


PyTorch入门-小土堆
本文最后更新于 2024-03-12,文章发布日期超过365天,内容可能已经过时。
放一些学习中的代码片段
只能说土堆胎教的明明白白,即使是草履虫般的博主也能学懂👍
🎶基础工具的使用
read_data.py
# python读取图片数据的简单测试
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = 'TestDataset/hymenoptera_data/train'
ant_label_dir = 'ants'
bees_label_dir = 'bees'
ants_dataset = MyData(root_dir, ant_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_datasettest_tb.py
# TensorBoard的使用
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
img_path = "TestDataset/hymenoptera_data/train/bees/16838648_415acd9e3f.jpg"
img_PIL = Image.open(img_path)
img_array = np.array(img_PIL)
# print(type(img_array), img_array.shape)
# writer.add_image()
writer.add_image("img test", img_array, 2, dataformats='HWC')
# y = x
# for i in range(100):
# writer.add_scalar("y=2x", 3*i, i)
writer.close()test_transforms.py
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
# python的用法 -> tensor的用法
# 通过 transforms.ToTensor()去看待两个问题
img_path = "TestDataset/train/ants_image/0013035.jpg"
img = Image.open(img_path)
# print(img)
writer = SummaryWriter("logs")
# 1.transforms该如何使用(python)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
# print(tensor_img)
writer.add_image("Tensor_img", tensor_img)
writer.close()
# 2.为什么我们需要Tensor
use_transforms.py
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("TestDataset/train/ants_image/28847243_e79fe052cd.jpg")
print(img)
# ToTensor的使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize的使用
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
trans_norm = transforms.Normalize([1, 3, 6], [2, 0.5, 1])
img_norm = trans_norm(img_tensor)
writer.add_image("Normalize", img_norm,1)
# Resize的使用
print(img.size)
trans_resize = transforms.Resize((512, 512))
# img PIL ->resize-> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL ->totensor-> img_resize tensor
img_resize = trans_totensor(img_resize)
print(img_resize)
print(img_resize.size)
writer.add_image("Resize", img_resize)
# Compose - resize - 2
trans_resize_2 = transforms.Resize(512)
# PIL -> PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize_2", img_resize_2)
# RandomCrop的使用
trans_random = transforms.RandomCrop(128)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
writer.close()
dataset_transform.py
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
# print(test_set[0])
# print(test_set.classes)
#
# img, target = test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
#
# print(test_set[0])
writer = SummaryWriter("p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()dataloader.py
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch:{}".format(epoch), imgs, step)
step += 1
writer.close()🤯神经网络相关学习
nn_module.py
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)nn_convolution.py
# 简单的卷积操作
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print(input.shape)
print(kernel.shape)
# 第一个参数是batch size样本数量,第二个参数是channel图像的通道数量
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
# stride步长
output = F.conv2d(input, kernel, stride=1, padding=0)
print(output)
output2 = F.conv2d(input, kernel, stride=2, padding=0)
print(output2)
# padding填充
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)nn_conv2d.py
# Desc: 使用pytorch实现一个简单的卷积神经网络
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
# 初始化网络
tudui = Tudui()
# print(tudui)
writer = SummaryWriter('logs')
step = 0
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
# print(output.shape)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images('input', imgs, step)
# torch.Size([64, 6, 30, 30])
# 这里会发生报错,因为图像的channel的是3,而输出的channel是6,所以无法显示
# writer.add_images('output', output, step)
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images('output', output, step)
step += 1
writer.close()nn_maxpool.py
# 最大池化的使用
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
# input = torch.tensor([[1, 2, 0, 3, 1],
# [0, 1, 2, 3, 1],
# [1, 2, 1, 0, 0],
# [5, 2, 3, 1, 1],
# [2, 1, 0, 1, 1]], dtype=torch.float32)
#
# # -1表示自动计算batchsize
# input = torch.reshape(input, (-1, 1, 5, 5))
# print(input.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# cell_mode=True表示使用天花板除法,就是不足一个池化核时也取上
# 默认的步长是kernel_size
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
# output = tudui(input)
# print(output)
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
img, target = data
# CHW是一种常见的图像数据格式,表示[Channel, Height, Width]。在这种格式下,数据的第一个维度是通道数,第二个维度是高度,第三个维度是宽度。
# 你的输入张量的形状是(64, 3, 32, 32),这表示你有64个样本,每个样本有3个通道,每个通道的大小是32x32。这种格式通常被称为NCHW或[Batch size, Channel, Height, Width]。
writer.add_image("input", img, step, dataformats="NCHW")
output = tudui(img)
writer.add_image("output", output, step, dataformats="NCHW")
step += 1
writer.close()
# 这里会报错"max_pool2d" not implemented for 'Long'
# 因为输入的数据类型是LongTensor,而MaxPool2d只支持FloatTensor
# 因此我们可以修改为
# input = torch.tensor([[1, 2, 0, 3, 1],
# [0, 1, 2, 3, 1],
# [1, 2, 1, 0, 0],
# [5, 2, 3, 1, 1],
# [2, 1, 0, 1, 1]], dtype=torch.float32)
# 添加了dtype=torch.float32
nn_relu.py
# 非线性激活举例:ReLU函数
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# inplace的意思是是否将输出直接覆盖到输入中
self.relu1 = ReLU(inplace=False)
def forward(self, input):
output = self.relu1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)nn_sigmoid.py
# 非线性激活举例:sigmoid函数
import torch
from torch import nn
from torch.nn import Sigmoid
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
# shuffle=True参数表示在每个训练周期开始时,通过随机改变数据集中样本的顺序来重新排列数据
dataloader = DataLoader(dataset, batch_size=64, shuffle=False)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
tudui = Tudui()
writer = SummaryWriter('logs')
step = 0
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
writer.add_images('input', imgs, step)
writer.add_images('output', output, step)
step += 1
writer.close()nn_linear.py
# 线性层的简单例子
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64, shuffle=False, drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = nn.Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
# output = torch.reshape(imgs, (1, 1, 1, -1))
# flatten()函数的作用是将多维张量展平为一维张量
output = torch.flatten(imgs)
print(output.shape)
output = tudui(output)
print(output.shape)搭建小实战_CIFAR10model.py

# 用于构建CIFAR10的模型,如上图所示
# 顺便介绍sequential的用法
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 不引入sequential的写法
# 第一层卷积部分
# 每一步卷积的padding与stride都需要靠计算得出
self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2)
# 第二层池化部分
self.maxpool1 = MaxPool2d(kernel_size=2)
# 第三层卷积部分
self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2)
# 第四层池化部分
self.maxpool2 = MaxPool2d(kernel_size=2)
# 第五层卷积部分
self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2)
# 第六层池化部分
self.maxpool3 = MaxPool2d(kernel_size=2)
# 第七层展平部分
self.flatten = Flatten()
# 第八层线性层
# 图片中少了一层介绍,仔细观察
self.linear1 = Linear(in_features=1024, out_features=64)
# 第九层线性层
self.linear2 = Linear(in_features=64, out_features=10)
# 引入sequential的写法
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10)
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
# 用于测试模型是否正确
input = torch.ones(64, 3, 32, 32)
output = tudui(input)
print(output.shape)
# 除了print可以用来可视化,tensorboard也可以用来可视化
writer = SummaryWriter('logs_seq')
writer.add_graph(tudui, input)
writer.close()nn_loss.py
"""
output 选择 (10) 填空(10) 解答(10)
target 选择 (30) 填空(20) 解答(50)
Loss=(30-10)+(20-10)+(50-10)=70
1.计算实际输出和目标之间的差距
2.为我们更新输出提供一定的依据(反向传播),grand,梯度下降
举例(L1loss):
X:1, 2, 3
Y:1, 2, 5
L1loss =(0+0+2)/3=0.6
举例(MSELoss):
X:1, 2, 3
Y:1, 2, 5
MSELoss =(0+0+4)/3=1.33
举例(CrossEntropyLoss):
X:0.1, 0.2, 0.3
Y:1
CrossEntropyLoss = -0.2*1+ln(exp(0.1)+exp(0.2)+exp(0.3)) = 1.1019
"""
import torch
from torch.nn import L1Loss, MSELoss, CrossEntropyLoss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# L1Loss举例
# 输入mean表示计算平均值,sum表示计算总和
loss = L1Loss(reduction="mean")
# 到这一步会发生报错,要求输入数据是一个浮点数,不能是一个整型
# 现在最新版本的pytorch已经不需要这一步了
result = loss(inputs, targets)
print(result)
# MSELoss(平方差)举例
loss_mse = MSELoss()
result_mse = loss_mse(inputs, targets)
print(result_mse)
# CrossEntropyLoss(分类)举例
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)nn_loss_network.py
# 先引入之前写过的一个CIFAR10的网络,用来做loss network
# 用于构建CIFAR10的模型,如上图所示
# 顺便介绍sequential的用法
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, CrossEntropyLoss
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="dataset", train=False, download=True, transform=torchvision.transforms.ToTensor())
# 不足的舍去
dataloader = DataLoader(dataset, batch_size=1, drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
# print(outputs)
# print(targets)
result_loss = loss(outputs, targets)
print(result_loss)
result_loss.backward()
# 调试断点
print("ok")nn_optimizer.py
# 上一部分使用损失函数求出了grad梯度
# 这一部分将使用优化器(optimizer)来优化损失值,使得损失值最小化
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, CrossEntropyLoss
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True, transform=torchvision.transforms.ToTensor())
# 不足的舍去
dataloader = DataLoader(dataset, batch_size=1, drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = CrossEntropyLoss()
tudui = Tudui()
# 设置优化器,以SGD为例
# 第一个参数是要优化的参数,第二个参数是学习率,其他参数暂不了解
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for epoch in range(20):
runing_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
# 梯度清零
optim.zero_grad()
# 反向传播
result_loss.backward()
# 更新参数
optim.step()
# 观察参数教程https://www.bilibili.com/video/BV1hE411t7RN?t=631.3&p=24
runing_loss = runing_loss + result_loss
"""
关于 optim.step() 之后 result_loss 的值
在调用 optim.step() 更新模型参数之后,当前循环中的 result_loss 的值不会发生改变。
这是因为 result_loss 是在执行 optim.step() 之前计算得到的,它基于当时模型参数的状态。
optim.step() 更新的是模型的参数,而不是直接修改已经计算出的损失值。
如果你在 optim.step() 后再次计算损失(即再次执行前向传播和损失计算),那么由于模型参数已经更新,新计算的损失值可能会不同,反映了参数更新后的模型性能。
"""
print("epoch: %d, loss: %.3f" % (epoch + 1, runing_loss))model_pretrained.py
# 现有网络模型的使用及修改
# 以VGG16为例
import torch
import torchvision
# train_data = torchvision.datasets.ImageNet(root='./data_image_net', split='train', download=True,
# transform=torchvision.transforms.ToTensor())
# pretrained设为False,不加载预训练模型,相当于之前我们写的那个CIFAR10的模型
vgg16_false = torchvision.models.vgg16(pretrained=False)
# pretrained设为True,加载预训练模型参数,相当于是训练好的
vgg16_true = torchvision.models.vgg16(pretrained=True)
print('ok')
# vgg模型是通过ImageNet数据集训练得到的,该数据集有1000类,所以最终输出的维度是1000
print(vgg16_true)
# 因为ImageNet有一百多G太大了,所以我们使用CIFAR10数据集进行演示
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, download=True,
transform=torchvision.transforms.ToTensor())
# (classifier): Sequential(
# (0): Linear(in_features=25088, out_features=4096, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=4096, out_features=4096, bias=True)
# (4): ReLU(inplace=True)
# (5): Dropout(p=0.5, inplace=False)
# (6): Linear(in_features=4096, out_features=1000, bias=True)
# )
# 在这个模型中最后一步out_features=1000,我们需要把它改成10,才可以适应CIFAR10数据集
# .classifier是vgg16模型的分类器部分,我们点它把线性层加进入
vgg16_true.classifier.add_module('add_linear', torch.nn.Linear(1000, 10))
print(vgg16_true)
# 上面演示了添加,现在演示修改
print(vgg16_false)
vgg16_false.classifier[6] = torch.nn.Linear(4096, 10)
print(vgg16_false)
model_save.py
# 学习模型的保存、加载
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式一
# 这种方式不仅保存了模型的参数,还保存了模型的结构
torch.save(vgg16, 'vgg16_method1.pth')
# 保存方式二(官方推荐)
# dict字典,把vgg16的参数保存到字典中,不再保存模型的结构
torch.save(vgg16.state_dict(), 'vgg16_method2.pth')
# 陷阱讲解
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
torch.save(tudui, 'tudui_method1.pth')
model_load.py
# 引入model_save.py中保存的模型
import torch
import torchvision
from model_save import *
# 方式一》保存方式1,加载模型
model1 = torch.load('vgg16_method1.pth')
print(model1)
print('------------------------')
# 方式二》保存方式2,加载模型
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load('vgg16_method2.pth'))
print(vgg16)
print('------------------------')
# 陷阱讲解
model2 = torch.load('tudui_method1.pth')
print(model2)
# AttributeError: Can't get attribute 'Tudui' on <module '__main__' from 'D:\\Python\\learn_pytorch\\model_load.py'>
# 提示没有模型的类,这时候需要把模型的class复制过来,但是不需要创建实例
# 也可以把模型的文件夹import进来,但是不需要创建实例💣一次完整的模型训练全过程
train.py
# 完整的模型训练套路
# 以CIFAR10数据集为例,训练一个简单的神经网络
# CIFAR10图片有十种类别,因此这是一个十分类问题
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备数据集
# 由于CIFAR10数据集中样本是PIL格式,所以我们需要先将其转换为Tensor格式,及transforms.ToTensor()
train_data = torchvision.datasets.CIFAR10(root='dataset', train=True,
transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root='dataset', train=False,
transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{},测试数据集的长度为:{}".format(train_data_size, test_data_size))
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
# 借鉴之前写过的一个CIFAR10模型
# 为了规范,已将模型迁移至文件model.py
from model import *
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
# 创建优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard可视化
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("----------第{}轮训练开始----------".format(i + 1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
total_train_step += 1
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 每100次训练,打印一次Loss,防止控制台输出太多
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
# 测试步骤开始
# 每训练一轮,测试一次,来评估当前模型的性能
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
total_test_step += 1
# 保存每一轮训练的模型
torch.save(tudui, "tudui_{}.pth".format(i + 1))
print("第{}轮训练结束,模型已保存".format(i + 1))
writer.close()model.py
# 搭建神经网络
# 借鉴之前写过的一个CIFAR10模型
# 为了规范,将模型迁移至文件model.py
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 测试
if __name__ == '__main__':
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)tensorboard可视化

针对分类问题的正确率计算
在train.py 的基础上,加入针对分类问题的正确率计算
直接看代码可能思维有些跳跃,因此附上视频相关部分链接
test.py
import torch
outputs = torch.tensor([[0.1, 0.2],
[0.3, 0.4]])
"""
有关输出结果的画图解释https://www.bilibili.com/video/BV1hE411t7RN?t=1070.6&p=28
outputs.argmax(1) 表示在 outputs 的第二个维度(索引为1)上找到最大值的索引。
在这个例子中,outputs 是一个 2x2 的张量,所以 argmax(1) 会在每一行中找到最大值的索引。
outputs.argmax(0) 表示在 outputs 的第一个维度(索引为0)上找到最大值的索引。
在这个例子中,outputs 是一个 2x2 的张量,所以 argmax(0) 会在每一列中找到最大值的索引。
总的来说,argmax(dim) 的 dim 参数指定了在哪个维度上寻找最大值的索引。
"""
print(outputs.argmax(1))
print(outputs.argmax(0))
preds = outputs.argmax(1)
targets = torch.tensor([0, 1])
print(preds == targets)
print((preds == targets).sum())train_improved.py
# 完整的模型训练套路
# 以CIFAR10数据集为例,训练一个简单的神经网络
# CIFAR10图片有十种类别,因此这是一个十分类问题
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备数据集
# 由于CIFAR10数据集中样本是PIL格式,所以我们需要先将其转换为Tensor格式,及transforms.ToTensor()
train_data = torchvision.datasets.CIFAR10(root='dataset', train=True,
transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root='dataset', train=False,
transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{},测试数据集的长度为:{}".format(train_data_size, test_data_size))
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
# 借鉴之前写过的一个CIFAR10模型
# 为了规范,已将模型迁移至文件model.py
from model import *
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
# 创建优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard可视化
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("----------第{}轮训练开始----------".format(i + 1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
total_train_step += 1
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 每100次训练,打印一次Loss,防止控制台输出太多
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
# 测试步骤开始
# 每训练一轮,测试一次,来评估当前模型的性能
total_test_loss = 0
total_accuracy = 0 # 为了计算整体测试集上的准确率,需要记录预测正确的样本数量
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
# 计算当前批次的准确率,具体计算方法见test.py的解释以及对应的视频链接
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step += 1
# 保存每一轮训练的模型
torch.save(tudui, "tudui_{}.pth".format(i + 1))
print("第{}轮训练结束,模型已保存".format(i + 1))
writer.close()tensorboard可视化

细节补充
上述网络代码中55行,训练步骤开始前,没有
tudui.train()也可以正常训练,并不是说必须把网络设置成训练模式才可以开始训练上述网络代码76行,测试步骤开始前,没有
tudui.eval()也可以开始测试,并不是说必须把网络设置成评估模式才可以开始测试之前为什么都没有写依然可以运行,是因为他们的作用相对来说比较小。从官方文档来看,设置成train只对部分层有作用,eval也同样的道理,例如Dropout,BatchNorm层等等。以后写代码的时候我们需要认真查看我们的模型有没有对应的网络层,有的话一定要加上train与eval
我们在上述例子中保存模型使用的都是方式一,现在给出方式二的代码示例
torch.save(tudui.state_dict(), "tudui_{}.pth".format(i))
使用GPU训练
train_gpu_1.py
# 使用gpu训练的第一种方法
"""
1.网络模型
2.数据(输入、标注)
3.损失函数
使用.cuda()再返回就可以了
这是一个在PyTorch中常用的方法,用于将数据或模型从CPU移动到GPU。
在PyTorch中,你可以使用.cuda()方法将模型或数据移动到GPU以进行加速计算。
"""
# 一个使用超级无敌小的细节的补充https://www.bilibili.com/video/BV1hE411t7RN?t=336.5&p=31
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备数据集
# 由于CIFAR10数据集中样本是PIL格式,所以我们需要先将其转换为Tensor格式,及transforms.ToTensor()
train_data = torchvision.datasets.CIFAR10(root='dataset', train=True,
transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root='dataset', train=False,
transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{},测试数据集的长度为:{}".format(train_data_size, test_data_size))
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
# 借鉴之前写过的一个CIFAR10模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 创建网络模型
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda() # 将模型移动到GPU上
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda() # 将损失函数移动到GPU上
# 创建优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard可视化
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("----------第{}轮训练开始----------".format(i + 1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 将输入数据移动到GPU上
targets = targets.cuda() # 将标注数据移动到GPU上
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
total_train_step += 1
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 每100次训练,打印一次Loss,防止控制台输出太多
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
# 测试步骤开始
# 每训练一轮,测试一次,来评估当前模型的性能
total_test_loss = 0
total_accuracy = 0 # 为了计算整体测试集上的准确率,需要记录预测正确的样本数量
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 将输入数据移动到GPU上
targets = targets.cuda() # 将标注数据移动到GPU上
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
# 计算当前批次的准确率,具体计算方法见test.py的解释以及对应的视频链接
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step += 1
# 保存每一轮训练的模型
torch.save(tudui, "tudui_{}.pth".format(i + 1))
print("第{}轮训练结束,模型已保存".format(i + 1))
writer.close()
确实训练速度快了好多,提升了十倍以上!
train_gpu_2.py
# 使用gpu训练的第二种方法
"""
1.网络模型
2.数据(输入、标注)
3.损失函数
使用.to(device)
Device = torch.device("cpu")
Torch.device("cuda")
指定第一张显卡
Torch.device("cuda:0")
指定第二张显卡
Torch.device("cuda:1")
"""
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 定义训练的设备
# 设置为在cpu上运行
# device = torch.device("cpu")
# 设置为在gpu上运行
device = torch.device("cuda")
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 准备数据集
# 由于CIFAR10数据集中样本是PIL格式,所以我们需要先将其转换为Tensor格式,及transforms.ToTensor()
train_data = torchvision.datasets.CIFAR10(root='dataset', train=True,
transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root='dataset', train=False,
transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{},测试数据集的长度为:{}".format(train_data_size, test_data_size))
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
# 借鉴之前写过的一个CIFAR10模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 创建网络模型
tudui = Tudui()
tudui = tudui.to(device) # 将模型移动到我们一开始定义的设备上去
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device) # 将损失函数移动到我们一开始定义的设备上去
# 创建优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard可视化
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("----------第{}轮训练开始----------".format(i + 1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device) # 将输入数据移动到我们一开始定义的设备上去
targets = targets.to(device) # 将标注数据移动到我们一开始定义的设备上去
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
total_train_step += 1
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 每100次训练,打印一次Loss,防止控制台输出太多
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
# 测试步骤开始
# 每训练一轮,测试一次,来评估当前模型的性能
total_test_loss = 0
total_accuracy = 0 # 为了计算整体测试集上的准确率,需要记录预测正确的样本数量
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device) # 将输入数据移动到我们一开始定义的设备上去
targets = targets.to(device) # 将标注数据移动到我们一开始定义的设备上去
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
# 计算当前批次的准确率,具体计算方法见test.py的解释以及对应的视频链接
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step += 1
# 保存每一轮训练的模型
torch.save(tudui, "tudui_{}.pth".format(i + 1))
print("第{}轮训练结束,模型已保存".format(i + 1))
writer.close()🎉完整的模型验证套路
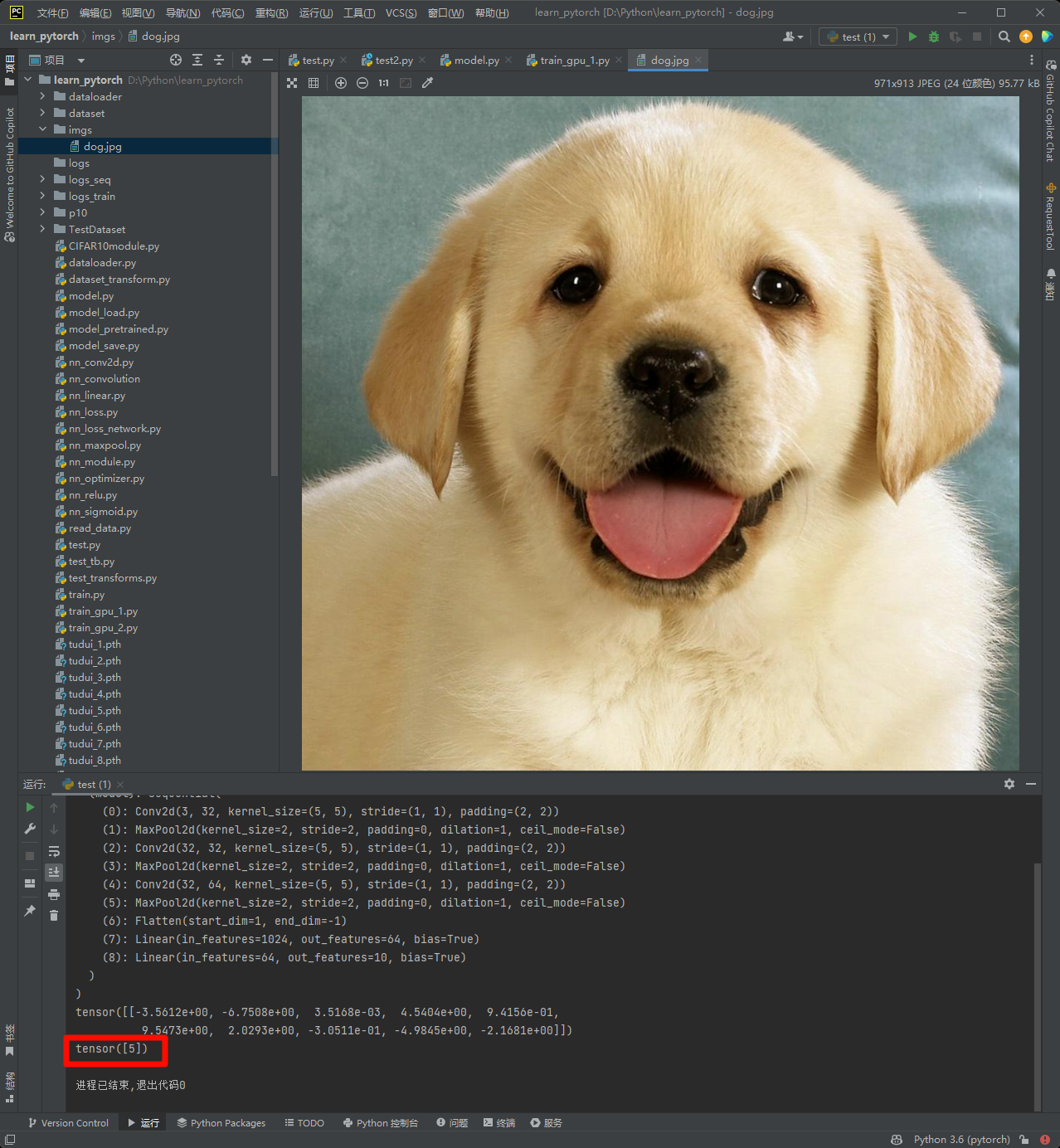
用于验证的两张图片
网上随便找的两张图片,可以多找几张用来测试,还挺好玩的嘿嘿
该十分类模型可以识别的类型有:0是飞机,1是汽车,2是鸟,3是猫,4是鹿,5是狗,6是青蛙,7是马,8是船,9是卡车


test.py
前面训练轮数都是10轮,用来真正的测试还是不太准确,因此这里使用了训练了30轮以后的模型参数,即
tudui_30.pth
"""
完整的模型验证(测试,demo)套路
利用已经训练好的模型,然后给它提供输入,看看它的输出是否符合预期
"""
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "./imgs/airplane.jpg"
# 打开是PIL类型
image = Image.open(image_path)
print(image)
# 为了适应我们的模型,需要对图片进行预处理
transform = torchvision.transforms.Compose(
[torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()]
)
image = transform(image)
print(image.shape)
# 加载网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 如果模型原来是使用gpu训练的,这时候就需要告诉电脑使用cpu进行测试,要不然会报错
model = torch.load("tudui_30.pth", map_location=torch.device('cpu'))
print(model)
# 要求输入的image是一个四维的,但现在是torch.Size([3, 32, 32]),少了一个batch size的维度
image = torch.reshape(image, (1, 3, 32, 32))
# 下面这几行不要忘记了,养成一个良好的代码习惯
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
# 0是飞机,1是汽车,2是鸟,3是猫,4是鹿,5是狗,6是青蛙,7是马,8是船,9是卡车验证结果
🎉🎉两张图片均识别正确!🥳
0是飞机,1是汽车,2是鸟,3是猫,4是鹿,5是狗,6是青蛙,7是马,8是船,9是卡车

- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝