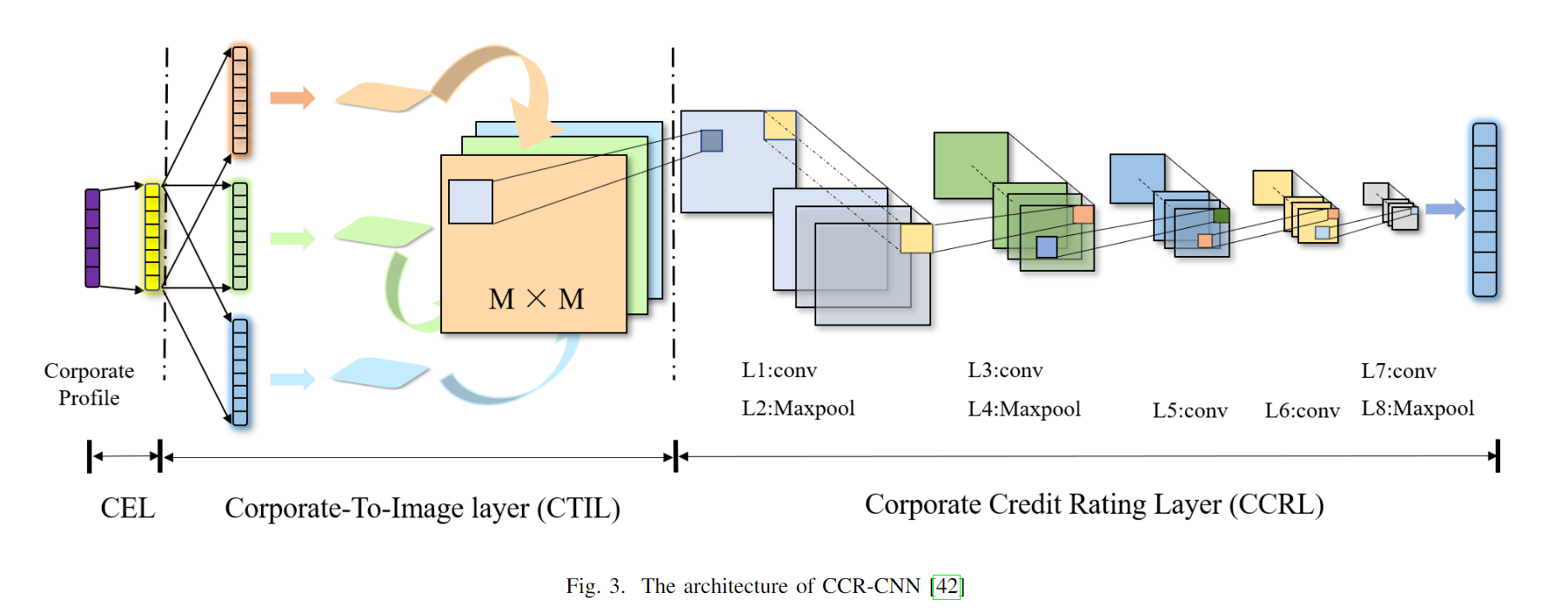
2.3.3 RNN
尽管循环神经网络(RNN)在时间序列问题研究中取得了显著成果,但由于反向传播算法导致的梯度消失和梯度爆炸问题,为RNN的训练带来了很大困难。长短期记忆网络(LSTM)是RNN的一个变体,它通过门控机制将短期记忆与长期记忆相结合,在一定程度上解决了梯度爆炸和消失的问题。然而,LSTM的计算复杂度高,结构精密。RNN的门控循环单元(GRU)在确保相当准确率的同时可以节省计算成本。
注意力机制被提出以进一步节省计算成本。注意力机制的原理是通过分配权重,从大量信息中选择对当前任务更为重要的信息。注意力分布通过计算向量的相似性或相关性来实现。目前,大多数注意力模型附属于编码器-解码器框架。例如,编码器-解码器结构中的Transformer通过并行计算显著减少了训练时间。此外,还提出了BERT、深度Transformer、Transformer XL等模型。Golbayani等人【31】比较了CNN和LSTM,并通过实验分析证明LSTM在处理企业信用评级问题上更为优秀。他们构建了一个包含32个LSTM单元和两个全连接层的模型。SMAGRU【30】是首个在企业信用评级中实现长注意力机制的工作。其架构基于具有多头自注意力机制的GRU,可以捕捉时间序列特征。SMAGRU由六个相同的模块堆叠而成,每个模块由多头自注意力机制和全连接前馈网络组成。SMAGRU的架构如图4所示。
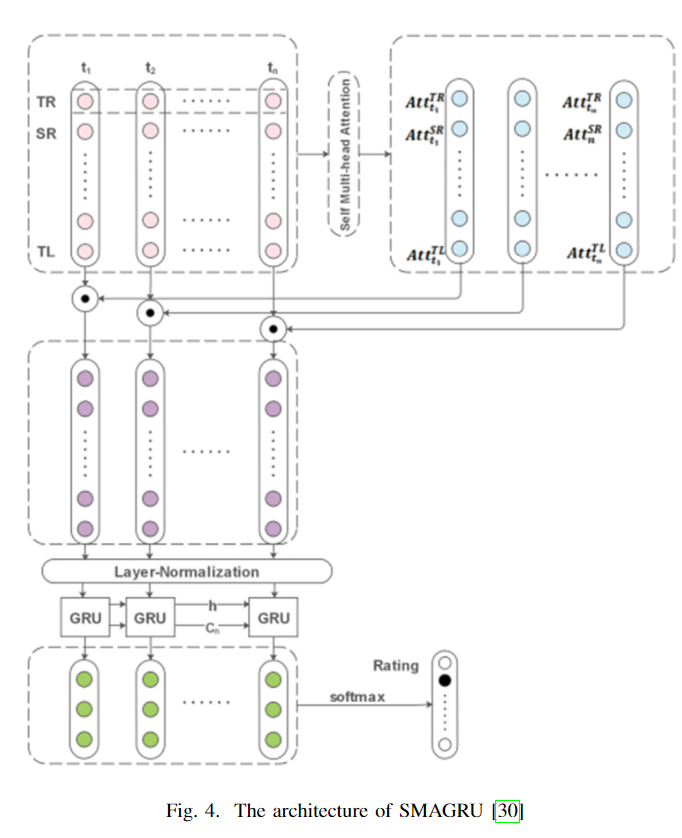
多头注意力类似于CNN中的多个滤波器,有助于捕捉更全面的信息。多头自注意力机制通过增强时间特性,提高了分类准确性和收敛速度。此外,该机制与门控循环神经网络结合后,还能很好地适应高维稀疏数据,非常适合企业信用评级任务。
2.3.4 基于定性信息的模型
大多数评级方法使用定量数据(如财务信息和资本流动性),但定性数据(如公司的战略布局、舆论和管理效率)也对信用评级产生重要影响。信用评级旨在引导投资者未来的决策,但使用的财务数据基于公司过去的运营情况。此外,财务数据无法完全反映企业的经济环境。因此,S&P会通过报告和管理层访谈补充其评级模型。将文本转换为嵌入向量的常用方法包括BOW、Word2Vec和Doc2Vec。BOW(词袋模型)是最早提出的,它将文档视为词语的集合,忽略了词序、语法和句法的因素。BOW假设文档中的每个词是独立出现的,向量的每一维度对应语料库中的词,表示词的重要性。TF-IDF是计算词语相对重要性最常用的方法。
Word2Vec假设上下文中经常一起出现的词语具有相似的含义,将词语嵌入到连续的向量空间中。神经网络训练的目标是根据输入词准确预测目标词。Word2Vec有两种最常见的架构:CBOW模型和Skip-Gram模型。CBOW模型使用相邻词的一次性编码作为输入,并预测目标词;相反,Skip-Gram模型使用词的一次性编码并预测其相邻词【43】。Doc2Vec【44】在Word2Vec的基础上增加了段落向量,可用于嵌入长度可变的文本,如句子、段落和文档。Choi等人【34】使用上述三种文本嵌入方法获取向量,并将这些向量分别输入ANN、SVM和RF模型中。实验结果表明,使用定量财务数据和定性文本数据训练的模型比仅使用前者训练的模型准确性更高。模型准确性从低到高依次为Word2Vec、Doc2Vec和BOW。BOW取得最高准确率的原因可能是训练数据集较小。由于训练数据长度较长,Doc2Vec在处理较长文档时优于Word2Vec。未来,通过使用更大的数据集进行训练是解决该问题的一种方法。Feng等人【45】对定性数据进行一次性编码,然后使用嵌入层将定量财务数据与之连接作为输入。
2.3.5 GNN
当某行业的市场状况不佳时,相关企业的评级结果往往会变差。企业之间的关系也是企业信用评级尚未探讨的影响因素之一。然而,现有的大多数使用图神经网络的模型是基于全局视角对企业进行研究的,它们直接在企业之间建立网络,未考虑单个企业内部特征(如债务和资本结构之间的关系)的相互作用。
CCR-GNN【45】是首个应用图神经网络研究企业信用评级的模型。与将企业简单地视为节点不同,CCR-GNN根据企业内部特征之间的关系为每个企业构建图结构。CCR-GNN包括三层子神经网络。首先,根据特征之间的关系将每个企业映射为图结构。然后,这些特征通过图注意力层(GAT)的相互作用捕获局部和全局的企业信用信息。最后,信用评级层根据这些企业信用信息输出类别。通过叠加多个图注意力层,CCR-GNN可以清晰地探索高阶特征的交互作用。特征节点的企业信用信息根据注意力机制传递到相邻节点。

2.3.6 基于对抗和半监督学习的模型
中小企业的财务信息不足,且缺乏足够的资金支持评级。因此,之前关于企业信用评级的研究仅考虑大企业。然而,中小企业的财务数据也具有研究价值。半监督学习算法为解决这一问题提供了启发。基于相似样本具有相似输出的假设,半监督学习使用标记数据和未标记数据共同训练模型。对抗学习则是指基于对攻击者能力和攻击后果的理解,抵御攻击的机器学习算法。实现对抗学习的方法是让两个网络相互竞争,其中生成器网络通过向样本添加噪声来构造伪数据,而判别器网络则判断数据的真实性。通过反复对抗,生成器和判别器的能力将不断增强。
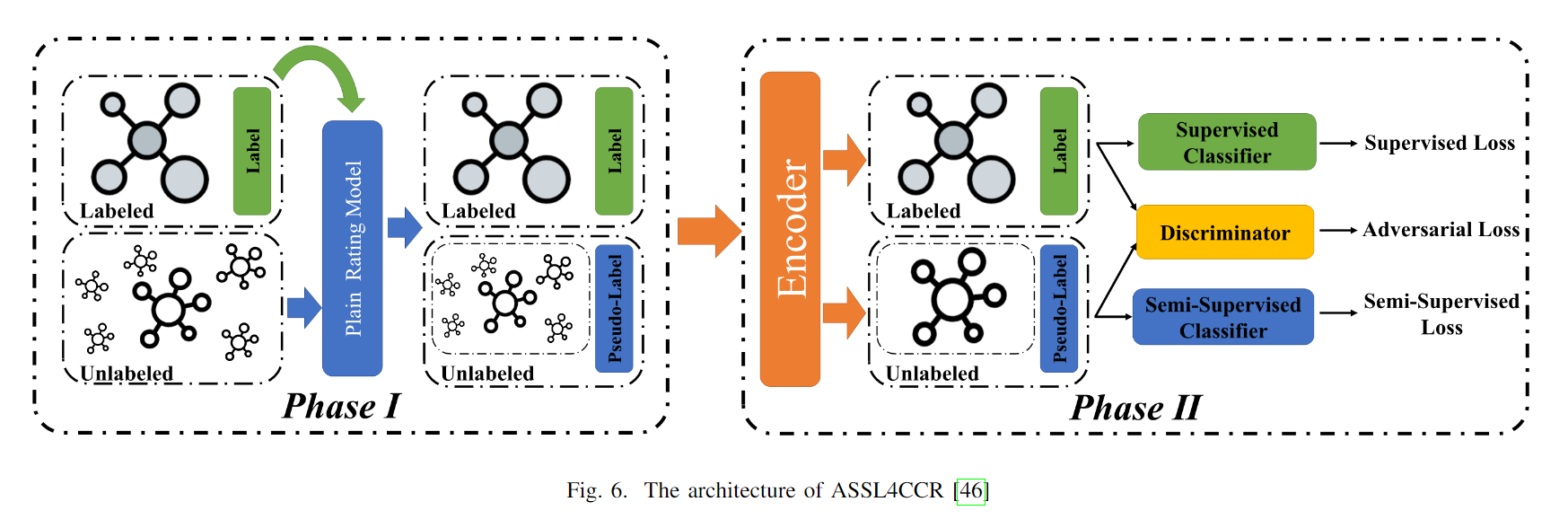
然而,Bojing Feng和Wenfang Xue发现,仅使用半监督学习会导致监督任务和半监督任务之间表示失调的问题。ASSL4CCR【46】引入编码器模块和对抗学习以缓解这一现象。ASSL4CCR包括两个阶段:第一阶段通过半监督学习获取伪标签;在第二阶段,将编码器模块映射后,标记数据与伪标记数据结合使用。判别器模块用于区分数据来自真实标签还是伪标签。
2.3.7 基于预训练和自监督学习的模型
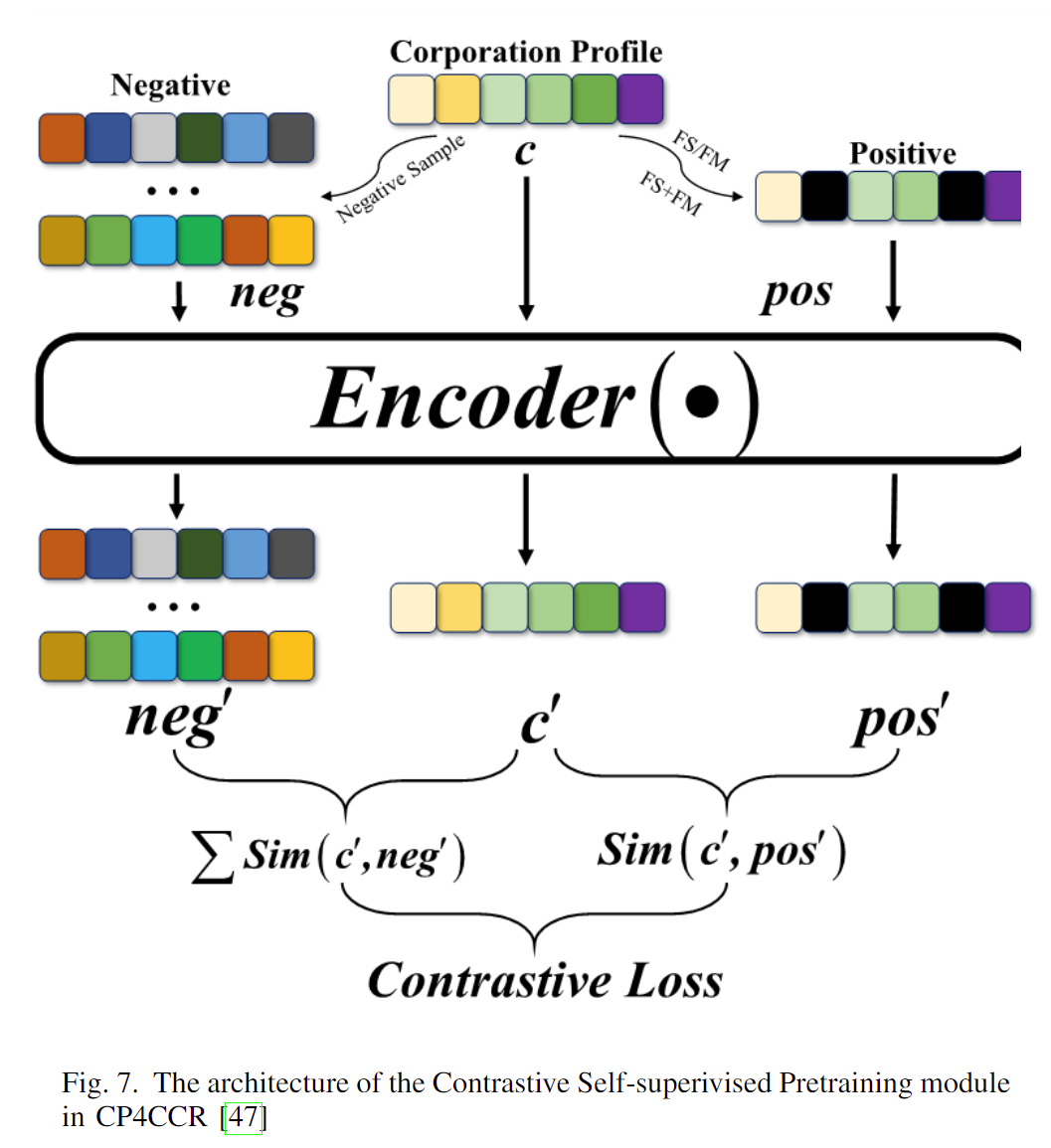
除了集成学习,自监督学习也可以在一定程度上解决企业信用数据集类别不平衡的问题。自监督学习主要通过预任务从无监督数据中挖掘监督信息,并通过构造的监督信息学习对下游任务有价值的表示。CP4CCR【47】采用特征掩蔽和特征交换作为两种自监督任务。在空间堆叠模块中,空间拼接优于空间融合。经过网络预训练后,Transformer是标准企业信用评级模型中更好的编码器模块。
2.3.8 基于可解释性学习的模型
在金融领域,提高模型的可解释性至关重要,以便理解哪些特征对模型的贡献最大。与被称为“黑箱”的深度学习算法不同,可解释性机器学习更适合解决这一问题。机器学习方法的可解释性可分为内在解释和后验解释。内在解释意味着模型本身是可解释的,而后验解释指的是选择并训练黑箱模型(如集成方法或神经网络),然后在训练后应用可解释性方法【48】。

文献【49】提出了一种基于后验解释的稀疏算法,用于企业信用评级。作者试图探讨如何通过最少的更改来达到提高信用评级分数的目标,这被描述为一个优化问题。通过稀疏算法,企业可以以较低成本提高其信用评级。此外,研究还发现,信用评级越高,企业提高其信用评级的难度就越大。图8展示了一个反事实解释的例子。通过解释模型,我们可以探索如何以最小的成本提升信用评级分数。这种思路为企业信用评级模型开辟了新的思路。
一般来说,基于神经网络的模型对特征工程的要求相对较低。它们考虑了评级信息的时间序列变化特征和企业之间的关系。机器学习模型难以捕捉的定性信息也被整合进来。这类模型还缓解了数据分布不均的问题。近年来,这类模型逐渐取代了以往的统计模型和机器学习模型,成为信用评级的主流。然而,神经网络模型更依赖于大量的数据集,其可解释性不高。未来,仍有相当大的发展潜力。
3 结论与未来工作
企业信用评级模型是经济发展不可避免的产物,近年来引起了越来越多的关注。通过总结以往的文献,本文系统地分析了企业信用评级的发展过程。本文从三个方面深入介绍了信用评级方法:传统的统计模型、基于机器学习的企业信用评级(CCR)模型以及基于神经网络的CCR模型。目前,信用评级模型已经非常丰富,企业信用评级领域也得到了快速发展。时间和资金成本大幅减少,新方法的提出打破了评级机构的垄断门槛,中小企业也可以获得评级分数。
此外,随着神经网络方法的引入,评级的准确性显著提高,模型中分析师的主观性也有所降低。然而,信用评级领域仍有许多问题亟待解决。中小企业由于缺乏相应的数据,评级存在困难。此外,大多数企业信用状况良好,低评级的企业较少。数据集类别的严重不平衡给评级过程带来了很大困难。现有模型使用的数据集大多由研究人员自行构建,导致缺乏开源、统一和广泛使用的数据集。一个统一的数据集对于比较不同模型的性能是必要的。
在广泛应用深度学习之前,传统的评级方法广泛使用了定性与定量相结合的方法。然而,近年来快速发展的深度学习方法大多仅使用定量数据进行分析。此外,信用评级问题通常被深度学习模型视为分类问题,忽视了评级对排名的敏感性。基于神经网络的企业信用评级模型的可解释性仍需探讨,这对金融从业者来说是一个难题。未来,企业信用评级的研究将转向信用提升的研究。评级结果只能部分反映企业的经营状况,如何帮助企业提升经营能力和信用评级分数将成为未来该领域的新研究视角。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝