

DeepWalk代码复现并使用RWR替换RW+Cora数据集上的可视化对比
AI-摘要
切换
小郭 GPT
AI初始化中...
介绍自己
生成本文简介
推荐相关文章
前往主页
前往tianli博客
本文最后更新于 2024-04-18,文章发布日期超过365天,内容可能已经过时。
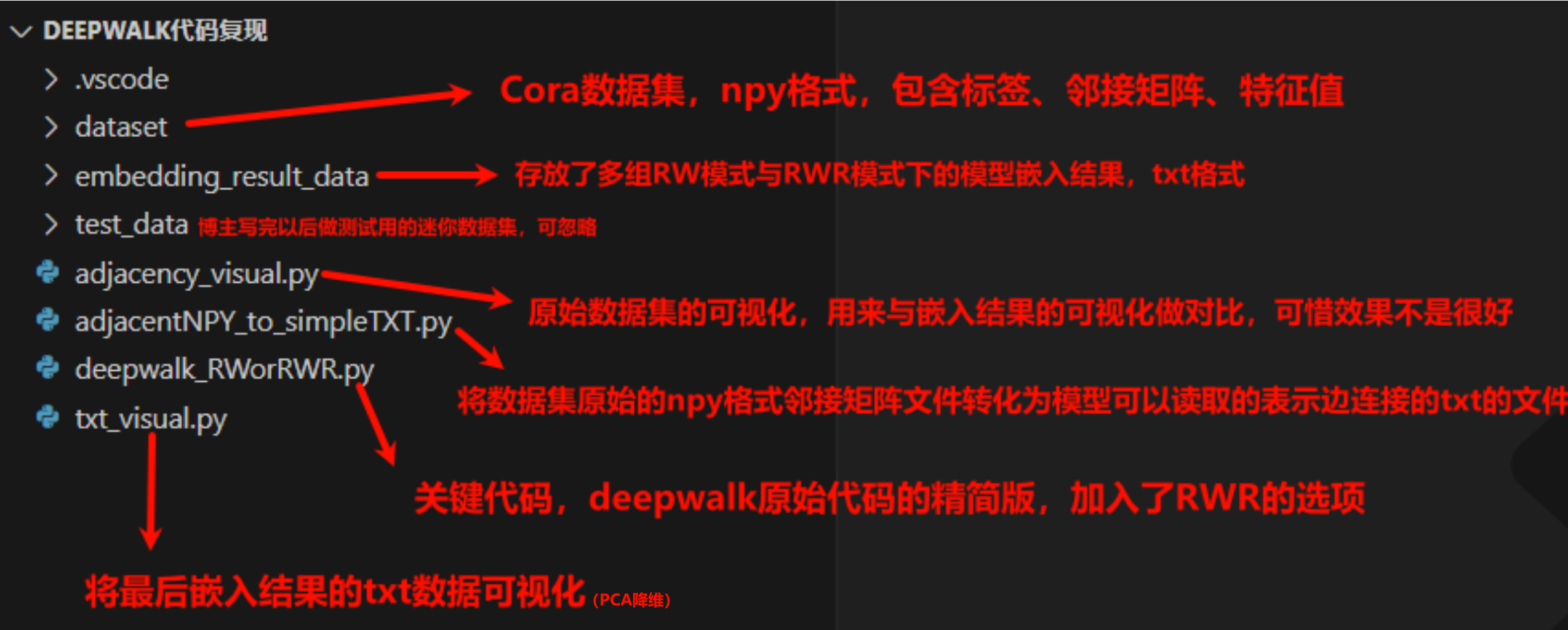
代码结构介绍
{源码+数据集下载, https://lovexl-oss.oss-cn-beijing.aliyuncs.com/bed/DeepWalk%E4%BB%A3%E7%A0%81%E5%A4%8D%E7%8E%B0.zip, haofont hao-icon-book}
DeepWalk就不用多说了,由于它在github上的原始版本太过复杂,因此博主便有了重新写一个精简版本的想法。同时,deepwalk模型中使用了随机游走来生成语料库,我也加入了重启的选项,本文引入了一个测试数据集来对RW与RWR进行可视化的效果对比。
如何使用
下面是一个简单的使用样例:
build_corpu默认进行随机游走,若加入参数alpha就会进行重启随机游走
# 生成一个有向图
node_num = 2707 # 需要我们提前知道使用的Cora数据集有2707个节点
edge_txt = "dataset/cora_edges.txt" # 这个是使用npy转txt程序后的边信息
G = deepwalk_RWorRWR(node_num, edge_txt)
# 生成语料库
num_paths = 10 # 每个节点进行游走的次数
path_len = 10 # 每一次游走的长度
total_walks = G.build_corpus(num_paths, path_len)
# 训练word2vec模型
G.train(total_walks, embed_size=64, window_size=3, output="embedding_result_data/RW/10轮10步64维.txt")
嵌入结果:

源代码
deepwalk_RWorRWR.py
from networkx.classes.function import nodes
import numpy as np
import os
import networkx as nx
import random
from tqdm import tqdm
from gensim.models import Word2Vec
class deepwalk_RWorRWR:
# 初始化函数,输入节点数目,边的txt文件地址
def __init__(self, node_num: int, edge_txt: str, undirected=False):
print("初始化图结构")
# 先判断是有向的还是无向的
if undirected:
self.G = nx.Graph()
else:
self.G = nx.DiGraph()
# 生成一个输入num数目的节点列表,放在图中
self.G.add_nodes_from(list(range(node_num)))
# 节点解决了,开始解决边,我们去定义一个读取str格式的边信息的函数read_edge
edges = self.read_edge(edge_txt)
self.G.add_edges_from(edges)
# 获取图信息
self.adjacency = np.array(nx.adjacency_matrix(self.G).todense())
self.G_neighbor = {}
# 获取每个节点的邻居列表,然后构成一个邻居字典,字典的key就是这个源节点的node
for i in range(self.adjacency.shape[0]):
self.G_neighbor[i] = []
for j in range(self.adjacency.shape[0]):
if i == j:
continue
if self.adjacency[i, j] > 0.01:
self.G_neighbor[i].append(j)
# 输入一个边的txt文件地址,返回一个元组列表,每一个元组表示一条边
def read_edge(self, edge_txt):
# loadtxt非常适合读取由简单分隔符(如空格)分隔的数字
edges = np.loadtxt(edge_txt, dtype=np.int16)
# 创建一个元组列表,每一个元组表示一条边
edges = [(edges[i, 0], edges[i, 1]) for i in range(edges.shape[0])]
return edges
# 生成一个 随机游走/重启随机游走 序列
def RWorRWR(self, path_len, alpha=0, rand_iter=random.Random(628), start=None):
"""_summary_
Args:
path_len (_type_): 指定随机游走的长度
alpha (int, optional): 重启的概率
rand_iter (_type_, optional): 随机数生成器
start (_type_, optional): 指定随机游走的起始节点
"""
# 把初始化函数中的邻居字典给了G
G = self.G_neighbor
if start:
rand_path = [start]
else:
# 没指定就随机选一个节点出来,随机概率与节点的任何属性都没有关系
# G.keys()返回的是一个动态的字典键试图对象,我们给他转成列表
rand_path = [rand_iter.choice(list(G.keys()))]
# 开始一次随机游走
while len(rand_path) < path_len:
current_pos = rand_path[-1]
if len(G[current_pos]) > 0: # 当当前节点有邻节点时
if rand_iter.random() > alpha:
rand_path.append(rand_iter.choice(G[current_pos]))
else: # 重启
rand_path.append(rand_path[0])
else: # 当碰到孤立节点以后
break
return [str(node) for node in rand_path]
# 构建语料库
def build_corpus(self, num_paths, path_len, alpha=0, rand_iter=random.Random(628)):
"""_summary_
Args:
num_paths (_type_): 决定生成多少组随机游走序列,一组包含全部节点的随机游走序列
path_len (_type_): 指定随机游走的长度
alpha (int, optional): 重启的概率
rand_iter (_type_, optional): 随机数生成器
"""
if alpha:
print("开始生成重启随机游走语料库")
else:
print("开始生成随机游走语料库")
total_walks = []
G = self.G_neighbor
nodes = list(G.keys())
for i in tqdm(range(num_paths)):
# 将节点列表打乱
rand_iter.shuffle(nodes)
# 分别从每个节点开始进行一次随机游走
for node in nodes:
total_walks.append(self.RWorRWR(path_len, alpha, rand_iter, start=node))
return total_walks
# 训练word2vec模型
def train(self, total_walks, embed_size=64, window_size=3, output="."):
"""_summary_
Args:
total_walks (_type_): 语料库
embed_size (int, optional): 词向量维度
window_size (int, optional): 窗口大小
output (str, optional): 输出路径
"""
print("开始训练word2vec模型")
model = Word2Vec(
total_walks,
vector_size=embed_size,
window=window_size,
min_count=0, # 词频阈值,如果一个词的频率小于min_count,那么这个词将被忽略
sg=1, # 训练算法的选择,如果sg是0,那么将使用CBOW算法;如果sg是1,那么将使用Skip-gram算法
hs=1, # 训练模型时是否使用Hierarchical Softmax,如果hs是0,那么将使用Negative Sampling;如果hs是1,那么将使用Hierarchical Softmax
workers=8, # 训练模型时使用的线程数,表示在训练模型时,可以同时运行的线程数
)
model.wv.save_word2vec_format(output)
# 进行训练
if __name__ == "__main__":
# 生成一个有向图
node_num = 2707
edge_txt = "dataset/cora_edges.txt"
G = deepwalk_RWorRWR(node_num, edge_txt)
# 生成语料库
num_paths = 10
path_len = 10
total_walks = G.build_corpus(num_paths, path_len)
# 训练word2vec模型
G.train(total_walks, embed_size=64, window_size=3, output="embedding_result_data/RW/10轮10步64维.txt")
print("训练完成")
adjacentNPY_to_simpleTXT.py
import numpy as np
from tqdm import tqdm
# 该程序实现将 npy格式的邻接矩阵 转换为 txt格式的有向图或无向图的边列表
def adj_matrix_to_edge_list_directed(adj_matrix, output_file):
# 打开一个新的.txt文件,准备写入边列表
with open(output_file, 'w') as f:
# 遍历邻接矩阵的每一个元素
for i in tqdm(range(adj_matrix.shape[0]), desc="Processing directed graph"):
for j in range(adj_matrix.shape[1]):
# 如果这两个节点之间有边
if adj_matrix[i, j] != 0:
# 将这条边写入.txt文件
f.write(f'{i} {j}\n')
def adj_matrix_to_edge_list_undirected(adj_matrix, output_file):
# 打开一个新的.txt文件,准备写入边列表
with open(output_file, 'w') as f:
# 遍历邻接矩阵的上三角部分
for i in tqdm(range(adj_matrix.shape[0]), desc="Processing undirected graph"):
for j in range(i+1, adj_matrix.shape[1]):
# 如果这两个节点之间有边
if adj_matrix[i, j] != 0:
# 将这条边写入.txt文件
f.write(f'{i} {j}\n')
# 使用样例
# # 从.npy文件加载邻接矩阵
# adj_matrix = np.load('adj_matrix.npy')
# # 将邻接矩阵转换为有向图的边列表
# adj_matrix_to_edge_list_directed(adj_matrix, 'edge_list_directed.txt')
# # 将邻接矩阵转换为无向图的边列表
# adj_matrix_to_edge_list_undirected(adj_matrix, 'edge_list_undirected.txt')
adj_matrix = np.load('dataset/cora_adj.npy')
adj_matrix_to_edge_list_undirected(adj_matrix, 'dataset/cora_edges.txt')txt_visual.py
import pandas as pd
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 通过deepwalk生成的txt嵌入文件进行可视化
# 读取txt文件
# 读取第一行作为头部或特殊数据处理
header = pd.read_csv('embedding_result_data/RWR/重启0.4_100轮10步128维.txt', sep=" ", header=None, nrows=1)
print("节点个数:{}, 节点嵌入维度:{}".format(header[0][0], header[1][0]))
# 从第二行开始读取其余数据
data = pd.read_csv('embedding_result_data/RWR/重启0.4_100轮10步128维.txt', sep=" ", header=None, skiprows=1)
data = data.drop(0, axis=1)
print(data)
# 使用PCA降维data数据
pca = PCA(n_components=2)
result = pca.fit_transform(data)
print("降维后的数据:")
print(result)
# 可视化
plt.figure(figsize=(16, 12))
plt.scatter(result[:, 0], result[:, 1])
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA on Embedding')
plt.show()adjacency_visual.py
import numpy as np
import matplotlib.pyplot as plt
# 加载npy文件
adj_matrix = np.load('dataset/cora_adj.npy')
# 找到所有节点的位置
y, x = np.where(adj_matrix > 0)
# 绘制邻接矩阵
plt.figure(figsize=(16, 12))
plt.imshow(adj_matrix, cmap='binary')
# 使用scatter函数绘制节点
plt.scatter(x, y, color='red')
plt.title('Adjacency Matrix')
plt.show()Cora数据集上的可视化对比
原始图像
由于博主自己写的这个可视化只是通过连接信息创建的,效果很是不好,如下:

因此从网上找到了这个数据集的一张原始图像,用作我们进行嵌入效果的对比:
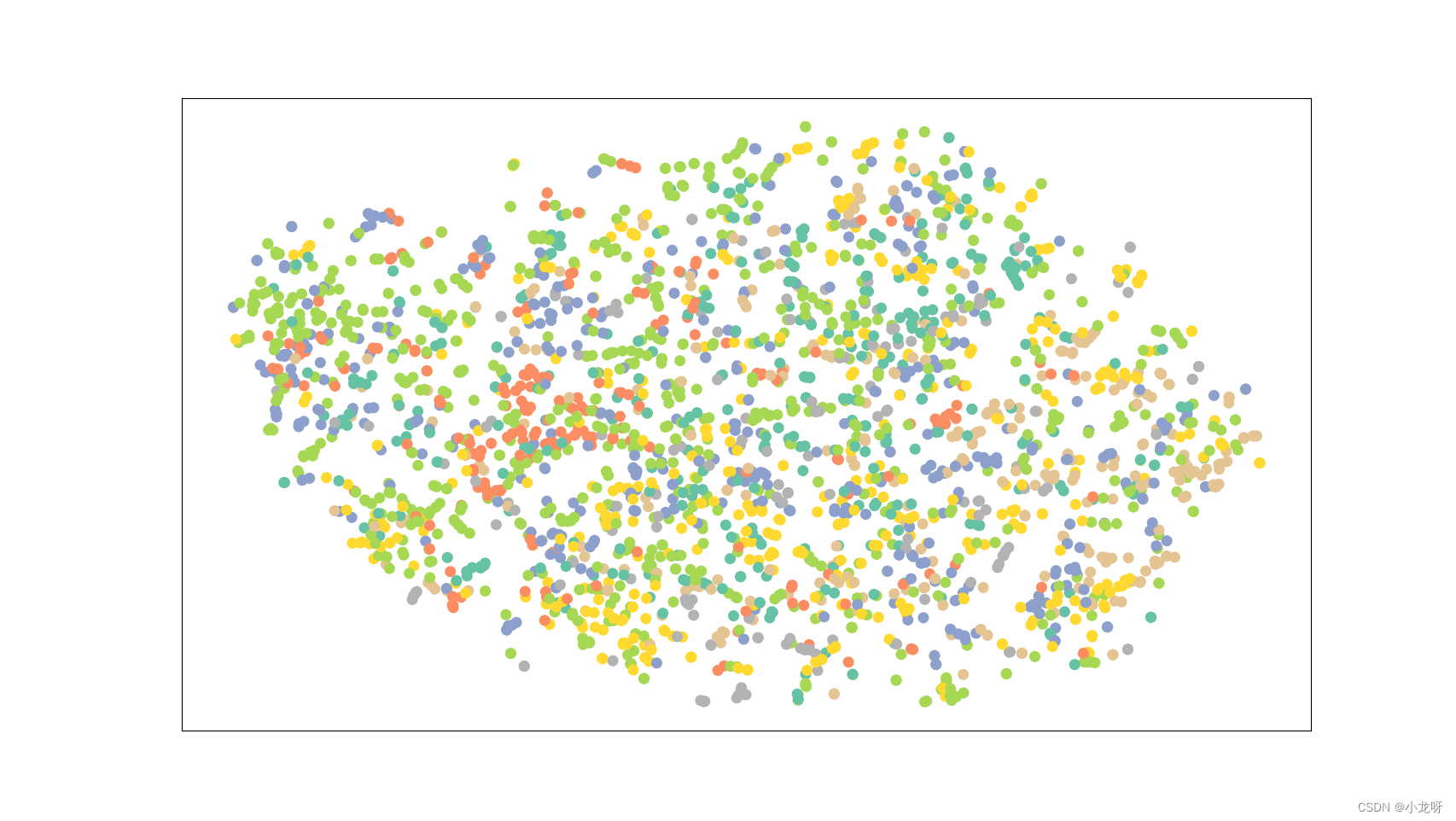
RW嵌入
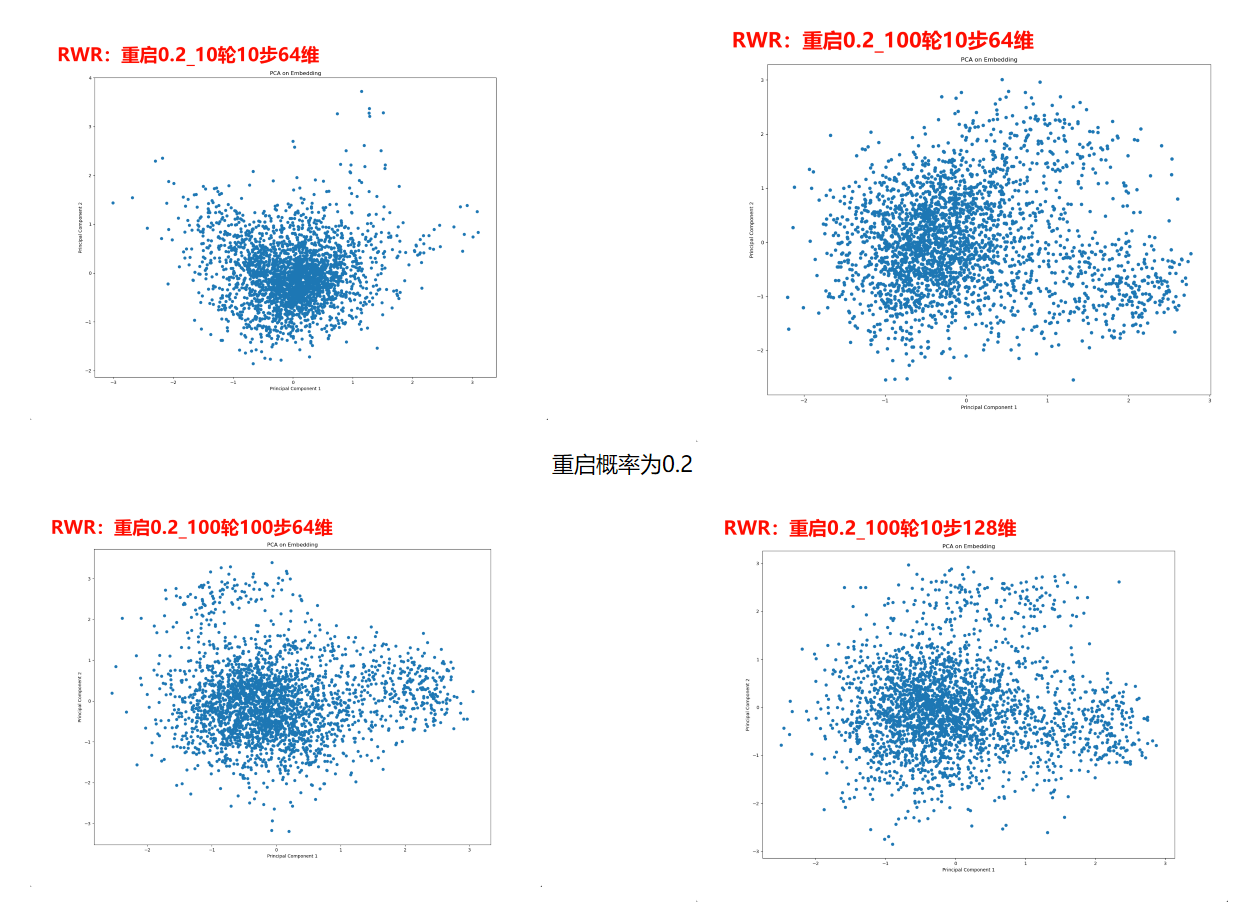
10轮表示每个节点进行十次游走
10步表示每次游走的长度为10
64维表示嵌入的维度

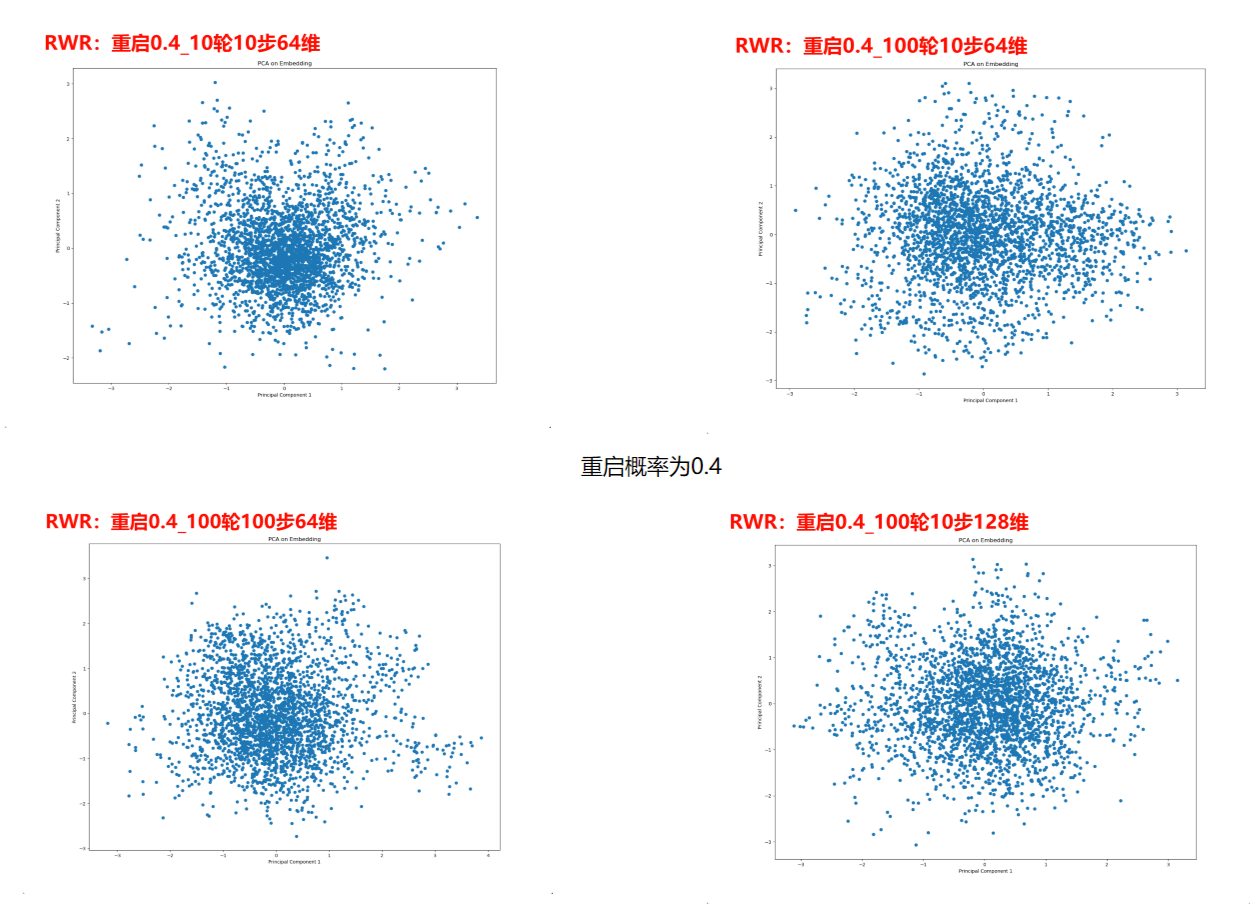
RWR嵌入
重启0.2表示每一次随机游走的重启概率为20%
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
赞赏者名单
因为你们的支持让我意识到写文章的价值🙏
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 郭同学的笔记本
阅读建议
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果