


中文详解-《Jbeil:基于时间图的归纳学习推断演化企业网络中的横向运动》
本文最后更新于 2024-05-30,文章发布日期超过365天,内容可能已经过时。
注:黄学长那一版演变而来,个人补充
代码剖析见另一篇文章:Jbeil源码剖析 | 郭同学的笔记本 (lovexl.top)
github源码地址:[LMscope/Jbeil: IEEE SP'24] The Official Implementation of "Jbeil: Temporal Graph-Based Inductive Learning to Infer Lateral Movement in Evolving Enterprise Networks" (github.com)
一、Abstract
横向移动(LM)是先进持续威胁的核心阶段之一,它持续威胁着大型企业网络的安全状况。
在网络安全领域,“横向移动”(Lateral Movement)是指攻击者在获取初始访问权限后,在目标网络内部横向扩展以达到其目的的策略。横向移动通常是高级持续性威胁(APT)攻击的一部分,攻击者在内部网络中移动以寻找敏感信息、增加对网络的控制或者找到更有价值的目标。
攻击者通过横向移动可以:
- 扩大权限:攻击者可能首先获得低级用户权限,然后通过横向移动获取更高的权限。
- 寻找目标:攻击者在网络中移动以寻找感兴趣的目标,如重要的数据库或文件服务器。
- 建立持久性:攻击者可能在多个节点上建立持久性访问,以确保即使一个入口被封锁,他们仍然可以通过其他入口访问网络。
横向移动可能涉及使用被盗的凭据、利用系统漏洞、滥用信任关系等方式。
近期的研究工作已经采用图神经网络(GNN)技术来检测复杂网络中的LM。这些方法采用传导图学习,即在训练阶段使用具有完全节点可见性的固定图,并引入良性数据。这两个假设在现实世界的设置中:
- 没有考虑到企业网络的
演变性质,其中主机、用户、虚拟环境和应用程序之间的动态特性和连接性占主导地位。 仅依靠正常数据进行训练限制了检测LM的有效性,尤其是考虑到当代恶意行动的逃避性、隐蔽性和类似良性的行为。复杂网络通常无法完全看到其运行时网络进程的全部情况,即使能够做到,也常因被动数据分析的延迟问题而难以动态追踪LM。
为此,本文提出了Jbeil,一个基于数据的自监督深度学习框架,用于表示为认证时序事件序列的演变网络。
这项工作的前提在于应用一个编码器于连续时间演变图上,以产生每个时间周期可见图节点的嵌入, 并使用一个解码器利用这些嵌入来对未见节点执行LM链接预测。此外,我们在Jbeil中加入了 一个威胁样本增强机制,以确保对先进LM攻击有一个充分的认识。
我们使用洛斯阿拉莫斯网络的认证时序事件对Jbeil进行评估,即使在训练阶段有30%的节点/边不在时,也达到了99.73%的AUC分数和99.25%的召回率。此外,我们评估了不同的现实攻击场景,并展示了 Jbeil在其归纳和传导设置中预测LM路径的潜力,其AUC分数达到了99%,大幅优于现有的最先进技术。
二、结论
在这项工作中,我们提出了Jbeil,这是一种基于时间图的方法,用于使用带时间戳的认证日志检测企业网络中的横向移动(LM)。Jbeil的编码器聚合相邻节点的记忆以计算时间节点嵌入,这些嵌入被解码器用于LM链接预测。
我们的实验显示,当数据集的30%被遮蔽时,Jbeil在预测LM路径方面的归纳能力具有99.73%的AUC分数。Jbeil还可以检测LM路径,无论节点的可见性和数量如何,并且在预测现实攻击的LM路径方面优于现有的最先进技术。我们坚实地证明了Jbeil的效率和可扩展性,并实际讨论了其与现有安全解决方案整合的潜力
在未来的工作中,我们计划探索Jbeil检测其他类型攻击和恶意活动的潜力,通过分析基于主机的数据和日志。
三、Introduction
3.1 网络数据变化
为了在企业网络中有效地推断横向移动(LM),我们在这篇论文中旨在设计并开发一种基于时间图的归纳学习方法,它体现了现实世界场景中遇到的两个关键概念:
- 大型复杂企业网络不断演变/动态的特性
- 这些环境中的实际网络威胁能力
为了激发企业网络演变的概念,从而展示需要有效能力来利用网络和系统范围的信息进行LM检测,我们在这里提供了一个实际场景的经验分析。我们研究了从洛斯阿拉莫斯国家实验室(LANL)真实计算机网络中收集的、跨越58天的标记过的认证事件数据集得到的节点和边的动态性质。节点代表不同的用户、计算机和服务器,而边表示随时间在节点之间的认证事件。
首先,在10个不同的时间间隔内(即,58天等分),我们使用Jaccard相似性指数测量每个间隔的节点相似性,描述为J(A,B)=|A\cap B|/|A\cup B|,其中集合A和B代表连续两天的节点。
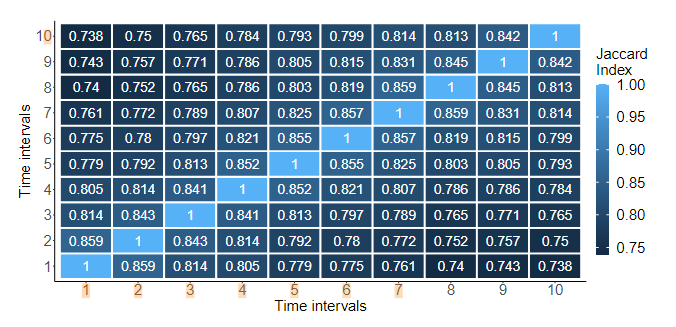
上图(图1a)实证地展示了节点相似性下降了26%(在第一个和最后一个时间间隔之间),这确实展示了企业网络在新节点/认证实体方面不断演变的性质。
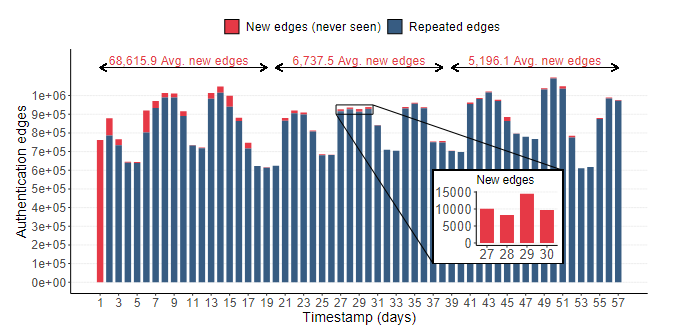
上图(图1b)展示了随时间出现的大量新的(以前从未见过的)边。在策划的数据的第30天,出现了10K新的边(认证事件)。这一证据揭示了企业网络的演变性质,它使恶意行为者能够渗透并横向操纵隐蔽节点和相关边。此外,它还突显出建立一个稳固的观察点来策划和分析动态操纵路径中的相关经验性证据的困难,进一步对LM检测产生了不利影响。
3.2 解决采样偏差, 测试窥探和时间窥探
图神经网络(GNN)之前已被用于主机和网络的异常检测器中,通过学习正常行为模型并推断出这些模型的偏差。此外,离散时间动态信息在采用传导学习方法的情况下,可以提高对网络异常活动的检测。然而,对于安全问题(例如,推断LM攻击)的连续时间动态图表征和归纳学习,鲜有研究。而在少数研究中,解决了采样偏差、测试窥探和时间窥探的问题。
”考虑到离散时间动态信息可以在采用传导学习方法的情况下提高对网络异常活动的检测“:
对于网络异常活动的检测,离散时间动态信息(discrete-time dynamic information)可以通过传导学习(transductive learning)的方法来提升检测效果。
- 离散时间动态信息:这是指以离散的时间间隔对网络中的变化进行记录和分析。例如,网络中的节点和边在不同的时间点发生变化,这些变化被记录下来形成离散时间动态信息。
- 传导学习:传导学习是一种机器学习方法,其中模型在学习期间可以看到训练和测试数据中的所有节点,但只能预测测试数据中的未标记节点。传导学习通常在图数据中使用,因为图结构中的节点之间具有关联性,传导学习可以利用这些关联性来提升预测的准确性。
连续时间动态图表征:
连续时间动态图表征是指一种对动态图的表示方式,其中时间被视为连续变量,而不是离散的时间间隔。这种表征方式旨在更准确地描述和捕捉动态图中的变化和动态特性。
在动态网络中,节点和边会随着时间的推移而变化。连续时间动态图(Continuous-Time Dynamic Graph)通过使用连续时间来记录这些变化,从而可以提供更精细的时间粒度。这意味着网络中的事件(例如,节点和边的变化)可以在任意时间点发生,而不是限制在预定义的离散时间点。
这种表征方式提供了优越的时间分辨率,能够更好地描述现实世界中网络的动态行为,对于检测如横向移动攻击(Lateral Movement Attack)等安全问题至关重要。
- 采样偏差 :网络安全的背景下,意味着所收集的数据无法覆盖所有类型的正常和恶意行为。
- LM的威胁样本增强
- 测试窥探 :在模型在评估阶段之前,已经以某种方式“见过”测试数据。导致验证过拟合。
- 归纳性有助于消除测试窥探
- 时间窥探 : 时间窥探是指模型在训练过程中无意中获得了关于未来事件的信息, 导致拿着答案写题目。
- 连续时间图
当在计算机安全环境中实现机器学习模型时,正如前面强调的,真实且复杂的企业网络的演变性质进一步加剧了这些挑战。在这个背景下,Jbeil被设计来克服这些重大挑战,有效推断企业网络中的LM:
-
连续时间动态图以连续的表征来模拟动态图,提供了优越的时间粒度。这样的属性
避免了时间窥探问题,这对于正确表示在现实世界企业网络中发现的连续变化下的基本分布非常必要,在这里检测 LM攻击至关重要。连续时间动态图与离散时间动态图截然不同,后者包含在不同时间间隔拍摄的静态图快照序列。 -
时态GNN中的归纳学习关系到关键场景,其中的节点在训练期间尚未被模型看到,但用于测试。与传导学习不同(见图2),模型必须能够通过学习已见数据中的模式和关系来准确预测未见数据。因此,
归纳性共同有助于消除测试窥探,当在最终评估之前用于实验的测试集时,以及在不断演变的企业网络背景下,其中新的节点和边继续动态出现。“时态GNN”指的是时序图神经网络(Temporal Graph Neural Network)。与普通的图神经网络(GNN)相比:
- 时间维度:
- 普通GNN:处理静态图结构。
- 时态GNN:处理动态图结构,考虑节点和边随时间的变化。
- 应用场景:
- 普通GNN:多用于社交网络、知识图谱等静态图。
- 时态GNN:用于通信网络、交通网络、金融网络等动态图。
- 时间处理方式:
- 普通GNN:不处理时间维度。
- 时态GNN:处理时间信息,捕捉随时间变化的特征。
图2:大致看一下,后面会详细说
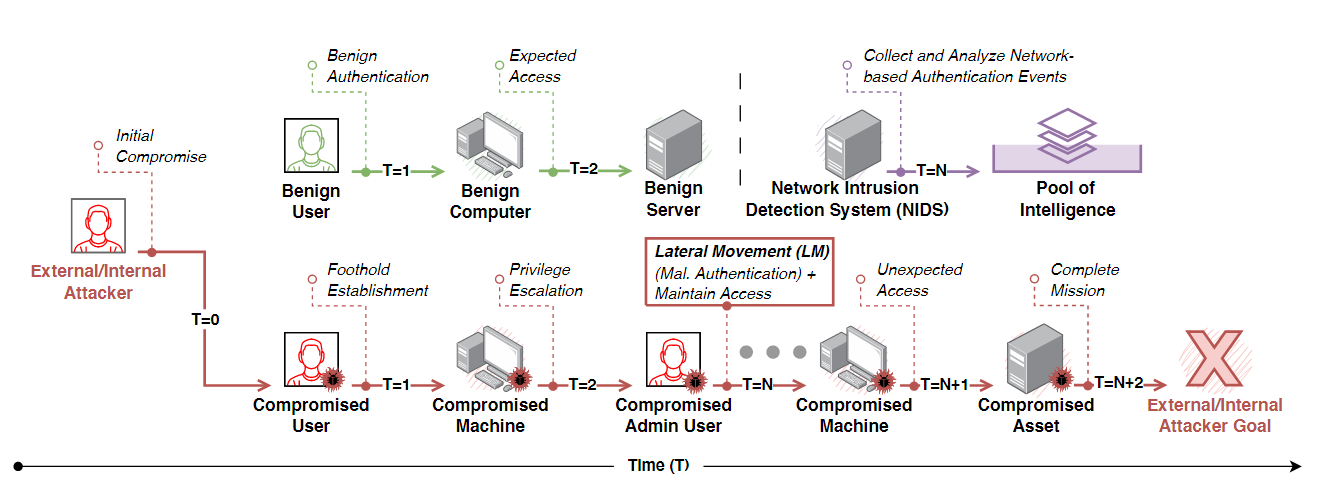
- 时间维度:
-
在与APT相关的攻击场景中,类似于LM的威胁样本增强对于模型训练阶段至关重要,以解决采样偏差问题,这种问题总是在数据不太具有代表性时发生。这种增强引入了全面和多样化的攻击者战术、技术和程序(TTPs)(例如,隐蔽或攻击性行为,完全或有限的网络知识等)到时态GNN模型中,从而支持在实际操作/对抗先进攻击策略时有效且明智的决策。然而,策划这样全面代表性的攻击数据被认为是极其困难的,因此,应探索、采用和评估辅助威胁样本增强方法。
APT(Advanced Persistent Threat,高级持续性威胁)是一类高度复杂的网络攻击。APT攻击通常由组织化的攻击者(如国家级黑客、间谍机构等)实施,目标是对特定组织或个人进行长期的网络入侵。
3.3 创新层面
使用的方法
- 基于关系的认证事件处理:Jbeil将认证事件视为关系数据,意味着它考虑了事件间的关系及其在时间序列中的全局背景。
- 构建认证图:系统创建了一个图,其中
节点代表认证实体,边代表认证事件。 - 图特性提取:提取认证图的特征,以理解企业网络随时间变化的动态特性。
- 自我监督的时间节点嵌入:采用
消息传递技术,为图中的每个节点计算每个时间点的潜在表示。 - 动态状态更新:节点的状态在涉及事件时更新,并在计算模型的时间嵌入时
考虑邻近节点的信息。 - 时间顺序边处理:处理按时间顺序排列的边,用于更新节点状态和嵌入。
- 边的概率计算与LM链接预测:解码器计算边的概率,并执行预测。
得到的效果
- 高性能指标:在归纳学习设置中,Jbeil实现了99.82%的AUC和99.22%的召回率。
- 对未见节点的泛化:即使30%的节点和边在训练阶段未曾出现,Jbeil仍能高效预测。
- 优于现有方法:与现有先进方法Euler比较,Jbeil在AUC上平均提高了约40%。
创新点
- 连续时间动态图模型:Jbeil利用了连续时间动态图的模型,与传统的离散时间动态图模型不同,为 网络事件提供了更高的时间粒度,更准确地反映了真实世界企业网络的持续变化。
- 归纳学习模型:相对于传统的传导学习方法,Jbeil的归纳学习模型能够处理在训练期间未见过的节点,使得模型更适用于动态变化的网络环境。
- 威胁样本增强机制:在预处理阶段包含的这一机制可以根据最新的攻击场景和策略丰富训练数据, 提高模型对新兴威胁的适应性和预测能力。
四、Preliminary
多放点
4.1 横向移动和认证日志
LM是由威胁参与者执行的一组内部动作,以损害有价值的资产(例如,特权用户、服务器、数据等), 为目标在企业网络中传播。
最初,威胁参与者使用 MITRE ATT&CK 框架中识别的技术(例如 MITRE ATT&CK 框架)在网络中获得立足点。随后的网络传播是通过利用现有企业实体或认证协议中的漏洞来实现的。在MITRE ATT&CK框架中展示的技术中,有特定的技术用于在LM阶段获取特权凭证和未授权访问。
值得注意的是,LM可以手动和/或自动执行(例如使用专用恶意软件)。因此,企业网络中各种资产生成的常见认证日志可以作为检测与LM密切相关的可疑活动的(威胁)数据来源。
为了整理这些活动,如NIDS和/或SIEM等网络范围的系统会收集并分析基于网络的认证事件。以前的研究工作已经利用认证日志来检测和识别源自恶意登录尝试和未授权访问的LM。
这些方法主要依赖于基于签名的或基于异常的算法。虽然这些以前的方法为检测企业网络中的LM提供了有价值的优势,但大多数系统仍然产生大量的误报和漏报,并且/或者未能区分良性事件和恶意事件。 在此背景下,通过Jbeil,我们旨在探索基于图的学习方法在使用认证日志建模和检测LM活动方面的可靠性。
4.2 传导和归纳推理
链接预测是分析图数据中最重要的任务之一,鉴于它在网络欺诈检测、推荐系统和知识图完成方面所能提供的好处。
传导和归纳方法是链接预测的两种主要类型。
大多数现有工作依赖于传导方法;邻接矩阵包含了与训练和测试数据集相关的所有节点。也就是说,所有现有节点集都是已知的,并在训练过程中使用。
相比之下,在归纳学习方法中,训练过程中不需要事先知道所有节点。由于这种优势超过了传导方法,归纳方法允许模型解决生产中的实际问题,在这些问题中,模型肯定会在训练过程中遇到以前未见过的节点;在这种情况下,模型可用的唯一信息将是用于做出预测的新节点的一些属性。
上图(图3)展示了传导和归纳推理,在图中归纳节点和链接被阴影区分,以区别于传导情形中已知的节点(即,实心节点和链接)。在一个不断发展的企业网络中,人们经常会遇到许多未见过的(即,新节点)试图与已知和/或未知实体通信。
在传导设置中训练的现有GNN模型无法预测或分类新节点或链接。虽然存在特定应用,传导方法非常适用,但许多实际应用需要归纳方法来处理新集成的节点。
- GraphSAGE是一项针对未见节点 计算嵌入的最新工作,但需要关于节点边的信息。
- 在G2G中,作者提出了一种对未见节点的归纳链接预测方法,而不需要本地结构。然而,他们的方法无法区分具有共同属性的节点,主要是因为他们的模型没有捕获节点表示中的结构信息。
- 在另一项研究中(引用65),作者提出了一个具有对齐的双编码器图嵌入,用于仅使用属性信息对未见节点进行归纳链接预测。尽管如此,他们的方法严重依赖于节点属性,并没有结合节点间交互的时间信息。
4.3 方法
- 预处理管道:首先通过一个预处理管道,这一阶段包括提取图形并计算图特征,以生成图结构。这 些图结构是根据
良性以及经过威胁增强的认证日志中发现的信息生成的。 - Jbeil技术:接下来,我们引入了名为Jbeil的技术,这是一种基于时间图的
自监督归纳学习技术,专门用于检测LM路径。
4.3.1 预处理、威胁样本增强
制定一个切实可行的横向移动(LM)检测方法需要对最近的攻击场景和策略有充分的了解。同时,解决机器学习技术中遇到的样本偏差问题也非常关键。然而,获取现实世界中的LM攻击数据众所周知非常困难。
出于这些原因,我们在Jbeil的预处理管道中嵌入了一个基于何等人建立的攻击合成框架的威胁样本增强程序。该程序使用的算法基于广度优先搜索(BFS)图遍历算法。在任何企业网络架构中,我们将网络表示为一个计算图,并使用BFS算法解析所有网络节点;使得能够理解网络的联合空间、上下文和时间拓扑结构。
这一步骤对于实现符合网络性质和特征的定制化威胁样本增强至关重要。增强分为两个阶段进行。首先,随机选择节点作为攻击的立足点。其次,通过识别到可访问高价值资产的特权凭证的最短路径,然后使用这些新凭证到高价值资产的最短路径来执行LM登录。关于这种增强方案、相关生成的数据集和实验的更多细节将在后续提供。
除了从常规记录的认证日志中收集的属性外,网络实体的连接动态的其他特征并不可用。此外,所提出的模型需要一个良好的网络图表表示,以及有效的主机连接编码。
为此,我们利用主机认证日志来审查代表企业网络的动态性质以及其主机和用户的连接属性所需的图特征。生成的图特征主要基于不同主机和用户的入度和出度,这些度数用于支持Jbeil在相邻主机之间的消息传递机制。
我们注意到Jbeil默认包括只有主机之间的互动信息;然而,在学习阶段同样需要关于用户连接的额外互动信息。为了计算由不同图交互(即,主机到主机、用户到主机、主机到用户、用户到用户)引起的图特征,我们遵循提出的方法来提取图映射并随后计算图特征。这个算法用于从认证日志中提取入度图映射。下面是该算法的中文详细说明:
算法:从认证日志中提取入度图映射
该算法用于构建图表中的入度信息,用于分析目的主机每天收到的来自不同源主机和用户的认证尝试的频率。通过这种方式,可以帮助识别可能的异常模式或安全威胁,例如频繁的登录尝试可能表明有横向移动或凭证填充攻击的风险。
-
输入:认证日志
AuthLogs -
输出:图映射
GraphMap:包括InUsrMap,InSrcMap,InUsrSrcMap -
过程:
算法 1: 从认证日志中提取入度图映射 输入: AuthLogs - 认证日志 输出: GraphMap - 包含 InUsrMap, InSrcMap, InUsrSrcMap 的图映射 过程: 1. 定义 INDEGREES 函数,参数为 GraphMap 和 x 2.1 遍历 AuthLogs 中的每条记录,每条记录包含 ts(时间戳),Src(源主机),Usr(用户), Dst(目标主机) 1. 如果 Dst 不在 GraphMap 中: 在 GraphMap[Dst] 创建一个新的空字典 2. 如果 Usr 不在 GraphMap[Dst] 中: 在 GraphMap[Dst][x] 创建一个新的空字典 3. 计算天数 day,day = ts / 86,400 4. 如果 day 不在 GraphMap[Dst][x] 中: 在 GraphMap[Dst][x][day] 中为 day 初始化计数为 0 5. 将 GraphMap[Dst][x][day] 的计数增加 1 2.2 完成所有记录的遍历 3 返回 GraphMap 注释: - 此函数通过处理认证日志来构建目标主机每天收到的认证尝试的计数。 - x 是一个变量,可以是 Src, Usr 或 Src_Usr,表示不同类型的图映射。
4.3.2 Jbeil:基于时间图的归纳学习推断LM
在本研究中,我们提出了一种名为Jbeil的基于时间图的归纳学习方法,该方法源于时间图网络(TGN)来处理表示为企业网络中时间序列认证事件的动态图。动态图主要以其随时间演变的特性和连接性为特征。正如先前所提出的,企业网络本质上是不断演变的,并包括主机、用户、虚拟化环境和应用程序等活跃节点,这些节点不断或反复地交换认证事件。与此同时,威胁行为者渗透并在动态企业网络中传 播,以侵害目标节点,同时规避传统的检测技术。为此,Jbeil独特地支持表示为时间戳认证事件序列的连续时间动态图,以计算图节点的时间嵌入,从而从时间和拓扑数据中学习。
4.3.2.1 时间节点记忆
- 问题:横向移动(LM)攻击的本质是持久的,并且在很长一段时间内可能不被检测到。
- 方法:在这方面,我们利用Jbeil的记忆模块来保留图中每个节点的长期依赖关系。对于在时间发生的每个交互事件,我们计算每个参与交互节点的记忆 。计算出的记忆代表了每个节点的交互历史,每当节点参与交互事件时就会计算一次。
例如:
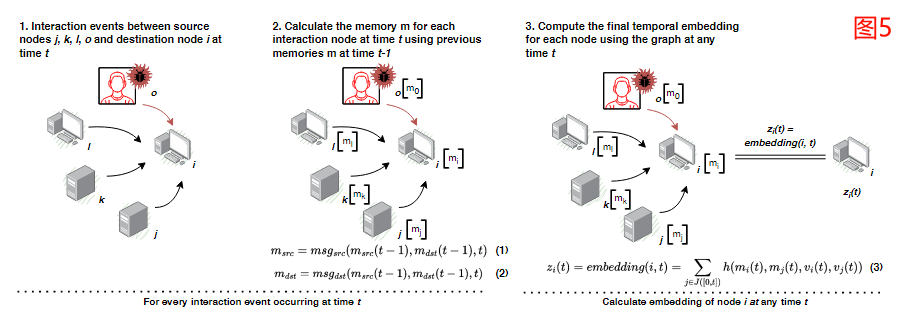
例如,考虑图5,它在时间t展示了一个交互事件,其中节点i是目的节点,节点j、k、l、o是源节点。我们注意到节点o之前已被泄露,这意味着它在t-1 时的记忆已经包含了反映这种情况的信息。因此,如图2所示,新计算的节点i的记忆实际上将受到包括节点o在内的所有邻近节点的影响。在时间t发生的任何交互事件中,源节点和目的节点的记忆分别使用方程1和方程2来计算。
在这项工作中,我们使用msg()函数作为输入的简单串联。此外,msg()是一个可学习的函数,使用递归神经网络(即门控循环单元GRU)进行更新,每当在时间t 涉及两个节点的事件发生时进行更新。
总之,利用 Jbeil 中的记忆模块对于在动态企业网络中的学习非常重要,因为它能够存储并应对节点的长期信息(即交互历史),这在解决LM问题时至关重要。
4.3.2.2 时间节点嵌入、推断和训练
接下来,我们利用Jbeil的嵌入模块计算每个时间点的节点i的时间嵌入,通过聚合所有邻近节点的时间节点记忆以及其自身之前计算的图特征(回顾§4.3.2.1)。
例如,图5的第3步展示了使用方程3计算时间t时节点i的最终时间嵌入的过程。h()是一个可学习的函数,可能包括不同的公式,如一个简单的身份函数,它使用记忆作为节点嵌入,或者一个注意力函数(Jbeil使用注意力来确保足够的可见性),它从L跳时间邻域聚合信息。
**s(t)和v(t)分别代表当前节点记忆和节点特征向量**。
\text{因此,计算节点 }i\text{ 的时间节点嵌入 }z_i(t)\text{ 涉及其所有时间邻近节点}j\in J\text{。}
计算节点的时间嵌入可以解决由不活动引起的陈旧问题,这种情况发生在节点不再更新其记忆时,导致它变得停滞。这个问题发生在一个过程长时间处于休眠状态或当用户长时间处于闲置状态时。时间嵌入可以缓解这个问题,因为它严重依赖于邻近节点的记忆和特征**。最后,在将连续时间动态图映射到节点嵌入后,我们利用Jbeil的解码器,它接收一个或多个节点嵌入,并通过提供认证事件(路径/边)的概率来执行链接预测**。
Jbeil使用自监督方法训练,利用良性和恶意认证事件的时间和拓扑数据来检测LM活动。与仅从常规数据中学习(如在最先进的技术中实施的那样)相比,这限制了对新颖LM攻击场景的推断(如在§4.2.2中所示),Jbeil拥有使用之前讨论的增强方法成功捕获这些场景的独特能力(见§3.1.1)。
五、评估
在这里,我们对 Jbeil 进行了彻底的实验和评估,以证明其对企业网络中各种 LM 攻击的有效性。
目标是评估其在不同 LM 攻击活动下的检测指标,通过检测以前看不见的节点/边缘/攻击来验证其归纳能力,同时证实了其相对于最先进方法优越的转导能力。此外,出于实际和可扩展性的原因,还对其时间复杂度和推理时间进行了基准测试和验证。
5.1 系统设置
我们在Jetstream Cloud中使用TG-CIS200038配额开发、训练和测试Jbeil。
主机系统由一个基于GPU的虚拟机组成,规格为g3.xl(32 vCPU、125GB RAM、60GB HDD和250GB临时存储),部署了Ubuntu 20.04.4镜像和Docker Engine v20.10.12。在实验过程中,使用了NGC的pytorch容器镜像 "nvcr.io/nvidia/pytorch - 22.05-py3" 作为开发环境。容器中预安装了Torch v1.11.0+cu113,并添加了igraph v0.9.11以支持所有实验。
5.2 数据集
5.2.1 LANL和Pivoting数据集
在我们的研究中,我们利用了从**洛斯阿拉莫斯国家实验室(LANL)**的企业内部计算机网络中的各种来源收集的去标识化数据集。 数据收集跨越了58天,包括良性认证日志和一组预定义的红队活动。实证数据源自基于Windows的桌面计算机和活动目录服务器。
此外,我们还使用了匿名化的Pivoting数据集,该数据集由位于大型组织中的探针捕获的真实网络流量组成。网络流量在整个工作日内收集,代表了内部主机之间的通信,以及被标记为枢纽活动一部分的流量。这样的基于网络的数据集可以有效揭示有助于在大型动态企业网络中建模和检测横向移动(LM)的内部活动兴趣。
| Dataset | Nodes | Edges | Type | Duration |
|---|---|---|---|---|
| LANL | 15,610 | 49,341,300 | 网络认证日志 | 58 Days |
| Pivoting | 1,015 | 74,551,643 | 网络流量数据 | 1 Day |
5.2.2 威胁增强数据
我们的方法采用了一种攻击合成框架,即**横向移动模拟器, 能够生成各种实际的攻击场景和策略,以实际增强Jbeil的威胁样本数据**。该框架为特定(专有)数据集设计和实现的,因此默认情况下不适用于其他认证日志数据集。因此,该工具及其生成的攻击没有被借用或直接应用于Jbeil和LANL数据集。特别是,我们做了大量的努力来修改其设计和实现,使其能够接受任何认证数据集。
此外,为了生成多次攻击,我们开发了两种辅助方法: 第一种用于生成 n个横向移动攻击,第二种用于将这些攻击嵌入到良性数据集中;在这里,我们使用包含常见认证日志的LANL数据集。为此,使用我们修改后的工具版本,我们生成了与LANL网络基础设施特别匹配(并且与之相符)的真实横向移动攻击条目。生成的条目从随机日期和时间开始,以创建随机性。我们首先随机选择LANL数据中的节点作为初始受害者,其机器作为攻击者发起横向移动(即建立立足点)的受损立足点。因此,对于每个选定的受害者,我们生成不同的攻击场景。生成的攻击场景及其相关实验在§4.4.2中详细阐述。
5.3 评价指标
- Precision Score 精确度
- 公式:\mathrm{Precision}=\frac{TP}{TP+FP}
- 功能 : 量化正类预测的准确性;衡量正确推断横向移动(LM)的质量。
- Recall Score 召回率
- 公式:\mathrm{Recall}=\frac{TP}{TP+FN}
- 功能 : 衡量模型预测实际正类的能力;评估识别横向移动的效果。
- Average Precision 平均精确度
- 公式:AP=\sum_n(\mathrm{Recall}_n-\mathrm{Recall}_{n-1})\times\mathrm{Precision}_n
- 功能 : 汇编精确度和召回率曲线,作为每个阈值处精确度的加权平均值。
- AUC Score 曲线下面积分数
- 公式:TPR={\frac{TP}{TP+FN}}\mathrm{and}FPR={\frac{FP}{FP+TN}}
- 功能 : 量化真正类与假正类比例;通过绘制真正类率和假正类率的曲线来测量。
5.4 实验
5.4.1 归纳推理实验
由于Jbeil支持归纳学习和自监督学习,我们明确地对一组随机选择的节点及其相连的边进行遮蔽,仅在可见的节点/边上进行训练。在这个评估中,我们尝试仅通过已知事件的学习来推断/测试(以前)未知/未见的攻击。
我们注意到,遮蔽过程不会影响数据中认证事件的时间序列。鉴于企业网络本质上是动态的,并且不断涉及新出现的网络实体,我们在此进行了三项实验,展示了Jbeil在预测未见节点/边上的LM路径的独特归纳能力。
为了实现这一点,我们在LANL数据集中随机遮蔽了不同比例(即30%,40%,50%)的节点和边,以进行归纳性测试。我们多次运行实验以验证结果的一致性。注意,遮蔽的节点在测试阶段从未被引入。表2通过归纳推理实验展示了Jbeil的结果。对于每个实验,我们使用特定数量的训练节点训练Jbeil,然后利用之前看到的测试样本进行传导评估。随后,使用相同的训练模型,我们使用遮蔽的节点进行归纳测试,从而评估Jbeil对未见节点的性能。在每个实验中,我们减少了训练节点的数量,并相应减少了传导测试样本,另一方面,我们增加了归纳测试样本的数量,以展示Jbeil在不同级别的能力。此外,我们在10个周期内使用0.005的学习率和5的 patience factor 训练Jbeil。
在机器学习中,特别是在使用神经网络进行训练时,“patience factor”是一个在早停(early stopping)策略中使用的术语。早停是一种用来防止模型过拟合的技术,它涉及到在验证集上的性能不再提升时停止训练。在这种情况下,“patience”指的是在训练过程中,我们愿意等待多少个训练周期(epochs)而不见性能提升后,才决定停止训练。
如果你设置了一个“patience factor”为5,这意味着当模型在连续5个训练周期中在验证集上的性能没有改善时,训练过程将会停止。这是一种避免浪费计算资源和时间的有效方法,同时也帮助模型在达到一定的训练水平后不会因为过度训练而开始退化。
5.4.2 实验1 (遮蔽30%)
我们随机遮蔽了LANL数据集的30%(15,610 * 0.3 = 4,683个节点)作为未见测试样本,以评估Jbeil的归纳性能。
参照表2,我们使用9,886个节点训练Jbeil,并使用之前看到的1,041个节点进行传导评估。Jbeil分别取得了99.82%,99.80%,99.22%和98.93%的AUC,AP,召回率和精确度分数。这些结果实际上非常高,因为传导测试中的节点都是在训练期间引入的。现在,使用在训练期间未曾见过的4,683个节点,Jbeil分别取得了99.73%,99.63%,99.25%和98.48%的AUC,AP,召回率和精确度分数。这些归纳测试结果与传导测试结果几乎相同,展示了Jbeil在未见节点上泛化的独特能力。因此,我们从实验1得出结论,Jbeil能有效地学习认证事件的时间顺序性和语义,并成功预测在不断演变的企业网络中30%未曾见过的节点上的LM路径。这种在未见节点上的变化可以与未处理的威胁指标、利用隐蔽LM路径的隐蔽0-day攻击、缺乏广泛数据可见性或与新出现的主机/用户相关联的新节点的出现联系起来。
5.4.3 实验2 (遮蔽40%)
随后,在实验2中,我们通过将遮蔽节点数量增加到40%(15,610 * 0.4 = 6,244个节点),相应地只使用8,423个节点训练Jbeil。我们在表2中观察到,对942个样本进行的传导测试评估出现下降,Jbeil的AUC得分为94.76%,下降了近5%。
在训练过程中减少节点数量直接对计算节点嵌入所需的邻近节点数量产生负面影响,因此在有效学习良性和恶意(即LM路径)认证事件的时间序列性和语义上出现衰退。
由于我们使用相同的训练模型进行归纳评估,我们观察到测试结果中类似的下降,未见节点的AUC得分达到了94.59%。尽管结果低于实验1,但我们仍可以推断Jbeil对新出现的图节点和交互仍具有鲁棒性和泛化能力,并且能够在40%的网络实体是新出现的情况下,执行演变企业网络中的LM链接预测。
5.4.4 实验3 (遮蔽50%)
在这个实验中,我们将归纳节点数量进一步增加到50%(15,610 * 0.5 = 7,805个节点),并只在6,943个节点上训练Jbeil。实际上,这个实验属于极端归纳情况,其中未见节点数量超过了训练期间使用的已见节点数量。
尽管如此,这种情况可以帮助我们了解Jbeil的最大能力,并为我们提供有价值的建议和指导,以实现演变企业网络中成功的LM路径预测。
表2显示了在862个可见节点上的AUC得分为75.62%,在7,805个遮蔽节点上的AUC得分为74.55%。在这种特定情况下,训练节点和边的数量明显少于测试(遮蔽)节点和边的数量。因此,Jbeil中的消息传递、聚合和抽样受到负面影响,最终影响计算的时间节点嵌入。具体来说,这些嵌入由于训练期间邻近节点数量有限,无法从其空间和时间邻域(连接节点和链接边)中捕获足够的知识。然而,在测试阶段,之前遮蔽的节点和边变得未遮蔽,从而为图添加了大量Jbeil在训练期间未遇到的信息。训练和测试数据集之间的这种差异最终影响了Jbeil在预测新样本结果方面的表现。尽管如此,这些实验清楚地突出了Jbeil的极限,同时提供了关于我们方法的训练和测试策略的独特且实用的见解。
5.4.5 基于Pivoting dataset数据集的实验(遮蔽40%)
为了建立我们方法的泛化性,我们基于Pivoting数据集对Jbeil进行了全面评估。
我们首先遮蔽原始数据集的40%(即1,015*0.4 = 406个样本节点)以生成未见测试集,然后在其余数据上训练模型。这次评估的结果显示在表3中,显示出了98.26%的AUC得分和99.09%的精确度,证明了Jbeil对不同网络基础数据集具有优秀的泛化能力。此外,这些结果强调了Jbeil独特的归纳能力,即使对于训练期间从未遇到的节点,也能一致地提供高质量的预测。
5.4.6 增强威胁样本实验
通过将清除了红队活动的LANL数据集引入我们自行修改的Ho等人的实证攻击合成框架,我们特别生成并植入了一系列符合LANL网络系统和数据分布的真实世界横向移动(LM)攻击。
随后,我们将这些攻击嵌入到LANL数据集中,最终在Jbeil的预处理管道中实现样本增强机制。在这个攻击合成框架中,可以设置不同的参数来定义实际的LM攻击,这些参数包括攻击者的隐蔽性、目标和网络知识;我们利用这些参数生成独特且真实的攻击场景。具体来说,攻击框架根据预定义场景的参数生成登录,例如,这些参数用于指定攻击何时成功以及攻击者如何在网络中移动,同时保持攻击者对网络的了解程度。攻击框架生成并整合了1,801个真实的LM攻击到LANL数据集中。这些攻击被组织成三个不同的攻击场景(如下所述)。对于每个场景,LM攻击框架随机选择目标节点。
场景1:在这里,攻击者只了解他们之前操控过的机器的历史,一旦获得了其初始受害者未曾拥有的系统访问权,攻击便停止产生新的登录。攻击框架在LANL数据集中生成了695次这样的攻击。
- 在场景1中,时间点t1的节点数量为55,t2为115,t3为160。
场景2:攻击者了解整个网络拓扑。攻击在访问了50台设备或者用最终的凭证集登录到每台可访问的机器后终止。此外,攻击者只生成跨越有效用户已经遍历的边缘的登录。攻击框架在LANL数据集中生成了 606次这样的攻击。
- 在场景2中,t1时的节点数为59,t2为101,t3为151。
场景3:在这里,攻击者了解整个网络拓扑,并通过多次登录进行攻击,直到获得对高价值服务器的访问权。在这种情况下,攻击者不仅创建穿过有效用户已经通过的边缘的登录,而且只使用其授权用户最近登录到源机器的一组凭证。攻击框架生成了500次这类攻击,并将其整合到LANL数据集中。
- 在场景3中,t1、t2、t3的节点数量分别为53、85和120。
将获得的恶意数据与原始的LANL数据集合并后,我们训练Jbeil来评估其检测这些新威胁的能力。
我们针对这三种不同的攻击场景进行了三项实验;在9,886个可见节点上训练Jbeil,同时对1,041个可见测试样本进行传导测试。因此,Jbeil成功地检测到了这三种场景,分别获得了99.66%、99.54%和 99.54%的AUC得分。此外,我们还在4,683个归纳节点上测试了Jbeil(这些节点在训练阶段从未被见过)。与在已见节点上取得的结果类似,Jbeil成功地检测到与攻击场景1、2和3相关的LM路径,分别获得了99.61%、99.60%和99.54%的AUC得分。
5.4.7 Jbeil的效率和可扩展性
Jbeil 在设计时考虑了实用性和可扩展性。为了验证这一假设,我们在不同网络环境下,针对归纳和传导训练的时间复杂度进行了基准测试。
具体来说,我们使用LANL数据集产生了多个子图,这些子图具有不同数量的节点和边,并评估了Jbeil训练所需的时间。图7显示,Jbeil的训练时间复杂度与边和节点的数量高度相关。
例如,在传导情况下,当节点数量为14.9K且边数为34M时,时间复杂度非常高;达到5,054秒,内存使用量为6GB。这清楚地显示了在面对大型企业网络中大量节点和边时,传导推理的影响。
另一方面,在归纳情况下,部分节点和边被掩盖,例如当节点数量为9.9K且边数为2.1M时,时间复杂度显著降低,仅为303秒,内存使用量为1.5GB。这反映了Jbeil归纳推理在确保完美结果(参见表2和表4)的同时,保证了可扩展性和效率的关键重要性。在进行了众多实验后,我们观察到Jbeil的LM推理时间取决于图的大小(节点和边)。
在对已见和未见的节点及边进行评估时,我们发现推理时间从12秒(针对有100万边的图)到5分45秒 (针对有3000万边的图)。因此,我们注意到,在大型且动态的网络环境中,Jbeil在计算资源有限、训练和响应时间受限或情报处理稀疏时,具有可扩展性和效率。
5.4.8 Jbeil与 Baseline 比较
-
Jbeil 与 Euler 相比较,后者是用于横向移动(LM)检测的现有最先进的传导图形基方法。我们首先获取了 Euler 的源代码,并成功编译了四个不同版本以测试其在检测 LM 路径方面的效果。在这些实验中,我们评估了 Euler 在 LANL 红队攻击以及攻击框架生成的三个攻击场景下的表现。表5总结了 Euler 在这些攻击中的表现结果。sEuler 在检测红队攻击中表现相当好,AUC 为 96.96% (Euler 的 GCN-GRU 版本);这与作者之前在这种设置下报告的结果完全相同。然而,Euler 在检测三个生成的 LM 场景时表现不佳,分数低至场景1的 36.87% 和场景2的 55.70%。Jbeil 在所有攻击集中的表现都优于 Euler。我们认为 Euler 在三个 LM 攻击场景中检测率低的原因是,它仅在固定的离散时间动态图(即图的快照)上学习,使用的是良性数据。因此,模型并未完全理解攻击的语义。此外,Euler 不添加实体特征,而仅考虑节点及其交互。
“它仅在固定的离散时间动态图(即图的快照)上学习,使用的是良性数据”指的是 Euler 模型在训练过程中使用的数据和方式。具体来说:
- 固定的离散时间动态图(图的快照):这意味着 Euler 使用的数据是按照固定时间点捕捉的网络状态,即网络在某一特定时间点的静态表示。这些快照不连续,并且可能无法捕捉到攻击发生过程中的连续和动态变化。
- 使用的是良性数据:这表明在训练 Euler 模型时,使用的数据主要是正常或非恶意的网络活动数据。这种数据的使用可能导致模型未能学习到足够的恶意行为特征,因而在面对真实的或模拟的攻击场景时,检测能力不足。
-
我们与 GraphSAGE 进行了比较分析,后者是大型图中归纳推理的知名方法。尽管 GraphSAGE 并非专为 LM 检测和网络安全量身定制,但我们使用了 PyG 的 GraphSAGE 实现,这使我们能够完全实施它并进行全面比较。我们发现,虽然 GraphSAGE 已被证明对基于图的机器学习有效,但它无法整合时间方面或考虑图的持续时间动态性质,以及缺乏网络安全数据增强,这在实际的安全应用如 LM 检测中构成了重大挑战。这些限制在表5中展示的结果中反映出来,显示了 GraphSAGE 在四种不同场景中的表现不如 Jbeil 出色。
-
不同的是,
Jbeil 最重要的贡献之一在于其创新的连续时间表示。与静态时间或离散时间动态等替代 时间表示相比,Jbeil 的连续时间动态能力被证明特别有利。为了评估 Jbeil 的时间表示的有效性, 我们进行了实验比较了 Jbeil 在去除时间方面后的变体性能。我们的结果,展示在表6中,清楚地显示了 Jbeil 的连续时间动态表示优于静态时间表示。此外,我们还发现 Jbeil 的表现超过了 Euler 的离散时间动态方法,进一步支持了 Jbeil 时间表示的强度。
5.4.9 Jbeil的应用前景
在大型企业网络中推断横向移动(LM)的任务对现有的安全信息和事件管理(SIEM)及网络检测和响应(NDR)系统来说复杂且具有挑战性。
然而,将 Jbeil 集成到这些系统中可以通过先进的横向移动检测增强安全数据,从而提高合作、自动化、威胁分析、事件响应和缓解能力。这可以通过使用诸如 Google Cloud Pub/Sub、Syslog 或 Logstash 等模块来收集和传递 Jbeil 生成的安全日志到其他第三方安全解决方案来实现。
六、Related Work
现有基于图的横向移动和APT检测方法
King和Huang提出了Euler,这是一种先进的离散时间动态图神经网络,能够实现可扩展的动态链接预测。
Euler使用LANL数据集进行测试,目标是在APT活动期间检测横向移动。其他如ShadeWatcher、Depcomm、Threatrace和APT-KGL等工作,采用了基于图的方法,包括基于图的推荐系统、图总结、 GraphSAGE和异构溯源图,以助于主机基础的APT总结、检测和追踪。
图相关的进步、挑战与机遇
在使用图进行节点分类、链接预测和聚类的挑战中已取得重大进展。
该领域的重要贡献包括:
- Grover和Leskovec的node2vec,它提出了一个算法框架,用于学习网络中节点的连续特征表示;
- Perozzi等人的Deepwalk,它提供了一种学习网络顶点潜在表示的可扩展方法;
- Ahmed等人的图因子分解(GF),它提出了一个大规模图分解和推断的框架,可以将图分布在多个系统上,每个部分都减少了邻近节点的数量。尽管取得了有希望的结果和进展,但在网络安全中使用的基于图的技术仍存在局限性,包括推理约束和对动态环境的不充分表现,这使得无法准确建模大型企业网络。
我们的方法Jbeil使用TGN,这是一个在连续时间动态图上操作的深度学习框架,并通过基于归纳的学习确保对未见数据点的泛化性。
七、文章图表解释
图表编号与论文中的不是完全一一对应的
图表1:总流程
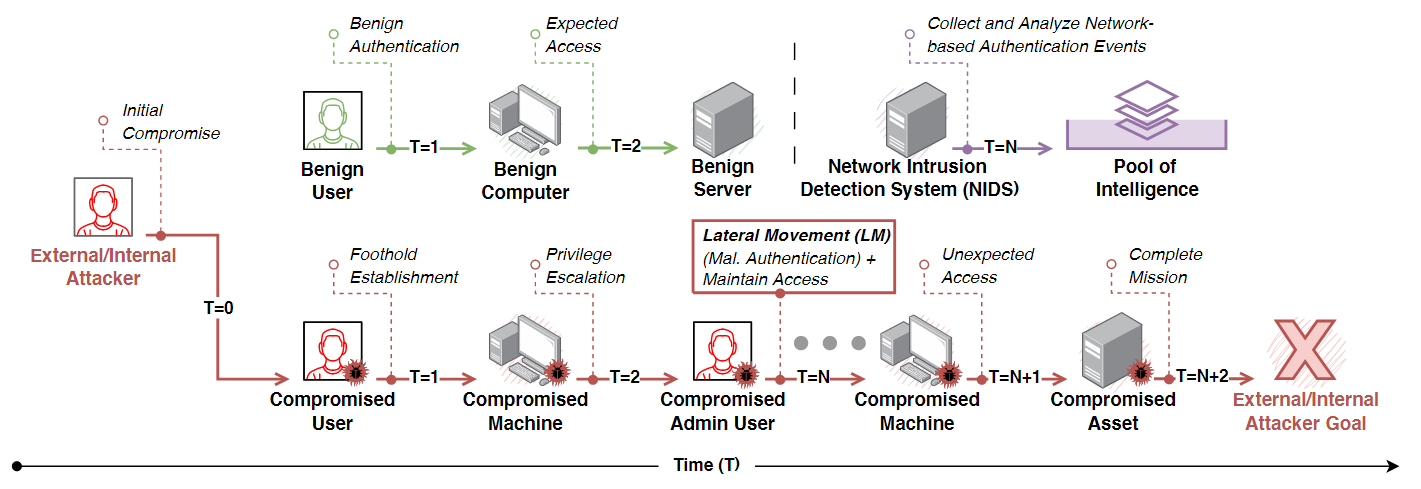
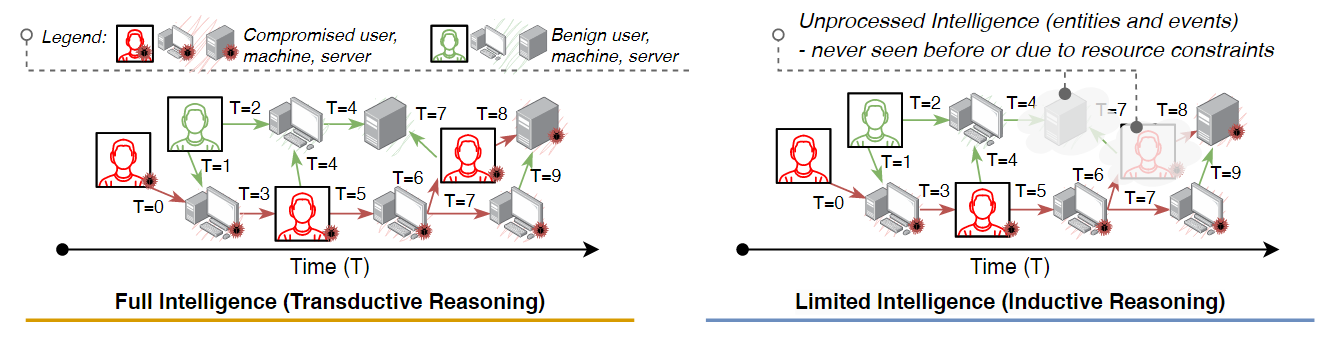
这张图是一个关于网络安全和入侵检测系统的概念模型。它展示了一个被称为Jbeil的系统如何在一段时间内检测和推断网络中的横向移动(Lateral Movement, LM)攻击。
1.上方的流程图
- 从左到右代表时间的推移( T=0至T=N+2 )
- 起始点为一个外部/内部攻击者在 T=0 的时间点初始侵入(Initial Compromise)
- 然后展示了攻击者如何获得对用户的控制(Compromised User)并随着时间推移不断提升权限,进而控制更多的机器(Compromised Machine)
- 在此过程中,
网络入侵检测系统(Network Intrusion Detection System, NIDS)收集和分析基于网络的认证事件,这些数据进入智能池(Pool of Intelligence) - 有两种类型的事件:预期的访问(Expected Access)和意外的访问(Unexpected Access),意外的访问可能表明了潜在的横向移动。
- 随着时间的推移,攻击者尝试维持对网络的控制(Maintain Access),并在网络中进行横向移动。
- 最终,攻击者可能会达到他们的目标(External/Internal Attacker Goal),这通常意味着对敏感数据或资源的控制。
2.下方的对比图
这张图总体上提供了一个关于如何在时间维度上理解和检测网络威胁的视角,强调了利用数据和时间序列分析进行威胁检测的重要性。
- 展示了完全智能(Full Intelligence, Transductive Reasoning)与有限智能(Limited Intelligence,Inductive Reasoning)在处理未处理的智能(Unprocessed Intelligence)时的区别。
- 在“完全智能”中,系统可以看到所有的实体和事件,并且以一种连贯的方式推理(例如,将T=0到T=9的所有活动都视为相关)
- 而“有限智能”则可能会漏掉一些事件,因为这些事件要么是前所未见的,要么是因为资源限制而未能处理的。
- 图中用红色突出显示了攻击者的行为(Compromised user/machine),绿色表示正常行为(Benign user/machine)
图表2:网络节点变化特点
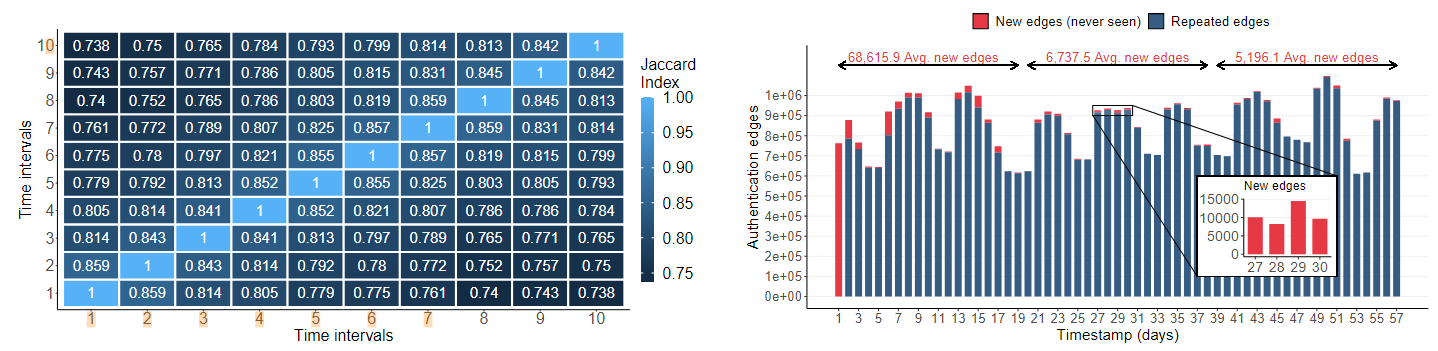
这两张图是对网络中实体(如用户、计算机和服务器)之间认证事件动态性的实证分析。它们显示了在不同时间段内,网络的节点和边(即认证事件)是如何变化的。
1.左侧图表
这是一个热图,显示了10个不同时间间隔内的节点相似性,使用的是Jaccard相似性指数。
热图的颜色从深蓝(较低的相似性)到浅蓝(相似性为1,即完全相同)变化。
- 时间间隔(Time intervals):垂直轴标出了10个时间段。
- Jaccard Index:数值介于0到1之间,表示节点之间的相似性。值越接近1,相似性越高。
图表显示从第一个时间间隔到最后一个时间间隔,节点相似性平均下降了26%。这表明网络中认证实体(如用户或计算机)的组成随时间变化相当大,强调了网络的动态和演变特性。
2.右侧图表
这是一个柱状图,描述了整个58天中每天新出现的边(认证事件)数量。
- 红色柱状:表示那天观察到的新边(从未见过)
- 蓝色柱状:表示重复的边(以前见过)
图中的趋势线显示平均新边的数量,分别为68,615个和6,737个,以及在数据集最后一个阶段的5,196个平均新边。这个变化可能指示网络内部的行为和结构正在发生变化。
特别地,在第27天到第30天的时间框中,可以看到一个显著的峰值,代表在这些特定日子中出现了许多新的认证事件。这可能是网络配置变更、新设备/用户加入网络、或者潜在的安全威胁如未授权访问。
这两张图共同说明了在动态和不断演变的企业网络中,节点和边的结构随时间急剧变化。这种变化的环境使得利用静态安全策略进行威胁检测变得更加困难,从而强化了需要动态和适应性强的安全系统来检测和反应于横向移动攻击的论点。
图表3:预处理
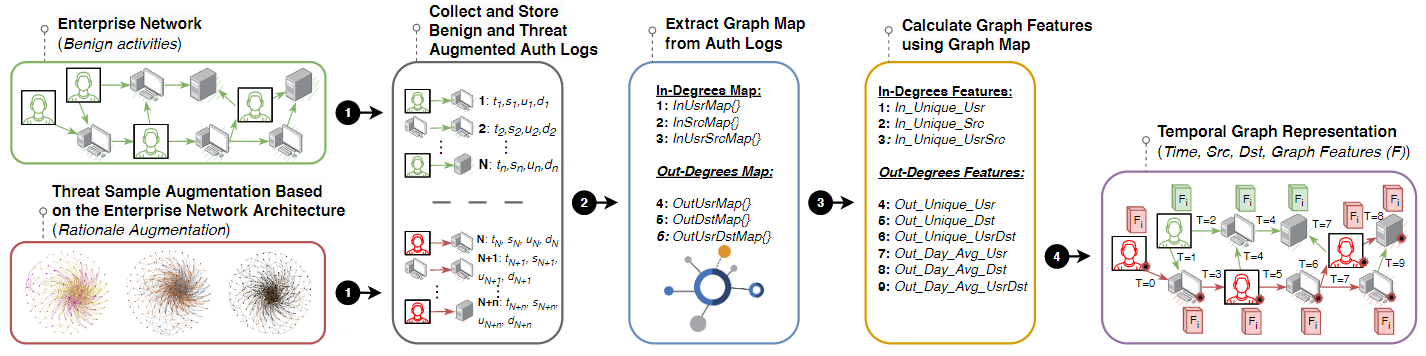
展示了我们遵循的预处理流程,以提取图特征和构建图表示。
为横向移动行为的检测提供了数据支持,还增强了数据的语义深度,使其能够更准确地反映网络内的实际互动和行为模式。
第一步:属性提取
(时间戳(t), 源主机(src), 目标用户(usr), 目标主机(dst))
我们首先从常规收集的认证日志中提取属性,这些属性包括时间戳(t)、源主机(src)、目标用户(usr)和目标主机(dst)。此外,也包括与我们增强的威胁样本相关的认证日志。这些数据被用作后续步骤中图构建的基础。
第二步:图映射提取
基于第一步收集的数据,我们生成一组字典,这些字典代表网络中每个主机和用户之间的连接。
这一步骤至关重要,因为它帮助我们维持用户交互信息的完整性,尤其是在目标用户属性在最终图表示中被省略的情况下。
第三步:图特征生成
在获取了图映射后,我们遍历所有认证事件来生成新的图特征。
这包括计算每个目的地和源主机的用户、主机和用户-主机组合的数量,以及它们的日均交互频率。这些特征为后续的模型训练提供了丰富的语义信息,有助于揭示网络中的动态行为和用户连接动态。
第四步:时间图结构表示
认证事件的时间戳 t ,源主机 src ,目标主机 dst ,事件标签 l ,源图特征 v_{src} , 目标图特征 v_{dst}
最后,在图4的第四步中,我们将前面步骤格式化的认证日志与计算得到的特征结合起来,并添加认证事件的标签(即,恶意或良性),以产生最终的图表示。这个图将定义为( G=\{et_0,et_1,et_3,\ldots\}),其中每个事件(e)包含了认证事件的时间戳(t),源主机(src),目标主机(dst),事件标签(l),以及源和目标的图特征(v_{src})和(v_dst)。
图表4:时间节点构建
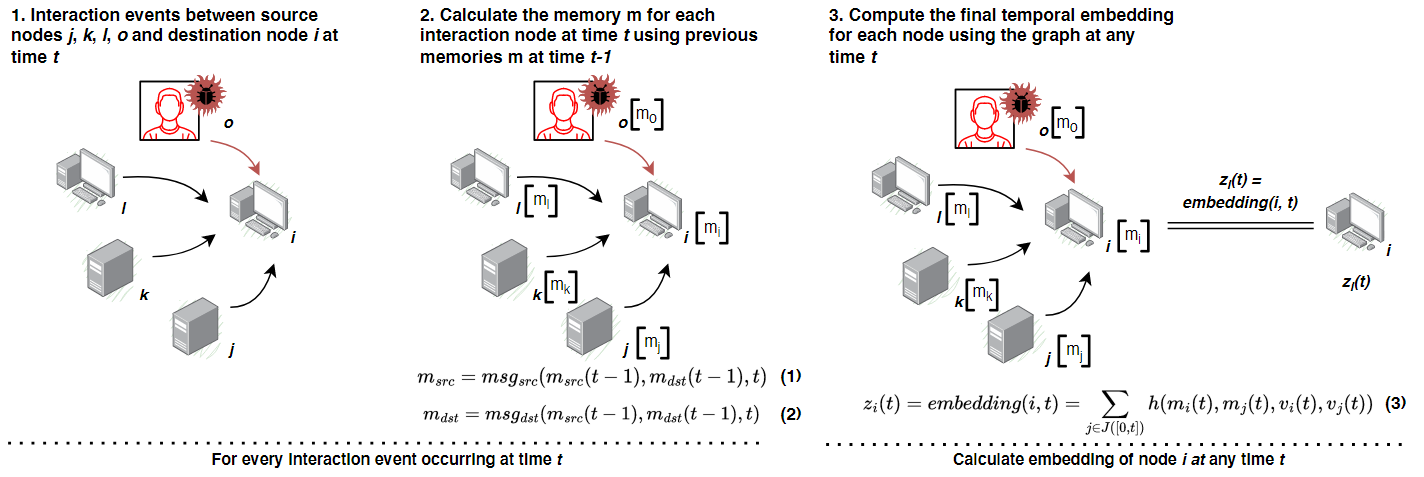
总体解释
这个过程展示了Jbeil如何处理网络中的动态交互,通过学习和更新节点的时间记忆以及计算时间嵌入,以反映每个节点的历史和当前交互情况。
每个节点的时间记忆和嵌入更新考虑了与其他节点的交互,特别是在面对网络安全威胁(如从受损节点o的影响)时,如何通过学习网络中的动态信息来更好地捕捉和响应潜在的威胁。
第一步:交互事件
描述了节点j、k、l、o和目的节点i在时间t发生的交互事件。节点o被标记为一个受到威胁的节点(即被攻击或被感染),这对其记忆和后续的节点嵌入计算具有重要影响。
第二步:计算记忆
对于每个参与交互的节点(j、k、l、o和i),都使用它们在时间的记忆来计算新的记忆。这里使用的函数是msg_src 和msg_dst ,分别为源节点和目的节点更新其记忆。记忆的更新考虑了节点之间的交互和节点自身先前的状态。
图中展示了节点i接收其他节点(j、k、l、o )的影响,并更新其记忆,这可能包括接收攻击信息(如从受损节点o)
第三步:计算时间节点嵌入
使用计算出的记忆和节点特征,为节点在时间计算时间嵌入。时间嵌入函数embedding(i, t) 利用所有相邻节点在时间t的记忆来生成节点i的综合嵌入表示。
这个嵌入表示捕捉了节点的当前状态和它与其他节点的交互历史,这对于预测节点未来的行为或状态极为重要。
图表5:归纳推理实验的结果
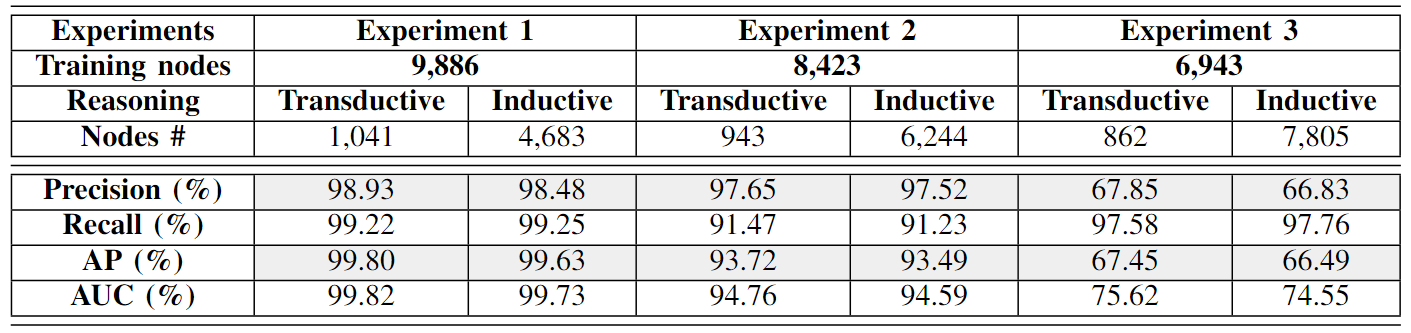
表格列出了三个不同实验的详细数据,包括训练节点数、推理类型、评估节点数,以及四个关键性能指标(精确度、召回率、平均精确度(AP)、曲线下面积(AUC))的得分。以下是这张表格内容的详细解释:
这些实验结果强调了Jbeil不仅在处理已知节点的情况下效果良好,同时也能有效处理大量未知节点,这对于动态变化的企业网络环境中的横向移动检测尤为重要。
实验设置
- 实验1:使用9,886个节点进行模型训练,并用1,041个节点进行传导评估。此外,使用剩余的4,683个节点作为归纳测试节点(未见节点)
- 实验2:训练节点减少到8,423个,增加了未见节点的比例,分别使用943个节点进行传导评估和6,244个节点进行归纳评估。
- 实验3:进一步减少训练节点至6,943个,使得未见节点比例最大化,使用862个节点进行传导评估和7,805个节点进行归纳评估。
结果分析
- 在所有三个实验中,Jbeil的归纳性能几乎与传导性能相当,表明了其在预测未见节点方面的泛化能力。
- 实验1 显示了Jbeil在面对较小比例未见节点时的高性能,AUC和AP分数都非常接近100%。
- 实验2 和 特别是在 实验3 中,随着未见节点比例的增加,性能有所下降,但仍然保持了较高的召回率,显示了Jbeil对未见节点的良好预测能力。
- 特别是在 实验3 中,尽管未见节点比例最高,但Jbeil的召回率依然接近98%,显示出其在极端归纳情况下的稳健性。
图表6:基于Pivoting dataset数据集的实验(遮蔽40%)
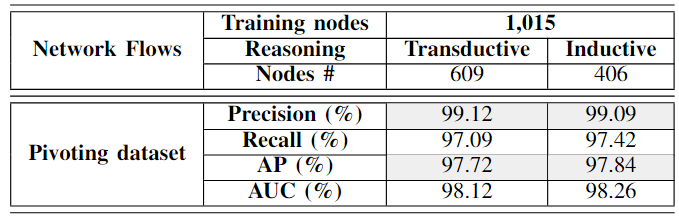
首先说明 Pivoting dataset数据集 的节点信息, 以及训练的配置。
Jbeil的归纳性能几乎与传导性能相当,表明了其在预测未见节点方面的泛化能力。
图表7:威胁增加场景效果
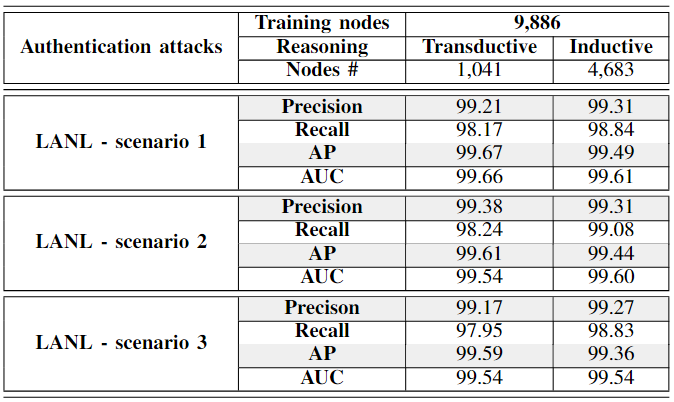
这张表格显示了Jbeil系统用于检测三种不同攻击场景下的横向移动(LM)攻击的结果。表格详细列出了每个场景下的传导测试和归纳测试的结果,包括精确度(Precision)、召回率(Recall)、平均精度(AP)和曲线下面积(AUC)。这里是各部分的解释:
表格组成
- Training nodes:用于训练模型的节点数量,对所有场景都是9,886
- Reasoning:表明测试类型,分为传导和归纳
- Nodes #:参与传导和归纳测试的节点数量
- Precision:正确预测正类的比例 TP/(TP+FP)
- Recall:正确识别的正类比例 TP/(TP+FN)
- AP (Average Precision):平均精度,衡量在不同阈值下精确率和召回率的加权平均值
- AUC (Area Under the Curve):ROC曲线下的面积,衡量模型整体性能的标准
攻击场景
LANL - scenario 1, 2, 3:描述了在LANL数据集上模拟的三种不同攻击场景的结果。
性能结果
- 传导测试(Transductive):在模型训练期间已知的节点上测试模型性能。
- 场景1中,传导测试的节点数为1,041。
- 场景2和3的节点数依次减少,表明参与传导测试的节点数量的减少。
- 归纳测试(Inductive):在模型训练期间未见过的节点上测试模型性能。
- 场景1中,归纳测试的节点数为4,683。
- 同样,在场景2和3中,这个数字表明了归纳测试的范围和强度。
分析
从表中可以看出,不管是传导测试还是归纳测试,Jbeil在所有场景下都保持了高水平的性能,AUC得分接近或超过99%,这说明Jbeil对新旧节点都具有很好的泛化能力和准确性。
同时,这些结果也表明Jbeil能够有效地从已知数据中学习并将这些知识应用于之前未见过的情况,这是网络安全操作中非常重要的能力,尤其是在应对动态变化的网络威胁时。
图表8:BaseLine 性能对比

这张表格展示了使用Jbeil模型与其他模型(Euler和GraphSAGE)在使用LANL数据集的认证日志进行横向移动(LM)攻击检测的比较实验结果。清晰展示了Jbeil在不同设置和条件下的强大性能和应用潜力,特别是在需要对新出现的威胁进行快速有效识别的情况下。
表中数据反映了各个模型在红队攻击及三种不同攻击场景中的表现,使用曲线下面积(AUC)作为性能评估标准。
表格详解
- Net. Auth. Attacks: 网络认证攻击,指定了攻击的类型和场景。
- Reasoning Approach: 表示使用的推理方法,此处为AUC。
- 列标题:
- Euler GCN-GRU: 使用GRU门控循环单元的Euler模型。
- Euler GCN-LSTM: 使用LSTM长短期记忆网络的Euler模型。
- Euler SAGE-LSTM: 使用SAGE-LSTM的Euler模型。
- Euler GAT-None: 使用图注意力网络但不采用额外技术的Euler模型。
- GraphSAGE: 独立的GraphSAGE模型。
- Jbeil: 我们提出的模型。
分类
- Transductive: 传导测试,模型在训练阶段有接触到所有节点,但没有用所有节点进行训练。
- Inductive: 归纳测试,测试模型在从未见过的节点上的表现。
性能对比
- LANL - redteam: 对真实红队数据的检测。
- LANL - Scenario 1, 2, 3: 三种不同人工生成的攻击场景的检测。
结果解读
- Jbeil在所有的攻击场景中(无论是红队还是生成的场景)表现出色,其AUC得分普遍高于其他模型,显示了它在检测LM攻击中的优越性。
- 对于传导学习,其他模型在红队数据上的表现相对较好,但在复杂的攻击场景中性能迅速下降。
- 对于归纳学习,Jbeil的性能明显优于GraphSAGE和其他模型,尤其是在处理新场景和新节点时,其AUC得分接近或超过99%,表明其出色的泛化能力。
图表9:Jbeil 的效率和可扩展性
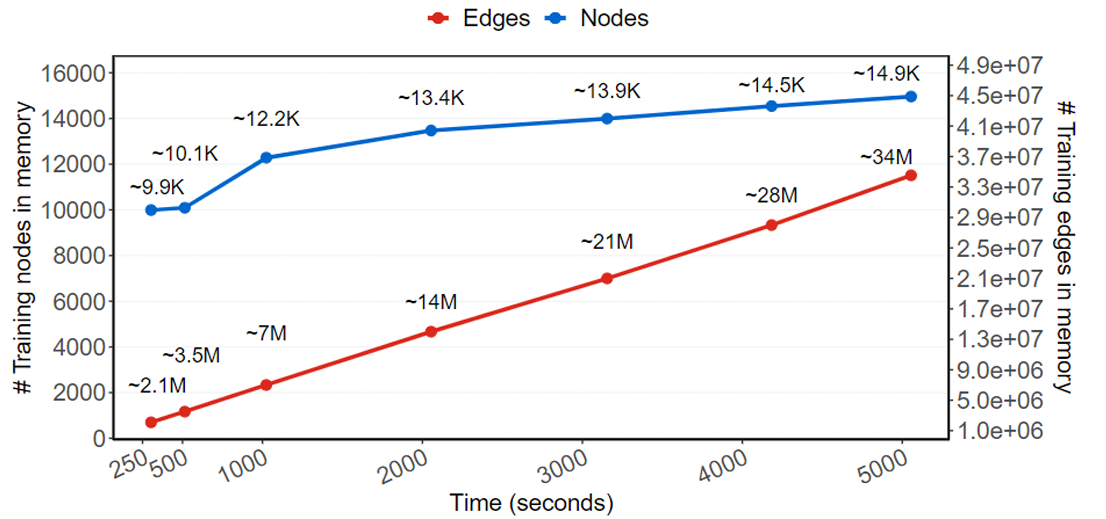
这张图展示了Jbeil在处理不同数量的节点和边的子图/子网上的时间复杂度。图中有两条曲线:
- 蓝色曲线(节点):表示随着节点数增加,训练所需的时间变化。节点数从约9.9千增加到约14.9千,对应的训练时间从少于500秒增加到接近5000秒。
- 红色曲线(边):展示随着边数增加,训练所需时间的变化。边数从约2.1百万增加到约34百万,训练时间从少于500秒增至超过4000秒。
图解分析
- 节点与时间关系:随着节点数量的增加,Jbeil的训练时间呈现出逐渐增加的趋势。这显示了当处理的节点更多时,算法处理和计算所需的时间也随之增长。
- 边与时间关系:边的数量对训练时间的影响更为显著。随着边数的显著增加,所需的训练时间急剧上升。这反映了处理更复杂或连接更密集的网络结构时,时间成本显著增加。
结论
这张图说明了在大规模网络数据中,Jbeil的时间复杂度随着网络大小(节点和边的数量)的增加而增加。特别地,处理边密集的网络比处理节点多的网络需要更多的时间,这可能是因为边的数量直接影响了图中信息传递和处理的复杂度。这种性能趋势对于评估Jbeil在大型企业网络中的可行性和效率具有重要意义,尤其是在需要快速响应的情况下。
图表10:增强威胁数据集的FR时间图
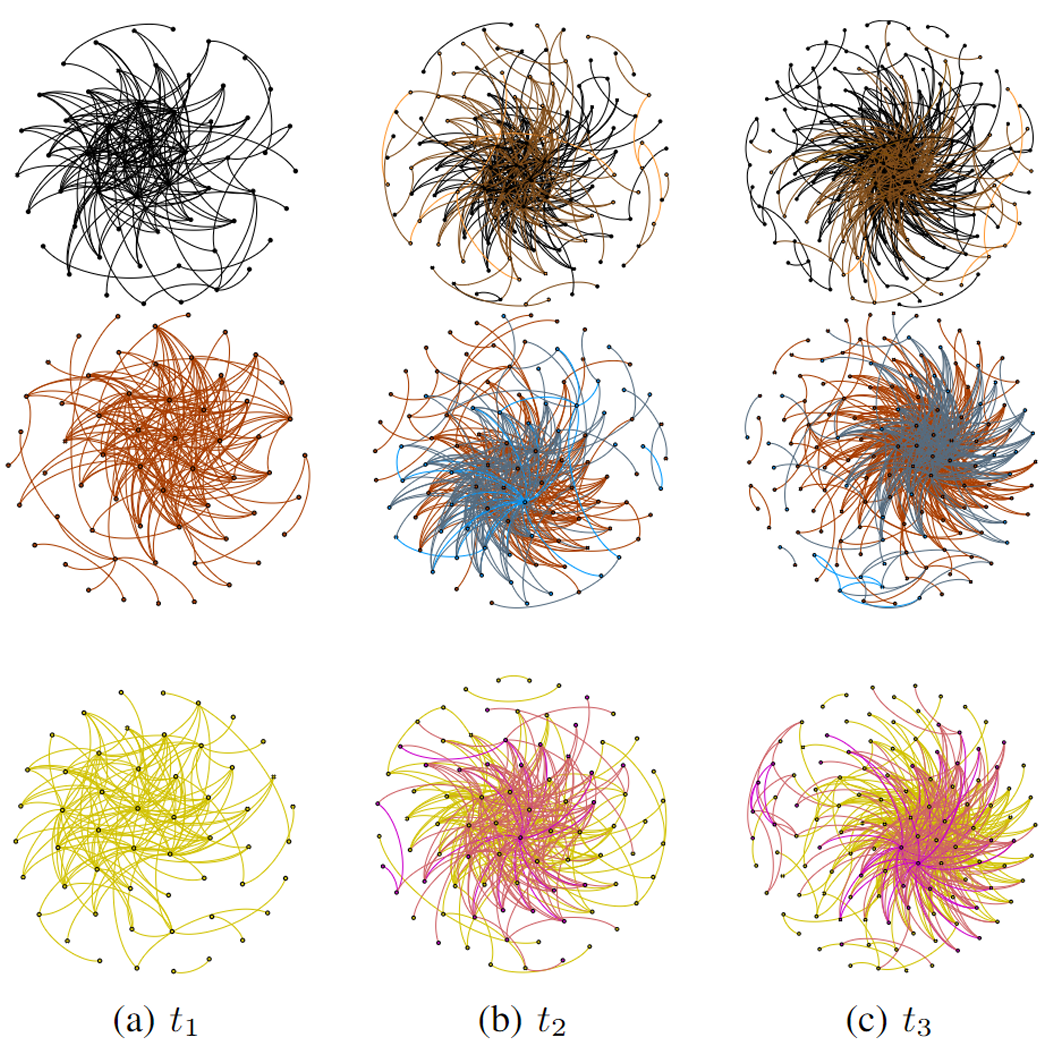
这张图展示了使用Fruchterman-Reingold布局方法,对时间间隔t1、t2和t3中横向移动(LM)攻击的增强威胁数据集进行可视化。图中分为三行,每行代表一个不同的攻击场景:
- 第一行(a, b, c):场景1
- 第二行(a, b, c):场景2
- 第三行(a, b, c):场景3
Fruchterman-Reingold布局解释
Fruchterman-Reingold布局是一种图形布局算法,用于美观地排列图中的节点和边。这种算法试图将有连接的节点彼此靠近,同时将无连接的节点彼此远离,使整个图看起来更均衡和清晰。该算法使用物理学的弹簧模型,其中节点之间既有排斥力(类似于带电粒子间的斥力)也有吸引力(类似于连接节点之间的弹簧力)
图中不同颜色的节点意义
图中不同颜色的节点用于表示不同时间点的状态变化。例如:
- 在t2时刻,与t1时刻相比,新变色的节点代表新受到攻击或妥协的节点。
- 同理,在t3时刻,与t2时刻相比,新变色的节点继续表示从上一时刻开始新受到攻击或妥协的节点。
这种颜色的变化帮助观察者理解随时间变化网络安全状况的动态变化,特别是观察攻击者是如何逐渐在网络中扩散影响的。
图的解释
- t1时刻:初始攻击状态,少量节点开始显示为受攻击状态。
- t2时刻:攻击扩展,更多的节点变色,显示攻击已经从初始节点扩散到更多节点。
- t3时刻:进一步的扩散,更多新节点被攻击影响,展示了攻击者在网络中进一步扩展其控制范围。
图表11:消融实验
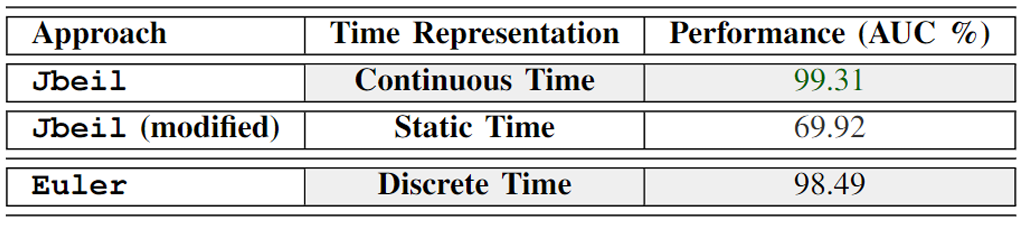
- Jbeil (Continuous Time): 在连续时间表示下,Jbeil的AUC性能为99.31%。这显示了Jbeil利用连续时间动态图的强大能力,有效捕捉时间变化对边的影响,从而高效检测横向移动(LM)。
- Jbeil (modified) (Static Time): 修改后的Jbeil,使用静态时间表示,其AUC性能显著下降到 69.92%。这表明在没有考虑时间动态性的情况下,模型的效果大幅度减弱,说明时间因素在Jbeil模型中扮演着关键角色。
- Euler (Discrete Time): Euler使用离散时间表示,其AUC为98.49%。虽然表现优于静态时间,但仍然低于Jbeil的连续时间表示。这强调了连续时间表示相较于离散时间表示在捕捉动态网络变化上 的优势。
什么是消融实验?
消融实验(Ablation Study)是一种在机器学习和数据科学研究中常用的实验方法,目的是系统地移除或修改模型的某个部分(如功能、组件、或数据输入),以确定这些部分对模型整体性能的影响。通过对比原始模型和修改后模型的表现,研究者可以了解不同组件对模型预测能力的贡献度。这有助于优化模型,理解模型的关键部分,以及验证模型设计的健壮性。]
连续时间、静态时间、离散时间的区别?
- 连续时间(Continuous Time):
- 连续时间表示法在模型中使用真实的时间戳来表示事件发生的具体时刻。这种表示可以捕捉到事件之间的确切时间间隔,允许模型理解时间上的微小变化,从而更精确地模拟现实世界的动态。
- 在图表中,连续时间表示因其能精确捕捉时间的连续变化而显示出更高的性能。
- 静态时间(Static Time):
- 静态时间模型通常不考虑时间的流逝对数据的影响。在这种模型中,数据被视为在一个固定时间点收集的快照,或者完全忽略时间的变化。例如,在静态时间模型中,如果你正在分析一个社交网络的连接模式,你可能只关心是否存在连接,而不关心连接发生的具体时间。
- 静态时间不用于分析事件之间的时间关系,因此,这种方法适用于那些时间顺序不是特别重要的场景。
- 离散时间(Discrete Time):
- 离散时间模型将时间轴分割为有限的、离散的间隔或阶段,每个事件都映射到这些时间段中。例如,在离散时间模型中,一个月的数据可能被划分为每天、每周或每月的时间段。
- 这种方法仍然考虑时间的流逝和时间顺序,只是简化了时间的表示,使其更易于处理和分析。在处理涉及时间序列的数据时,这种方法允许研究者观察和分析时间变化和周期性行为。
结论
这个比较明显展示了连续时间表示在处理具有时间动态的图数据时,尤其是在网络安全和横向移动检测场景中,提供了显著的优势。Jbeil在连续时间模式下的表现超越了其他时间处理方法,验证了其在实际网络环境中应用的潜力和效果。
八、传导推理和归纳推理区别
示例背景
假设有一个社交网络,我们的目标是预测哪些用户之间可能会形成新的友谊连接。我们有全部用户的列表和他们目前的连接状态。
传导评估
在传导推理中,我们可能已经收集了整个社交网络的数据,包括所有用户及其部分连接信息。我们选择一部分用户和他们的连接作为训练数据来训练模型,而其他部分用户和连接虽然不用于训练,但模型在训练时已经“知道”这些用户存在,只是没有他们的连接信息。
例子:让我们假设Alice, Bob, 和Carol是社交网络上的用户。我们在训练模型时使用了Alice和Bob的数据,但没有使用Carol的数据。在传导评估中,我们尝试使用模型来预测Carol与Alice和Bob之间可能形成的连接,尽管在训练模型时Carol的数据没有被使用,但模型在处理整个数据集时已经知道了Carol的存在。
归纳推理
与此相对,归纳推理不要求模型在训练时知道所有可能的测试实例。模型的目标是能够泛化到完全新的、未曾见过的用户上。
例子:继续使用上面的社交网络例子,假设我们还有一个完全新的用户Dave,他在训练模型时完全未知,也就是说,在收集训练数据时Dave还不是网络的一部分。在归纳推理中,我们的目标是使用训练好的模型来预测Dave与其他用户(包括Alice, Bob, 和Carol)之间可能形成的新连接。这种情况下,模型需要能够处理之前从未见过的新情况,展示出真正的泛化能力。
结论
总结来说,传导评估关注的是如何利用已有的、在数据集中已知但未用于直接训练的数据进行预测, 而归纳推理则需要模型能够有效地处理全新的、训练时未曾见过的数据。在真实世界的应用中,归纳推理的需求更广泛,因为它更接近于模型在现实环境中遇到全新情况时的应用场景。
九、原文重点阅读
For modeling and detecting LM behaviors in evolving enterprise networks, we first introduce a pre-processing pipeline for generating a graph structure (derived from the information found in benign and threat augmented authentication logs) by extracting graph maps and calculating graph features. We then discuss Jbeil, our proposed temporal graph-based self-supervised inductive learning technique for detecting LM paths. We make Jbeil open source on GitHub [42].
为了在不断发展的企业网络中建模和检测 LM 行为,我们首先引入了一个预处理管道,通过提取图映射并计算图特征来生成图结构(源自良性和威胁增强认证日志中发现的信息)。然后我们讨论 Jbeil,我们提出的基于时间图的自监督归纳学习技术来检测 LM 路径。
我们在 GitHub [42] 上制作 Jbeil 开源。
3.1 Pre-processing Pipeline
3.1 预处理管道
3.1.1 Threat Sample Augmentation
3.1.1 威胁样本增强
Devising a pragmatic LM detection approach necessitates well-informed notions on recent attack scenarios and tactics. It is also crucial to remediate the sample bias challenge faced in machine learning techniques [38]. However, acquiring realworld LM attack data is known to be extremely difficult [25], [36], [38]. For such reasons, we embed a threat sample augmentation procedure within the pre-processing pipeline of Jbeil based on the attack synthesis framework established by Ho et al. [25]. The algorithm used for that purpose is rooted in the breadth-first search (BFS) graph traversal algorithm. Given any enterprise network architecture, we represent the network as a computational graph and utilize the BFS algorithm to parse all the network nodes; enabling the comprehension of the joint spatial, contextual, and temporal topology of the network. This step is important for enabling tailored threat sample augmentation which adheres to the nature and characteristics of the network. The augmentation is performed in two stages. First, random nodes are selected as footholds to initiate the attacks. Second, LM logins are executed by identifying the shortest path to privileged credentials that can access a high-value asset and then the shortest path to the high-value asset using these new credentials. More details on this augmentation scheme, its related generated datasets and experimentation is provided in 4.2.2 and 4.4.2, respectively.
开发实用的 LM 检测方法需要对最近的攻击场景和策略有充分信息的概念。修复机器学习技术[38]所面临的样本偏差挑战也是至关重要的。然而,众所周知,获取现实世界的 LM 攻击数据非常困难 [25]、[36]、[38]。因此,我们基于Ho等人[25]建立的攻击合成框架,在Jbeil的预处理管道中嵌入威胁样本增强过程。
用于此目的的算法植根于广度优先搜索 (BFS) 图遍历算法。**给定任何企业网络架构,我们将网络表示为计算图,并利用BFS算法解析所有网络节点;能够理解网络的联合空间、上下文和时间拓扑。**这一步对于启用符合网络性质和特征的定制威胁样本增强非常重要。增强分两个阶段执行。首先,选择随机节点作为立足点发起攻击。其次,LM logins 是通过将最短路径识别为可以访问高价值资产的特权凭证来执行的,然后使用这些新凭证将最短路径识别为高价值资产。有关此增强方案的更多详细信息,其相关生成数据集和实验分别在 4.2.2 和 4.4.2 中提供。
假设有一个公司的网络系统,这个系统可以被想象成一个由多个节点(比如服务器、电脑和其他设备)组成的图。在这个图中,节点之间通过连接线(网络连接)相互联系。
威胁样本增强的两个阶段:
- 选择立足点:
- 首先,我们随机选择一些节点作为攻击的起点。比如,我们可能随机选择一个办公室的电脑作为开始模拟攻击的节点。
- 执行攻击:
- 接下来,我们模拟攻击者尝试获取访问高价值资产的权限。首先,模拟攻击会寻找到一个最短的路径,去获取可以访问公司重要服务器的特权账户。
- 获取到特权账户后,攻击者会尝试找到从当前位置到达高价值资产(比如财务数据存储服务器)的最短路径。
- 在这个过程中,系统会模拟攻击者如何一步步通过网络向目标前进,从而检测并增强系统对这种攻击路径的防御能力。
通过这种方式,即使在没有真实攻击数据的情况下,我们也可以生成具有代表性的攻击样本,用于训练和测试网络安全系统,从而提高系统对实际攻击的识别和防御能力。
问学长:
那他这个样本增强其实就是自己模拟出了一些攻击数据?
是
3.1.2 Graph Building and Graph Feature Extraction.
3.1.2 图构建和图特征提取
Apart from attributes gathered from commonly recorded authentication logs, additional features pertaining to the connectivity dynamics of the network entities are not available. Additionally, the proposed model requires a good graph representation of the network coupled with an effective encoding of its hosts' connectivity. To this end, we make use of host authentication logs to scrutinize the necessary graph features that represent the dynamic nature of the enterprise network as well as the connectivity properties of its hosts and users. The generated graph features are primarily based on the in-degrees and out-degrees of the different hosts and users which are used to support Jbeil's message-passing mechanism among the neighboring hosts. We note that Jbeil by default incorporates host-only interaction information; however, additional interaction information pertained to users connectivity is equally needed during the learning phase. To calculate the graph features induced by the different graph interactions (i.e., host-tohost, user-to-host, host-to-user, user-to-user), we follow the approach proposed in [55], [66] to extract the graph map and subsequently calculate the graph features. Figure 4 illustrates the pre-processing pipeline that we follow to extract the graph features and build the graph representations.
除了通常记录的身份验证日志中收集的属性外,无法获得与网络实体连通性动态相关的附加特征。**此外,所提出的模型需要良好的网络图形表示,以及
对其主机连通性的有效编码。**为此,我们利用主机身份验证日志来仔细检查代表企业网络动态性质的必要图特征及其主机和用户的连通性属性。生成的图特征主要基于不同主机和用户的入度和出度,用于支持 Jbeil 在相邻主机之间的消息传递机制。我们注意到 Jbeil 默认包含仅主机的交互信息;然而,在训练阶段同样需要与用户连通性相关的额外交互信息。为了计算不同图交互(即主机到主机、用户到主机、主机到用户、用户到用户)诱导的图特征,我们遵循[55]、[66]中提出的方法提取图映射,然后计算图特征。图 4 说明了我们提取图特征并构建图表示的预处理管道。
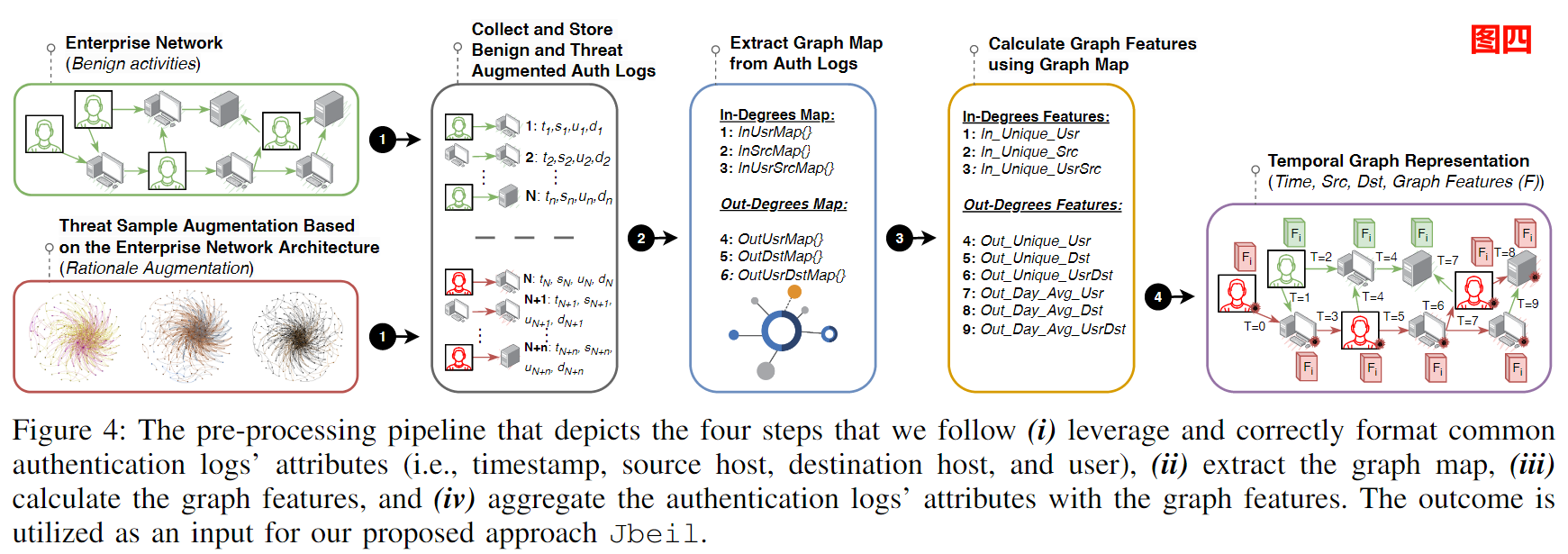
图4:展示了我们遵循的四个步骤的预处理管道(i)利用并正确格式化常见的认证日志属性(即时间戳、源主机、目的地主机和用户),(ii)提取图表,(iii)计算图表特征,(iv)将认证日志属性与图表特征合并。最终结果作为我们提出的方法Jbeil的输入。
In summary, in step 1️⃣, we make use of attributes found in commonly collected authentication logs (and autentication logs associated with our augmented threat sample, see §3.1.1). In step 2️⃣, we extract the graph maps representing different interactions within the network. In step 3️⃣ , we generate new graph features based on the previously extracted graph maps. Finally, in step 4️⃣ , we derive a temporal graph representation capturing time-stamped authentication events among the various nodes and the newly generated graph features. A thorough description of these four distinct steps is presented in the sequel.
总之,在步骤1️⃣中,我们利用在常见认证日志中发现的属性(以及与我们扩展的威胁样本相关的认证日志,见第3.1.1节)。在步骤2️⃣中,我们提取表示网络中不同交互的图表。在步骤3️⃣中,我们基于先前提取的图表生成新的图表特征。最后,在步骤4️⃣中,我们生成一个基于时间戳的图表表示,捕捉网络中各个节点之间的时间戳认证事件以及新生成的图表特征。关于这四个不同的步骤的详细描述将在后续部分中给出。
We initially utilize attributes found in commonly collected authentication logs. Such attributes include timestamp t, source host src, targeted userusr, and destination host dst. This initial step is shown in Figure 4 step 1️⃣. In step 2️⃣ of the pre-processing pipeline, we leverage the previously mentioned authentication log attributes to generate a graph map (i.e., a set of dictionaries) to represent the connectivity between each host and user within the network. We note that calculating the graph maps is essential to preserve users' interaction information since the targeted user attribute usr is omitted in the final graph representation.
图表映射提取。
我们首先利用在通常收集的认证日志中发现的属性。这些属性包括时间戳t、源主机src、目标用户usr和目的地主机dst。这一初始步骤如图4步骤1️⃣所示。在预处理管道的步骤2️⃣中,我们利用前面提到的认证日志属性生成一个图表映射(即一组字典),以表示网络中每个主机和用户之间的连接性。我们注意到,
计算图表映射对于保存用户交互信息至关重要,因为目标用户属性usr在最终的图表表示中被省略。(这句话解释如下↙️)
想象一下你在一个学校里,有很多学生和教室。学生们会根据他们的课程表在不同的教室之间移动。如果我们想分析学生的移动模式,比如哪些学生经常一起上课,我们可能会记录下每个学生在哪个时间进入了哪个教室。
在这个例子中:
- 教室相当于网络中的计算机。
- 学生相当于网络中的用户。
但出于隐私考虑,我们不在图表中直接显示学生的名字,只显示教室之间的学生流动。即便如此,我们仍然可以通过创建一个图表,这个图表不直接显示每个学生的名字,而是显示每个教室被哪些学生编号访问过。
图映射在这里的作用是,即使我们不直接用学生名字来构建图表,我们仍然能够追踪哪个学生编号访问了哪个教室。例如,我们可以建立一个列表,记录教室A在第一节课由学生编号1, 3, 5访问,教室B由学生编号2, 4访问。通过这种方式,我们可以分析学生流动的模式,而不需要展示每个学生的具体信息。
这样,即使学生的名字在最终的网络图中被省略,通过这种“图映射”的方式,学生(用户)之间的交互信息仍然被有效地保留和利用,帮助我们理解和分析学生的行动模式。这对于理解网络安全动态同样适用,只不过在网络安全的场景中,我们关注的是数据流和访问权限,而不是学生和教室。
After obtaining this initial representation, we extract six different dictionaries, namely: (i) in-degree dictionaries, which map the number of incoming authentication events recorded at each host per usr,src, and (usr,src) combination per day (i.e., InUsrMap, InSrcMap, InUsrSrcMap), and (ii) out-degree dictionaries, where the number of outgoing daily authentication events recorded at each host per usr, dst, and (usr,dst) combination are mapped (i.e., OutUsrMap,OutDstMap,OutUsrDstMap). To calculate the daily interactions between nodes, we capture calendar dates from the epoch time t. Algorithm 1 presents the InDegrees function to calculate the in-degrees graph map dictionaries, namely, InUsrMap,InSrcMap, and InUsrSrcMap. Specifically, InDegrees() takes as arguments an empty dictionary and its corresponding target x which can be the source Src, the user Usr, and the combination of both Src\_Usr. Computing the dictionaries of the outdegrees graph maps, namely, OutUsrMap,OutDstMap, OutUsrDstMap follows the same approach, **but with a small difference where the graph maps at hand should be associated with a source node rather than a destination node.**The implementations of the graph maps are found on GitHub [42].
在获取了这个初始表示之后,我们提取了六个不同的字典,分别是:(i)
入度字典,它映射每个主机每天记录的来自每个用户、来源和用户与来源组合的传入认证事件数量(即InUsrMap、InSrcMap、InUsrSrcMap);以及(ii)出度字典,其中映射每个主机每天记录的向每个用户、目的地和用户与目的地组合的传出认证事件数量(即OutUsrMap、OutDstMap、OutUsrDstMap)。为了计算节点间的日常互动,我们从epoch时间t捕捉日历日期。算法1展示了用于计算入度图表字典的InDegrees函数,具体为InUsrMap、InSrcMap和InUsrSrcMap。具体来说,InDegrees()接受一个空字典及其对应的目标x作为参数,x可以是源Src、用户Usr或者它们的组合SrcUsr。出度图表字典的计算,即OutUsrMap、OutDstMap和OutUsrDstMap,也采用相同的方法,但有一个小差别,即手头的图表应该与源节点而非目的节点关联。这些图表的实现可在GitHub上找到。

- 初始化:该算法需要一个空字典
GraphMap和一个目标参数x。这里的x可以是来源(Src)、用户(Usr)或它们的组合(Src, Usr)。- 遍历认证日志:对于日志中的每条记录,包含时间戳
ts、源Src、用户Usr和目的地Dst。- 构建图映射:
- 目的地检查:如果目的地
Dst不在GraphMap中,则为其创建一个新的空字典。- 用户/源检查:如果在
GraphMap[Dst]中没有对应x的记录,则在GraphMap[Dst]中为x创建一个新的空字典。- 日期计算:使用时间戳
ts来计算对应的天数,这里通过将ts除以 86,400(一天的秒数)得到。- 天数检查:如果所计算的天数不在
GraphMap[Dst][x]中,则在GraphMap[Dst][x]中为该天数创建一个新条目,并初始化为 0。- 增加计数:将
GraphMap[Dst][x][day]的值加一,表示在这一天,该目的地通过x接收到一个新的认证请求。- 返回图映射:在遍历所有日志记录后,返回完成的
GraphMap。此算法通过构建两组字典(内度和外度字典)来反映每天在每个主机上记录的认证事件数量。内度字典(如
InUsrMap,InSrcMap,InUsrSrcMap)跟踪每个主机每天接收到的认证请求数量,而外度字典(如OutUsrMap,OutDstMap,OutUsrDstMap)则跟踪每个主机每天发送的认证请求数量。
问学长:
输入为什么可以是单个,也可以是组合?跟前面图表中的疑问类似
In step 3️⃣ of the pipeline, we calculate the graph features using the previously generated dictionaries, which now serve as a graph map representing all interactions within the network. The calculation of the graph features is conducted as follows:
图特征计算。
在管道的第三步中,我们使用之前生成的字典来计算图特征,这些字典现在作为代表网络内所有互动的图映射。图特征的计算过程如下:
First, we calculate the number of hosts, users, and host-user combinations targeting a specific host using the graph map dictionaries. Particularly, we iterate over all the authentication events to calculate (i) the number of users, hosts, and user-host combinations per destination host (i.e., In Unique_Usr, In Unique_Src, and In Unique_UsrSrc), and (ii) the number of users, hosts, and user-host combination per source host (i.e., Out Unique_Usr, Out Unique_Dst, and Out_Unique_UsrDst). Contextually, amid LM, numerous authentication events with ranging frequencies are used by threat actors to propagate within an enterprise network and compromise additional assets. As such, these authentication events may conclude with successful or failed attempts. In either case, such activity will result in an increased number of involved hosts, users, and host-user combinations targeting or being targeted by a specific host. Thus, the newly generated features will append important semantics associated with the connectivity dynamics among hosts and users.
首先,我们
使用图映射字典计算针对特定主机的主机、用户和主机-用户组合的数量。具体来说,我们遍历所有认证事件来计算(i)每个目的主机的用户、主机和用户-主机组合的数量(即In Unique_Usr、In Unique_Src和In Unique_UsrSrc),以及(ii)每个源主机的用户、主机和用户-主机组合的数量(即Out_Unique_Usr、Out_Unique_Dst和Out_Unique_UsrDst)。在LM的背景下,威胁行为者使用频率不等的众多认证事件在企业网络内传播并侵占额外资产。这些认证事件可能以成功或失败告终。无论哪种情况,此类活动都将导致针对特定主机或被特定主机针对的主机、用户和主机-用户组合的数量增加。因此,新生成的特征将添加与主机和用户之间的连接动态相关的重要语义。
Second, we calculate the daily frequencies of outdegrees pertaining to each host. In essence, we loop over all the authentication events and calculate the daily average interactions of each user, host, and user-host interactions associated with the source host (i.e., Out_Day_Avg_Usr, Out _Day_Avg_Dst, and Out_Day_Avg_UsrDst).
其次,我们计算每个主机的出度日频率。本质上,我们遍历所有认证事件,计算与源主机关联的每个用户、主机以及用户-主机互动的
日均交互次数(即Out_Day_Avg_Usr、Out_Day_Avg_Dst和Out_Day_Avg_UsrDst)。
To summarize, calculating these aforementioned features adds valuable semantic meaning to each node as each feature provides additional insights into the node's dynamic behavior while preserving key information associated with users' connectivity dynamics within a network. We highlight in §3.2 the importance of these features in computing the nodes' temporal memories and embeddings.
总结来说,计算这些前述特征为每个节点添加了宝贵的语义意义,因为每个特征都提供了关于节点动态行为的额外洞见,同时保留了与网络中用户连接动态相关的关键信息。我们在§3.2中强调了这些特征在计算节点的时间记忆和嵌入中的重要性。
At step 4️⃣ of Figure 4, we combine the previously formatted authentication logs from step 1️⃣ with the calculated features at step 3️⃣ , as well as, the label of the authentication event (i.e., malicious or benign) to produce the final graph representation. That said, the graph G will be defined asG = {et0, et1, et3, ...}, where e represents an authentication event at time t. Each event e comprises the timestamp value of the authentication event t, the source host src, the destination host dst, the label of the event l, and the graph features of source and destination, vsrc and vdst, respectively. Herein, an event e is defined as follows:e = {t, src, dst, l, vsrc, vdst}.
时间图结构表示。
在图4的第4️⃣步中,我们将第1️⃣步中格式化的认证日志与第3️⃣步计算的特征以及认证事件的标签(即,恶意或良性)结合起来,生成最终的图表示。也就是说,图G将被定义为G = {et0, et1, et3, ...},其中e代表时间t的认证事件。每个事件e包括认证事件的时间戳值t、源主机src、目的主机dst、事件的标签l,以及源和目的地的图特征vsrc和vdst。在这里,一个事件e被定义为:e = {t, src, dst, l, vsrc, vdst}。
3.2 Jbeil: Temporal Graph-Based Inductive Learning to Infer LM
3.2 Jbeil:基于时间图的归纳学习推断LM
We propose in this work Jbeil, a temporal graph-based inductive learning approach rooted in Temporal Graph Networks (TGN) [67] to deal with dynamic graphs represented as sequences of timed authentication events within enterprise networks. Dynamic graphs are primarily characterized by their evolving features and connectivity across time. As previously motivated, enterprise networks are indeed evolving in nature and comprises active nodes consisting of hosts, users, virtualized environments, and applications that are continuously and/or recurrently exchanging authentication events. Coextendingly, threat actors infiltrate and propagate within dynamic enterprise networks to compromise targeted nodes while evading conventional detection techniques. To this end, Jbeil uniquely supports continuous-time dynamic graphs represented as a sequence of time-stamped authentication events to calculate the temporal embedding of graph nodes, thereby learning from both temporal and topological data.
在这项工作中,我们提出了Jbeil,这是一种植根于时间图网络(TGN)[67]的时序图基归纳学习方法,用于处理企业网络内以时间认证事件序列表示的动态图。动态图主要通过它们随时间演变的特征和连通性来表征。如前所述,企业网络本质上是在演变的,包括不断交换认证事件的主机、用户、虚拟化环境和应用程序等活跃节点。此外,威胁行为者渗透并在动态企业网络中传播,以侵害目标节点,同时规避常规的检测技术。为此,Jbeil独特地支持以时间戳记认证事件序列表示的连续时间动态图,通过计算图节点的时间嵌入,从而从时间和拓扑数据中学习。
3.2.1 Temporal node memory
3.2.1 时间节点记忆
LM attacks are persistent by nature and remain undetected for an extensive period of time. To this extent, we utilize the memory module ofJbeil to retain long-term dependencies for each node in the graph. For every interaction event occurring at time t, we calculate the memory m of each participating interaction node. The calculated memory represents the history of interactions for each node, which is computed every time the node participates in an interaction event. Originally, at t=0 all the memories are initialized with the node features (recall §3.1.2). For instance, consider Figure 5 which illustrates at 1️⃣ an interaction event at time t where node i is the destination node and nodes j, k, l and o are the source nodes. We note that node o has been previously compromised, which means that its memory at t − 1 already encompasses information that reflects this situation. As such, the newly calculated memory of node i shown at 2️⃣ will in fact be affected by all its neighboring nodes, including node o. In any interaction event at time t, the memory of the source node and the destination node are calculated using Equations 1 and 2, respectively.
LM攻击的特点是持久性强,往往长时间未被发现。在这方面,我们利用Jbeil的记忆模块来保留图中每个节点的长期依赖关系。每次在时间t发生互动事件时,我们计算每个参与互动节点的记忆m。计算出的记忆代表每个节点的互动历史,每当节点参与一个互动事件时,都会计算一次。最初,在t=0时,所有记忆都用节点特征初始化(参见§3.1.2)。例如,考虑图5,在步骤1️⃣中,时间t展示了一个互动事件,其中节点i是目的节点,而节点j、k、l和o是源节点。我们注意到节点o之前已被攻破,这意味着它在t-1的记忆已经包含了反映这种情况的信息。因此,如步骤2️⃣所示,节点i新计算的记忆实际上会受到包括节点o在内的所有邻近节点的影响。在时间t的任何互动事件中,源节点和目的节点的记忆都分别使用方程1和方程2计算。
In this work, we use the msg() function as a simple concatenation of the inputs. Additionally, msg() is a learnable function using a recurrent neural network (i.e., Gated Recurrent Unit GRU [68]) and is updated for every event occurring at time t and involving two nodes. To recapitulate, utilizing the memory module in Jbeil is important for learning within dynamic enterprise networks due to its ability to store and act-upon long-term information (i.e., a history of interactions) about a node, which is crucial when addressing the LM problem.
在这项工作中,我们使用msg()函数作为输入的简单串联。此外,msg()是一个可学习的函数,使用递归神经网络(即门控循环单元GRU [68])实现,并且每当时间t发生涉及两个节点的事件时进行更新。总结一下,由于Jbeil的记忆模块能够存储并处理关于节点的长期信息(即互动历史),这在解决LM问题时至关重要,因此在动态企业网络中学习时利用记忆模块非常重要。
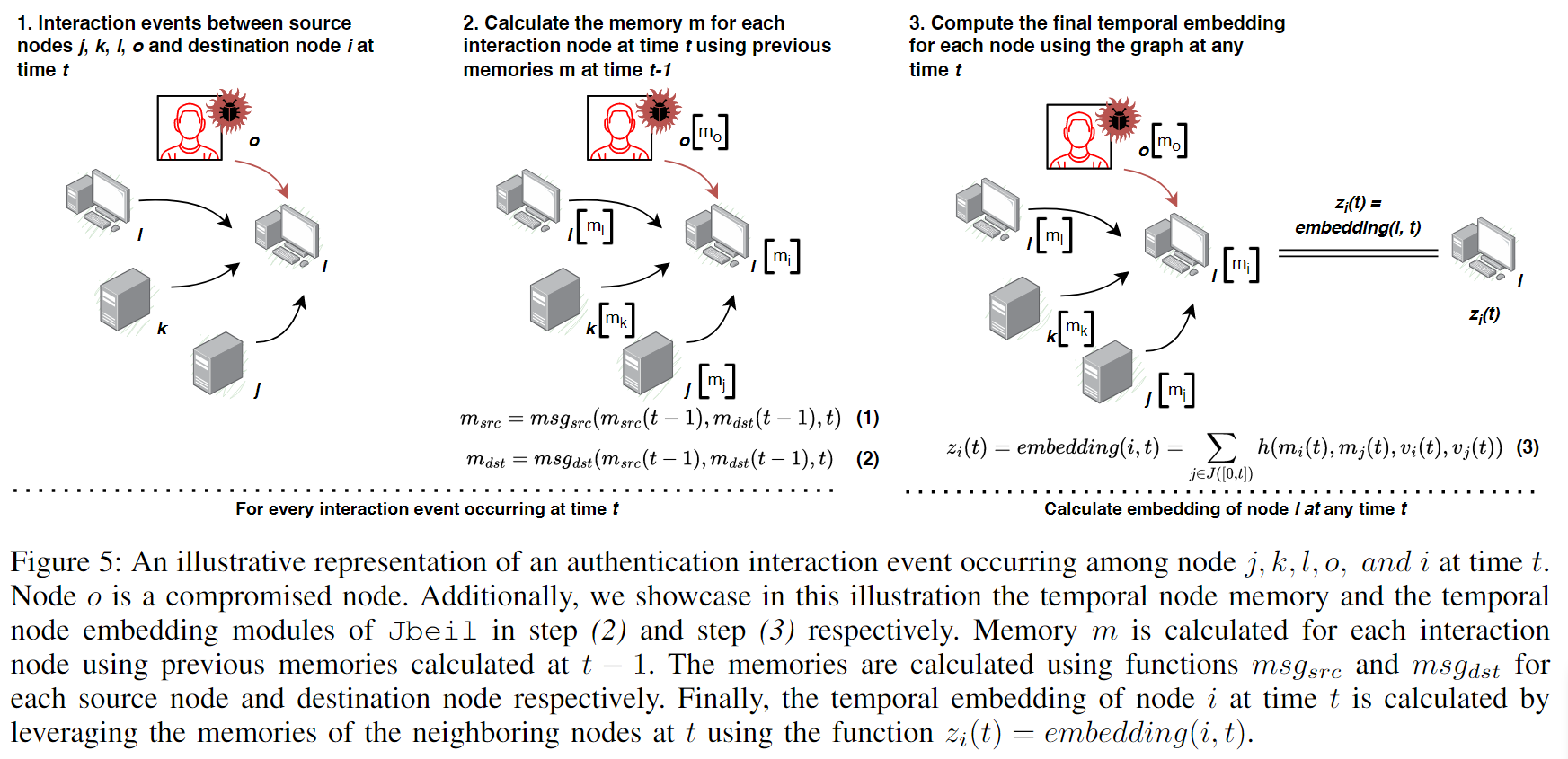
图5:在时间t,节点j、k、l、o和i之间发生的认证互动事件的示意图。节点o是一个被攻破的节点。此外,我们在这个示意图中分别在步骤(2)和步骤(3)展示了Jbeil的时间节点记忆和时间节点嵌入模块。使用在t-1时刻计算出的之前记忆,为每个互动节点计算记忆m。使用函数msgsrc和msgdst分别为每个源节点和目的节点计算记忆。最后,通过利用t时刻邻近节点的记忆,使用函数zi(t) = embedding(i, t)计算节点i在时间t的时间嵌入。
3.2.2 Temporal node embedding, inference, and training
3.2.2 时间节点嵌入、推理和训练
Subsequently, we utilize the embedding module ofJbeil to calculate the temporal embedding of node i for each time t by aggregating the temporal node memory of all neighboring nodes coupled with its own previously calculated graph features (recall §3.1.2). For example, step 3️⃣ of Figure 5 presents the computation of the final temporal embedding of node i at time t using Equation 3.
随后,我们使用Jbeil的
嵌入模块来计算节点i在每个时间t的时间嵌入,通过聚合所有邻近节点的时间节点记忆以及其自身之前计算的图特征(参见§3.1.2)。例如,图5的第3️⃣步展示了使用方程3在时间t计算节点i的最终时间嵌入的过程。
We note that h() is a learnable function which may include different formulations such as a simple identity function which uses the memory as a node embedding or an attention function (attention is used in Jbeil to ensure adequate visibility) which aggregates information from L-hop temporal neighborhoods [67]. s(t) and v(t)represent the current node memory and the node feature vector, respectively. As such, calculating the temporal node embedding of i, zi(t) involves all its temporal neighboring nodes j ∈ J. Computing a node's temporal embedding can solve the staleness problem caused by inactivity, which occurs when a node no longer updates its memory, causing it to become stagnant. This problem occurs when a process remains dormant for a long time or when a user is idle for an extended period. Temporal embedding can mitigate this issue since it depends heavily on the memory and features of neighboring nodes. Finally, after mapping the continuoustime dynamic graph into node embeddings, we leverageJbeil's decoder which takes one or more node embeddings and perform link prediction by providing the probability of an authentication event (path/edge).
我们注意到,
h() 是一个可学习的函数,可能包括不同的公式,如一个简单的身份函数,它使用记忆作为节点嵌入,或者一个注意力函数(Jbeil中使用的注意力以确保足够的可见性),它从L跳时序邻域聚合信息[67]。s(t) 和 v(t) 分别代表当前节点的记忆和节点特征向量。因此,计算节点i的时间节点嵌入 zi(t) 涉及到所有它的时序邻近节点 j ∈ J。计算节点的时间嵌入可以解决由不活跃引起的陈旧性问题,这个问题发生在节点不再更新其记忆时,导致其变得停滞不前。这个问题可能发生在一个过程长时间处于休眠状态或者用户长时间处于闲置状态时。时间嵌入可以缓解这个问题,因为它在很大程度上依赖于邻近节点的记忆和特征。最后,在将连续时间动态图映射成节点嵌入后,我们利用Jbeil的解码器,它接受一个或多个节点嵌入,并通过提供认证事件(路径/边)的概率来执行链接预测。
问学长:
1.这个式子跟图片中的式子的区别?
2.Jbeil的解码器其实类似于一个二分类器吧?
Jbeil is trained using a self-supervised approach (i.e., self-supervised link prediction) to detect LM activities using temporal and topological data of both benign and malicious authentication events. In contrast to learning just from normal data (as implemented in state-of-the-art), which limits the inference of novel LM attack scenarios (as demonstrated in §4.2.2), Jbeil possesses the unique capability to successfully capture such scenarios using the augmentation method previously discussed (see §3.1.1).
Jbeil采用自监督方法(即自监督链接预测)进行训练,使用良性和恶意认证事件的时序和拓扑数据来检测LM活动。与仅从正常数据中学习(如现有技术中实现的)不同,这限制了对新型LM攻击场景的推断(如§4.2.2所示),Jbeil具有独特的能力,可以成功捕捉这些场景,使用先前讨论的增强方法(见§3.1.1)
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝